
[Article 1/2] From language models to world models
Rédigé par Régis Chatellier
-
25 mars 2026Building on language models, researchers and entrepreneurs have begun designing and developing “world models”, whose objective is to “understand the physical world” and, in some cases, to “predict the future”.
A large language model (LLM) simulates the next word in human language […]. What would you do if you could perfectly simulate the next world – every possible future in the environment that we reside?
Language models have swept across the world in just a few years, transforming the ways in which individuals both in their personal and professional lives, access knowledge and make use of various forms of assistance through tools whose adoption has been faster than that of smartphones. According to the “digital barometer” (baromètre du numérique) 2026, in less than three years, generative AI has already entered the daily practices of one third of users in France, rising to 51% among those aged 18-24. Yet other types of models are already the subject of research and investment within the artificial intelligence community. The aim is now to move beyond “language models” towards “world models”. In this article, both terms will be used, although “world models” remains the more widely adopted designation.
Large Language Models (LLMs) have enabled machines to manipulate natural language after being trained on the symbols, signs and representations of the world produced in writing and speech by humans. However, these LLMs have a limitation: “they operate within symbols, not within space and time”. They can describe how to drive a car, assemble a robot, and so forth, but they do not properly understand the physical world, gravity, friction, causality, and related phenomena. Their knowledge of the world is therefore limited to an “encyclopaedic understanding”.
While the first models date back to 2018, and work at Meta began in 2021, the year 2024 marked a turning point, when researchers began to raise concerns about the imminent limits of scaling. They attributed this both to “the explosion in energy demands associated with computing” and to the fact that LLM developers were running out of conventional datasets used to train their models. 2024 also marks the arrival on the market of large multimodal language models (LMMs) - capable of interpreting not only text but also images, audio, and video - alongside video generation models such as Sora. LMMs have demonstrated their ability to grasp certain aspects of world knowledge that appear to comply fully with the laws of physics, yet examples continue to show that they sometimes reason inconsistently. World models, by contrast, offer the promise of understanding and incorporating the characteristics of the physical world.
The definition of a world model, however, remains the subject of debate (Ding et al.), depending on the perspective whether it is conceived as “understanding the world” or “predicting the future.” Early work focused on abstracting the external, physical world by acquiring an understanding of its underlying mechanisms. The second perspective, notably advocated by artificial intelligence researcher Yann Le Cun, aims not merely at modelling the real world, but also at enabling the model to envisage possible future states of that world. Le Cun recently resigned from his position as Head of Fundamental AI Research at Meta to launch his own startup, AMI (Advanced Machine Intelligence), in Paris, with the goal of embarking on “the third revolution in AI: AI that understands the real, physical world,” following “deep learning twelve years ago, and then the advent of chatbots such as ChatGPT or Gemini three years ago”(Le Monde, January 2026).
Fei-Fei Li, another prominent figure in artificial intelligence and co-founder of World Labs in 2024, regards these world models and what she terms “spatial intelligence" as “the next frontier of AI.” A professor at Stanford and a key figure in Deep Learning alongside Yann Le Cun, Fei-Fei Li was one of the principal architects of the ImageNet image database: as early as 2006, while most researchers were focused on improving models and algorithms, ImageNet aimed to provide researchers worldwide with image data for training large-scale object recognition models. In a post published in 2025, she stated that “Spatial intelligence will transform the way we create and interact with real and virtual worlds, thereby revolutionising storytelling, creativity, robotics, scientific discovery, and much more. It is the next frontier of AI”.
To better understand these nuances, we propose first to review the different types of world models and their applications, before focusing on the vision advocated by Yann Le Cun. We will then address the specific issues and challenges relating to data protection, ethics, and the European regulation on artificial intelligence.
The different categories of world models
Recent work on world modelling has given rise to a wide variety of systems, many of which are optimised for a specific domain or type of simulation. It is noteworthy, however, that these systems share a common feature: they all place considerable emphasis on video and image generation, as well as on the visual quality of the content produced:
- Video game world models, such as Genie 2 (Google DeepMind) and Muse (Microsoft, Oasis, Decart and Etched), simulate video game environments using generative AI models. They are capable of rendering plausible trajectories from visual inputs and actions, producing up to one to two minutes of continuous gameplay. However, they remain limited, as they cannot represent complete game sessions, which may last several hours, and they lack long-term reasoning capabilities
- 3D world models, such as Marble (World Labs), aim to generate 3D scenes and universes from a first-person perspective (egocentric navigation). Marble, available in both freemium and paid versions, allows users to transform text prompts, photos, videos, 3D layouts, or panoramas into editable and downloadable 3D environments. While visually realistic, these models are currently limited to static, non-interactive environments and do not support full-world modelling for decision-making or agent learning
- Generative physical world models (or open-world foundation models), such as Wayve GAIA-2 and NVIDIA Cosmos, are designed to generate synthetic environments for training in physical-world control tasks, including autonomous driving, robotics, and navigation. They rely on a physical-world modelling approach that accounts for external conditions such as weather, lighting, and geography. These models excel in constrained environments for specific tasks. However, they are not “general” world models and do not simulate complex multi-agent worlds or those embedded within society.
