
[Article 1/2] Des modèles de langage aux modèles de monde
Rédigé par Régis Chatellier
-
25 mars 2026Dans le prolongement des modèles de langage, des chercheurs et entrepreneurs se sont lancés dans la conception et le développement de « modèles de mondes » (World Models), dont l’objectif est de « comprendre le monde physique », voire de « prédire le futur ».
Un grand modèle de langage (LLM) simule le mot (word) suivant dans le langage humain […]. Que feriez-vous si vous pouviez simuler parfaitement le monde (world) suivant, c'est-à-dire tous les futurs possibles dans l'environnement dans lequel nous vivons ?
Les modèles de langage ont déferlé sur le monde en seulement quelques années, transformant la manière dont les personnes, dans leur vie personnelle ou professionnelle, accèdent à des connaissances et recourent à différentes formes d’assistance par des outils dont l’appropriation a été plus rapide que celle des smartphones. Selon le baromètre du numérique 2026, en moins de 3 ans, en France, l’IA générative est déjà entrée dans les usages quotidiens d’un tiers des utilisateurs, 51% parmi les 18-24 ans. Mais déjà, d’autres types de modèles font l’objet de recherches et d’investissements dans la communauté de l’intelligence artificielle. Il s’agit désormais de dépasser les « modèles de langage » pour aller vers des « modèles de monde », ou « World Models ». Dans cet article, nous reprendrons ces deux formes, World Models restant le terme le plus utilisé.
Les grands modèles de langage (Large Language Models ou LLM) ont permis aux machines de manipuler le langage naturel après avoir été entrainé sur les symboles, les signes et représentations du monde produits à l’écrit ou dans le langage par les humains. Ces LLM ont cependant une limite, « ils vivent dans des symboles, et non dans l'espace et le temps », ils peuvent décrire comment conduire une voiture, assembler un robot, etc., mais ne maîtrisent pas l’appréhension du monde, la gravité, la friction, la causalité, etc. Ils n’ont du monde qu’une « connaissance encyclopédique ».
Si les premiers modèles datent de 2018, et les travaux menés chez Meta de 2021, l’année 2024 marque un tournant, quand des chercheurs alertent sur l’approche imminente des limites de la mise à l'échelle, ce qu’ils expliquent par « l'explosion des besoins énergétiques liés à l'informatique » d’une part, et par le fait que les développeurs de LLM sont à court de jeux de données conventionnels utilisés pour entraîner leurs modèles. 2024 est aussi l’année de l’arrivée sur le marché de grands modèles linguistiques multimodaux (LMM) - qui peuvent interpréter des données multimodales, qui comprennent non seulement du texte mais aussi des images, des sons et des vidéos) -, et des modèles de génération vidéo, tels que Sora. Les LMM démontrent leur capacité à saisir certains aspects de la connaissance du monde, qui semblent parfaitement respecter les lois physiques, mais des exemples viennent encore nous démontrer qu’ils raisonnent parfois de manière incohérente. Les World Models offrent la promesse de comprendre et intégrer les caractéristiques du monde physique.
La définition d'un modèle de monde fait cependant débat (Ding et al.), selon la perspective, qu’il s’agisse de « comprendre le monde » ou de « prédire l'avenir ». Les premiers travaux se sont focalisés sur l’abstraction du monde extérieur, physique, par l’acquisition d’une compréhension de ses mécanismes sous-jacents. La deuxième perspective, portée notamment par le chercheur en intelligence artificielle Yann Le Cun, vise non plus seulement à la modélisation du monde réel, mais aussi la capacité du modèle à envisager des états futurs possibles de celui-ci. Ce dernier a récemment quitté son poste de directeur de la recherche fondamentale en intelligence artificielle de Meta pour lancer sa propre startup, AMI (Advanced Machine Intelligence), à Paris, afin de se lancer dans la « troisième révolution de l’IA, celle des IA qui comprennent le monde réel, le monde physique », après « l’apprentissage profond il y a douze ans, puis l’avènement des chatbots comme ChatGPT ou Gemini, il y a trois ans » (Le Monde, janvier 2026).
Fei-Fei Li, autre figure emblématique de l’intelligence artificielle, co-fondatrice de World Labs en 2024, considère ces modèles de monde, et ce qu’elle nomme « l’intelligence spatiale », comme « la prochaine frontière de l’IA ». Professeure à Standford et figure incontournable du Deep Learning comme Yann Lecun, Fei-Fei Li est l’une des principales instigatrices de la base d’images ImageNet : dès 2006, alors que la plupart des chercheurs travaillaient à améliorer les modèles et les algorithmes, ImageNet visait à fournir aux chercheurs du monde entier des données d'images pour l'entraînement de modèles de reconnaissance d'objets à grande échelle. Elle considérait, dans un post publié en 2025, que « L'intelligence spatiale va transformer notre façon de créer et d'interagir avec les mondes réels et virtuels, révolutionnant ainsi la narration, la créativité, la robotique, les découvertes scientifiques et bien plus encore. Il s'agit de la prochaine frontière de l'IA. »
Pour mieux saisir ces nuances, nous proposons de revenir sur les différents types de modèles de monde et leurs applications, avant de nous focaliser sur la vision promue par Yann le Cun. Nous aborderons enfin les problématiques et enjeux spécifiques en termes de protection des données, d’éthique, et relatives au règlement européen sur l'intelligence artificielle.
Les différentes catégories de World Models
Les travaux récents sur la modélisation du monde ont donné naissance à une grande variété de systèmes, dont beaucoup sont optimisés pour un domaine ou un type de simulation spécifique. Il est intéressant de noter que ces systèmes ont néanmoins un point commun : ils accordent tous une importance considérable à la génération de vidéos/images et à la qualité visuelle des contenus générés :
- Les modèles de monde de jeux vidéo, par exemple Genie 2 (Google DeepMind) et Muse (Microsoft, Oasis, Decart and Etched), simulent des environnements de jeux vidéo à partir de modèles d’IA génératives. Ils ont la capacité à rendre plausibles des trajectoires à partir d'entrées visuelles et d'actions, produisant jusqu'à 1 à 2 minutes de contenu de jeu continu. Ils restent limités car ne permettent pas de représenter des parties complètes, qui peuvent durer des heures, et n’ont pas de capacité de raisonnement à « long terme ».
- Les modèles de monde 3D, comme Marble (World Labs), visent à produire des scènes et univers en 3D, du point de vue de la personne (egocentric navigation). Marble, disponible en version freemium et payante, permet aux utilisateurs de transformer des prompts textuelles, des photos, des vidéos, des mises en page 3D ou des panoramas en environnements 3D modifiables et téléchargeables. Bien que réalistes, ils se limitent à ce stade à des environnements statiques et non interactifs, ils ne prennent pas en charge la modélisation complète du monde pour la prise de décision ou l'apprentissage des agents.
- Les modèles génératifs de monde physique (ou modèle de fondation en monde ouvert), par exemple Wayve GAIA-2 et NVIDIA Cosmos, visent à générer des environnements synthétiques pour l’entrainement à des tâches de contrôle dans le monde physique, par exemple la conduite autonome, la robotique, la navigation. Ils sont basés sur une modélisation du monde physique qui prend en compte les conditions extérieures telles que les conditions météo, l’éclairage, la géographie, etc. Ils excellent dans un environnement contraint, pour des tâches spécifiques. Il ne s’agit pas là de modèle de monde « général », ils ne simulent pas des mondes complexes multi-agents.
- Les modèles de génération vidéo, par exemple Sora (OpenAI) ou Veo (Google DeepMind), visent à la génération de vidéo à usage général, des vidéos de haute qualité produites sur la base d’instructions (prompts) ou d’images déjà générées. Bien que le rendu soit très bon, il n’est pas possible de parler de modèle de monde, dès lors que les vidéos sont « fixes », et ne prennent pas en charge des interactions basées sur des actions alternatives, et ne fournissent aucun contrôle de simulation qui permettrait de raisonner sur des résultats contrefactuels ou d'évaluer différentes décisions. Sora, par exemple, exploite une combinaison d'architectures de réseaux neuronaux, afin de traiter des entrées multimodales et de générer des simulations visuellement cohérentes. Il est capable de générer des scènes visuellement réalistes, mais il peine à simuler avec précision certaines lois physiques du monde réel, telles que le comportement des objets soumis à différentes forces, la dynamique des fluides ou la représentation fidèle des interactions entre la lumière et les ombres. Il s’agit d’outils stricts de génération vidéo (axés sur la synthèse au niveau des pixels) plutôt que comme des éléments de systèmes décisionnels.