- Video generation models, such as Sora (OpenAI) and Veo (Google DeepMind), are designed for general-purpose video generation, producing high-quality videos based on prompts or previously generated images. Although the visual output is impressive, these cannot be considered world models, as the videos are “fixed” and do not support interactions based on alternative actions, nor do they provide simulation controls that would allow reasoning about counterfactual outcomes or evaluating different decisions. Sora, for instance, employs a combination of neural network architectures to process multimodal inputs and generate visually coherent simulations. It can produce visually realistic scenes but struggles to accurately simulate certain real-world physical laws, such as the behaviour of objects under varying forces, fluid dynamics, or faithful representation of light-shadow interactions. These are strictly video generation tools focused on pixel-level synthesis rather than components of decision-making systems.
- Joint Embedding Predictive Models, championed by Yann Le Cun and including a series of architectures developed by Meta, notably V-JEPA, adopt a different approach to world modelling. Unlike generative models, as described below, these models aim to predict and replicate the “common sense” inherent to living beings, both human and non-human. As discussed further below, these models are distinguished by their predictive ambition, enabling them to anticipate different scenarios and/or agent behaviours. This capability sets them apart from the models outlined above.
The « autonomous intelligent machines » model
World models represent a field of AI research that entails a significant shift in both scope and paradigm compared with language models. The idea behind these world models is that language models are limited in the way they represent the world. Since they rely solely on language production and on the manner in which humans have expressed their perception of the world through words or images, they are inherently constrained, according to Yann Le Cun.
The promise of these world models lies in obtaining representations of the physical world through deep neural networks trained on multimodal and dynamic data, which allow them to “understand” its dynamics, physical properties, and spatial characteristics. The data required for their training no longer consists solely of text, but also includes images, videos, and motion data to generate videos that simulate realistic physical environments. Whereas LLMs replicate language, world models aim to model the physical world.
In a position paper published in June 2022, A Path Towards Autonomous Machine Intelligence, Yann Le Cun outlines how machines could learn, reason, predict, and act in ways akin to living beings, both human and non-human. The paper “proposes an architecture and training paradigms for constructing autonomous intelligent agents. It combines concepts such as a configurable predictive world model, behaviour guided by intrinsic motivation, and JEPAs (Joint Embedding Predictive Architectures) non-generative architectures designed to build predictive world models, trained through self-supervised learning.”
This work builds upon the traditions of cybernetics and connectionism. The design of these new world models is based on the observation of living beings, whose capacity to learn and understand the world far exceeds that of current AI and machine learning systems. From a very young age, living beings are capable of acquiring extensive foundational knowledge about how the world works, through observation and with only a limited number of interactions, without supervision and independently of any specific task. According to the author, this accumulated knowledge forms the basis of what is often referred to as “common sense,” which enables one to “determine what is likely, plausible, or impossible.” Thus, living beings can “predict the consequences of their actions, reason, plan, explore, and imagine new solutions to problems.” They are able to avoid placing themselves in dangerous situations when confronted with unknown scenarios, without needing to go through a trial-and-error learning phase. Yann Le Cun illustrates this with the example of autonomous vehicles: “An autonomous vehicle system may require thousands of reinforcement learning trials to learn that taking a corner too quickly has detrimental consequences, and to learn to slow down to avoid skidding. By contrast, humans can rely on their deep understanding of intuitive physics to predict such outcomes and largely avoid fatal errors when learning a new skill. Common sense not only allows animals to predict future outcomes but also to fill in missing information, whether temporal or spatial.”
From this point, the researcher argues that “the development of learning paradigms and architectures that would enable machines to learn world models in an unsupervised (or self-supervised) manner, and to use these models to predict, reason, and plan, constitutes one of the central challenges in AI and machine learning.” His hypothesis is based on the idea that “animals and humans possess a single ‘world model engine’ located somewhere in their prefrontal cortex. This world model engine is dynamically configurable depending on the task to be performed.” In his view, “by relying on a single, configurable world model engine, rather than a distinct model for each situation, knowledge about how the world functions can be shared across different tasks. This may enable reasoning by analogy, by applying a model configured for one situation to another.”
A non-generative architecture inspired by the brain
Drawing on the analogy with the functioning of the human brain its ability to analyse large volumes of data and perceived information, and to process them on the basis of representations of the world already acquired through learning world models constitute the building blocks of what he considers to be autonomous intelligence, as illustrated below and explained in the article A Path Towards Autonomous Machine Intelligence, page 6.