- Les modèles prédictifs à intégration conjointe (Joint Embedding Predictive Models), portés par Yann Le Cun, dont une série de modèles d’architecture a été conçue par Méta, notamment V-JEPA, adoptent un modèle différent de conception du monde. Il ne s’agit plus de modèles génératifs, comme nous le décrivons plus bas, mais de modèles qui cherchent à prédire et reproduire le « sens commun » propre aux êtres vivants (humains et non-humains). Comme nous décrivons plus bas, ces modèles se distinguent par leur ambition d’être « prédictif », en capacité de prévoir différents scénarios et/ou comportement des agents. C’est ce qui les différentient des modèles recensés plus haut.
Le modèle des « machines intelligentes autonomes »
Les World Models sont un champ de la recherche en IA qui propose un changement d’envergure et de paradigme par rapport au modèle de langage. L’idée derrière ces World Models est que les modèles de langage sont limités dans la représentation du monde qu’ils offrent. Dès lors qu’ils ne se basent que sur la production du langage et la manière dont les humains ont formulé dans des mots, ou des images, leur perception du monde, ils sont limités, selon Yann Le Cun.
La promesse de ces World Models consiste à obtenir des représentations du monde physique à l’aide de réseaux de neurones profonds, entraînés sur des données multimodales et dynamiques, qui en « comprennent » la dynamique, les propriétés physiques et spatiales. Les données requises pour leur entrainement ne sont plus seulement du texte, mais aussi des images, des vidéos et des mouvements pour générer des vidéos qui simulent des environnements physiques réalistes. Les LLM reproduisent le langage, les World Models cherchent à modéliser le monde physique.
Dans un « position paper » publié en juin 2022, A Path Towards Autonomous Machine Intelligence, Yann Le Cun décrit la manière dont les machines pourraient apprendre, raisonner, prévoir et agir à la manière des êtres vivants, humains et non-humains. Le document « propose une architecture et des paradigmes d’entrainement permettant de construire des agents intelligents autonomes. Il combine des concepts tels que le World Model (modèle de monde) prédictif configurable, le comportement guidé par la motivation intrinsèque et des JEPA (Joint Embedding Predictive Architecture), des architectures non génératives conçues pour construire des modèles du monde prédictifs, formées à l'aide de l'apprentissage auto-supervisé. »
Ces travaux se situent dans le prolongement de la cybernétique et du connexionnisme. La conception de ces nouveaux modèles de monde repose sur l’observation des êtres vivants, dont la capacité à apprendre et à comprendre le monde vont bien au-delà des capacités des systèmes d’IA et de machine learning actuels. Les êtres vivants sont capables d’acquérir, dès le plus jeune âge, d’énormes connaissances de bases sur le fonctionnement du monde, par l’observation et seulement avec un faible nombre d’interactions, sans supervision et indépendamment de toute tâche spécifique. Ces connaissances accumulées constituent la base, selon l’auteur, de ce que l'on appelle souvent le « sens commun » ou « bon sens », qui permet de « déterminer ce qui est probable, plausible ou impossible ». Ainsi les êtres vivants peuvent « prédire les conséquences de leurs actions, raisonner, planifier, explorer et imaginer de nouvelles solutions à des problèmes », ils sont en mesure d’éviter de se mettre dans des situations dangereuses lorsqu’ils sont confrontés à des situations inconnues, sans avoir à passer par une phase d’apprentissage, essai/erreur. Yann Le Cun prend l’exemple des véhicules autonomes : « un système de véhicules autonome peut nécessiter des milliers d'essais d'apprentissage par renforcement pour apprendre que rouler trop vite dans un virage aura des conséquences néfastes, et pour apprendre à ralentir afin d'éviter de déraper. En revanche, les humains peuvent s'appuyer sur leur connaissance approfondie de la physique intuitive pour prédire de tels résultats, et éviter dans une large mesure les erreurs fatales lorsqu'ils apprennent une nouvelle compétence. Le « bon sens » permet non seulement aux animaux de prédire les résultats futurs, mais aussi de combler les informations manquantes, que ce soit sur le plan temporel ou spatial. »
A partir de là, le chercheur soutient que « l'élaboration de paradigmes et d'architectures d'apprentissage qui permettraient aux machines d'apprendre des modèles de monde de manière non supervisée (ou auto-supervisée) et d'utiliser ces modèles pour prédire, raisonner et planifier est l'un des principaux défis de l'IA et du Machine Learning. Son hypothèse repose sur le fait que « les animaux et les humains ne disposent que d'un seul « moteur de modèle du monde » situé quelque part dans leur cortex préfrontal. Ce moteur de modèle du monde est configurable de manière dynamique en fonction de la tâche à accomplir ». Pour lui, « grâce à un moteur de modèle du monde unique et configurable, plutôt qu'à un modèle distinct pour chaque situation, les connaissances sur le fonctionnement du monde peuvent être partagées entre les différentes tâches. Cela peut permettre un raisonnement par analogie, en appliquant le modèle configuré pour une situation à une autre situation ».
Une architecture non générative qui s’inspire du cerveau
Reprenant l’analogie du fonctionnement du cerveau humain et de sa capacité à analyser de nombreuses données et d’informations perçues, afin de les traiter sur la base des représentations du monde déjà intégré dans son apprentissage, les « World Models » constituent les briques de ce qui serait selon lui une intelligence autonome, représentées dans l’illustration ci-dessous, et expliqué dans l’article A Path Towards Autonomous Machine Intelligence, page 6.
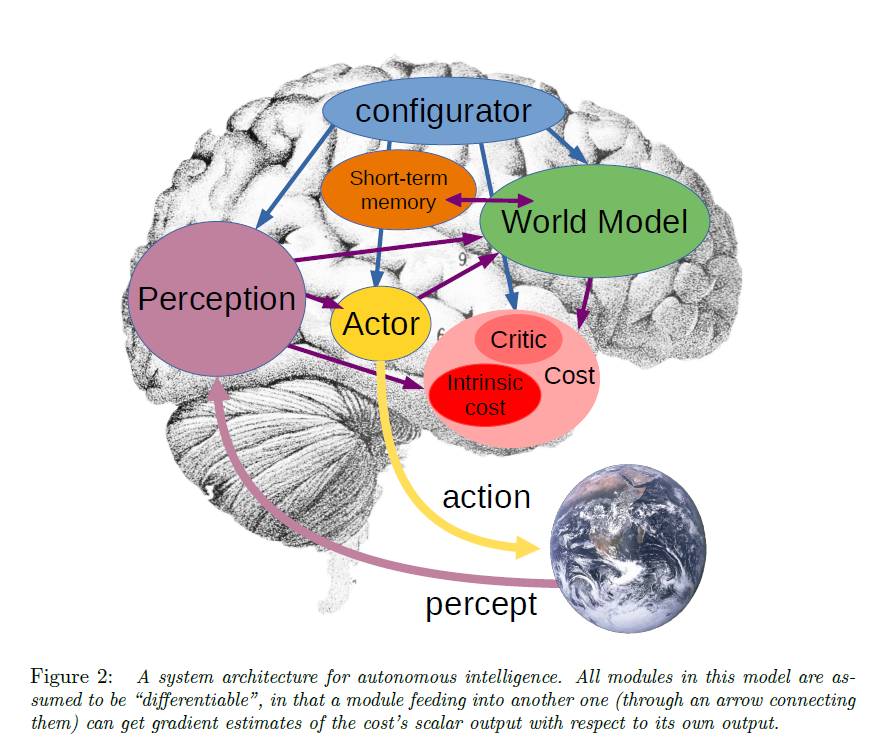
Illustration figurant dans l’article A Path Towards Autonomous Machine Intelligence
Dans cette architecture, le module modèle de monde (World Model) est le plus complexe. Son rôle est double :
- Estimer les informations manquantes sur l'état du monde qui ne sont pas fournies par la perception,
- Prédire les états futurs plausibles du monde : il peut s’agir des évolutions naturelles du monde, ou des états futurs plausibles du monde résultant d'une séquence d'actions proposées par le module acteur.