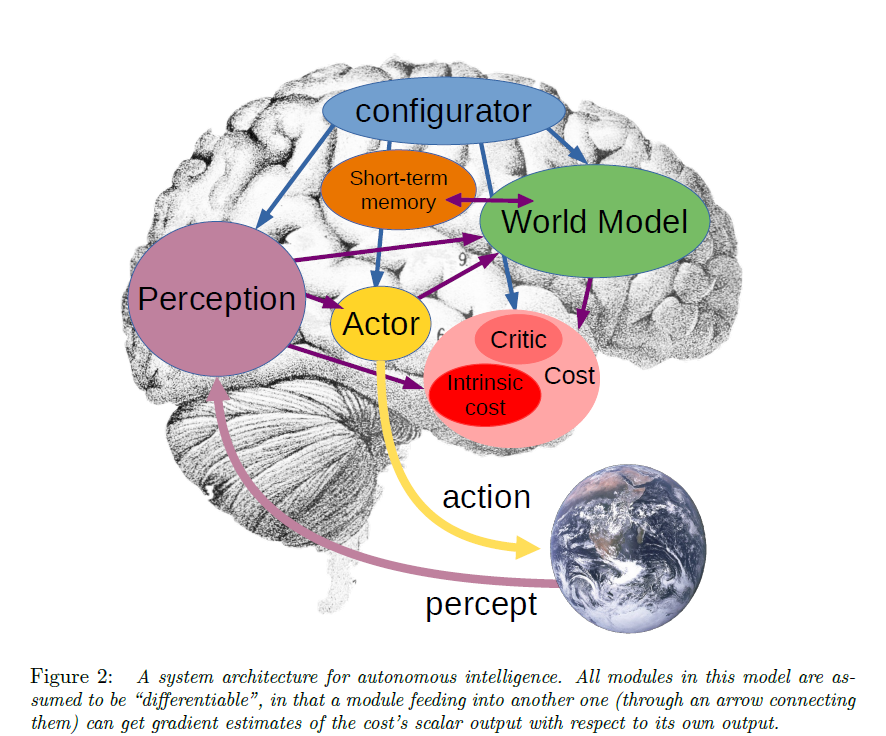
Illustration featured in the article A Path Towards Autonomous Machine Intelligence
Within this architecture, the world model module is the most complex. Its role is twofold:
- to estimate missing information about the state of the world that is not provided by perception;
- to predict plausible future states of the world, whether these correspond to the natural evolution of the world or to plausible future states resulting from a sequence of actions proposed by the actor module
The world model carries out its predictions within an abstract representation space that contains information relevant to the task at hand, ideally across multiple levels of abstraction. This enables it to disregard irrelevant or unpredictable details (such as the movement of leaves on a tree) and to focus on the information necessary for the task. The world model must be capable of representing multiple possible futures. To achieve this, it relies on latent variables that parameterise the set of plausible predictions. By varying these latent variables, the model can generate different trajectories of future states for a given action and account for uncertainty in contexts where agents may be adversarial, or where objects may exhibit chaotic behaviour (for example, like a rugby ball whose bounce is not easily predictable).
In Yann Le Cun’s words, “it can be argued that the design of architectures and learning paradigms for the world model constitutes the main obstacle to achieving genuine progress in AI over the coming decades.” The AI researcher proposes to address this challenge by outlining a “hierarchical architecture” and a “learning procedure” for world models capable of representing multiple possible outcomes in their predictions.
Joint Embedding Predictive Architectures (JEPA) are non-generative architectures designed to build predictive world models, trained primarily through self-supervised learning (SSL). Unlike traditional generative models, which attempt to predict every detail of raw data (such as the pixels of an image), JEPA capture dependencies between inputs across different modalities by making predictions in representation space. Non-contrastive self-supervised learning makes it possible to avoid the “curse of dimensionality” associated with contrastive methods, which require comparing data against a very large number of positive and negative examples. By contrast, non-contrastive SSL relies solely on positive examples; it is therefore simpler and more resource-efficient, while, according to some researchers, maintaining comparable performance.
The V-JEPA 2 model, published in June 2025 by a team of researchers from Meta, including Yann Le Cun, and MILA (the Montreal-based AI research institute), was pre-trained on a dataset comprising more than one million hours of video sourced from the internet for “visual mask denoising”, that is, the ability to predict missing (masked) segments of a video within the learned representation space. It incorporates technical innovations such as 3D-RoPE (Rotary Position Embedding) to “better capture spatial and temporal relationships in video streams”. The model demonstrates capabilities in understanding motion and anticipating human actions. When interfaced with a language model, it enables dialogue in the form of video-based question-and-answer interactions. Of particular interest to the authors is the fact that this video encoder, although trained without linguistic supervision, outperforms text-trained models on tasks requiring a fine-grained understanding of time and physical dynamics.
On its website, Meta highlights the potential applications of these models: in robotics, with an enhanced capacity to navigate physical environments in order to perform household and complex tasks. They could also enable the development of assistive technologies that help individuals move through crowded environments by providing real-time alerts about obstacles and potential hazards.
Read more : Data-hungry World Models: not without risks
Download the long read file in PDF