Le modèle de monde effectue ses prédictions dans un espace de représentation abstrait, qui contient des informations pertinentes pour la tâche à accomplir, idéalement, plusieurs niveaux d'abstraction. Cela lui permet d'ignorer les détails non pertinents ou imprévisibles (comme le mouvement des feuilles d'un arbre) pour se concentrer sur les informations nécessaires à la tâche. Le modèle de monde doit pouvoir représenter plusieurs avenirs possibles. Pour ce faire, il utilise des variables latentes qui paramètrent l'ensemble des prédictions plausibles. En faisant varier cette variable latente, le modèle peut générer différentes trajectoires d'états futurs pour une même action, et prendre en compte l’incertitude dans un contexte où des agents peuvent être hostiles, où des objets peuvent avoir un comportement chaotique (par exemple, à la manière d’un ballon de rugby dont le rebond n’est pas facilement prévisible.).
Selon les mots de mots de Yann Le Cun, « On peut affirmer que la conception d'architectures et de paradigmes d'apprentissage pour le modèle de monde constitue le principal obstacle à la réalisation de progrès réels dans le domaine de l'IA au cours des prochaines décennies. » Le chercheur en IA propose se s’y atteler en décrivant une « architecture hiérarchique » et une « procédure d'apprentissage » pour les modèles de monde capables de représenter plusieurs résultats dans leurs prédictions.
Les JEPA (Joint Embedding Predictive Architecture) sont des architectures non génératives conçues pour construire des modèles de monde prédictifs, entraînés principalement par apprentissage auto-supervisé (Self-Supervised Learning - SSL). Contrairement aux modèles génératifs classiques qui tentent de prédire chaque détail des données brutes (comme les pixels d'une image), les JEPA capturent les dépendances entre les entrées sous différentes modalités en effectuant des prédictions dans l'espace des représentations. L’apprentissage auto-supervisé non contrasté permet d’éviter la "malédiction de la dimensionnalité" propre aux méthodes contrasté qui nécessitent de comparer les données à un très grand nombre d'exemples positifs et négatifs. Le SSL non contrasté n'utilise pour sa part que des exemples positifs, il est plus simple et efficace en ressources, sans être moins performant selon certains chercheurs.
Le modèle V-JEPA 2, publié en juin 2025 par une équipe de chercheurs de Méta, dont Yann Le Cun, et du MILA (institut de recherche en intelligence artificielle situé à Montréal), a été pré-entraîné sur un ensemble de données comprenant plus de 1 million d'heures de vidéo provenant d'Internet pour le "visual mask denoising" : soit la capacité à prédire les segments manquants (masqués) d'une vidéo dans l'espace des représentations apprises. Il intègre des innovations techniques comme le 3D-RoPE (Rotary Position Embedding) pour « mieux capturer les relations spatiales et temporelles dans les flux vidéo ». Le modèle affiche la capacité à la compréhension du mouvement, et à anticiper les actions humaines. Interfacé avec un modèle de langage, il rend possible le dialogue sous forme de questions-réponses vidéo. L’intérêt pour les auteurs est notamment que cet encodeur vidéo, bien qu'entraîné sans supervision linguistique, surpasse les modèles entraînés avec du texte sur des tâches nécessitant une compréhension fine du temps et de la physique.
Sur son site, Meta promeut les usages que permettraient ces modèles : pour la robotique, avec une capacité accrue à se déplacer dans des environnements physiques pour accomplir des tâches ménagères et des tâches complexes. Ils pourraient également permettre de produire des technologies d’assistance qui aident les personnes à se déplacer dans des environnements très fréquentés, en leur fournissant des alertes en temps réel sur les obstacles et les dangers qui se présentent.
Lire la suite : Des modèles de mondes avides en données, non sans risques
Télécharger le dossier au format pdf


