
[Article 2/3] S’opposer au moissonnage par des méthodes déclaratives
Rédigé par Romain Darous
-
02 juin 2026Il existe plusieurs manières d’empêcher le moissonnage, qui peuvent se cumuler et qui fonctionnent différemment. Une première manière de le faire est d’avoir recours à des méthodes déclaratives, c’est-à-dire qu’elles n’empêchent pas l’accès du robot au site, mais elles permettent de lister les droits d’accès qui lui sont donnés de manière non contraignante. La méthode la plus simple est d’inclure des mentions dans les CGUs du site. Elles permettent une opposition de principe à la collecte des données du site internet, mais elle est difficilement exploitable par les robots moissonneurs. En effet, cela suppose de collecter les CGUs de chaque domaine moissonné, d’en parcourir le contenu et d’en extraire les règles entourant l’accès au reste du site web. Une telle pratique est sujette à erreur car non normalisée, et passe difficilement à l’échelle. Elle doit donc être complétée par des méthodes qui sont interprétables par une machine.

Sommaire du dossier
- Article introductif : S’opposer à la collecte de données par des robots moissonneurs
- Article 1 : Crawling, scraping, TDM de quoi parle-t-on ?
- Article 2 : S’opposer au moissonnage par des méthodes déclaratives
- Article 3 : S’opposer au moissonnage en bloquant l’accès au site internet
- Article bonus : Le « fingerprinting »
Le protocole RFC 9309, ou « robots.txt »
Le Robots Exclusion Protocol (RFC 9309) est un protocole datant de 1994 permettant à un éditeur de site de définir des autorisations et des interdictions d’accès aux robots moissonneurs. A l’origine, il servait à encadrer le crawling à des fins d’indexation pour le développement de moteurs de recherche. Il prend la forme d’un fichier texte « robots.txt » qui est ajouté au code source d’un site internet. Il doit être accessible publiquement en ajoutant « /robots.txt » à l’URL racine d’un site. L’usage des fichiers « robots.txt » s’étend désormais au contrôle des accès des robots moissonneurs qui collectent des données accessibles en ligne pour entraîner des modèles d’IA.
La configuration du fichier « robots.txt » se fait en deux étapes. Tout d’abord, est désigné le robot auquel sont dictés les droits d’accès, grâce au champ « User-agent ». Ce champ correspond au nom du robot, qui est en général fourni par son développeur et accessible sur son site internet (à titre d’exemple, voir le nom des robots d’Anthropic ci-dessous). Il est également possible de trouver des bases de données qui rassemblent les noms de robots connus. Le champ « User-agent » peut aussi être complété par un astérisque (*). Les règles concernent alors tous les robots. Ensuite, pour chaque champ « User-agent », il reste à faire la liste des droits d’accès, à l’aide des champs « Allow » pour une autorisation, et « Disallow » pour une interdiction. Il est possible d’affiner les autorisations par :
- Page ou répertoire de pages web,
- Par type de fichier (à partir de son extension)



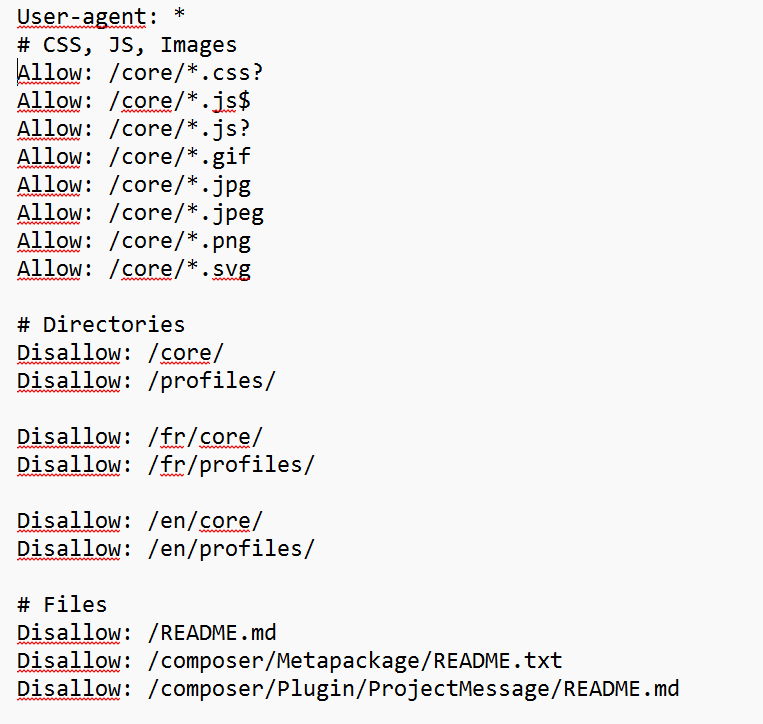
 Extrait du fichier "robot.txt" du site du LINC
Extrait du fichier "robot.txt" du site du LINC
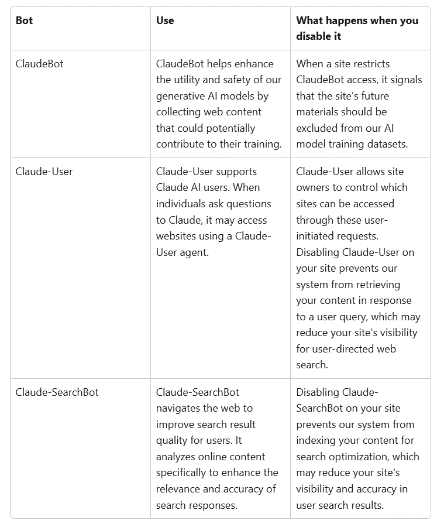
Tableau des robots moissonneurs d'Anthropic et leurs usages
Les tags <meta>
Il est également possible de s’opposer par l’insertion de tags <meta> dans l’en-tête du code HTML d’une page web afin que les robots n’indexent pas le contenu d’une page donnée (argument « NOINDEX ») et qu’il ne scanne pas les liens de la page (argument « NOFOLLOW »).


Exemple de l'utilisation de la balise HTML <meta> pour s'opposer au moissonnage
Cette méthode a le désavantage de s’appliquer sans distinction entre les robots. Des paramétrages plus fins des autorisations peuvent être souhaitées dans certains cas.
Des alternatives émergentes, spécifiques au moissonnage
Le principal défaut du fichier « robots.txt » réside dans l'absence de catégorisation fine des robots.
En effet, les règles d’autorisation ou d’interdiction s’appliquent soit à l’ensemble des robots via le champ « User-agent : * », soit à un certain nombre d’agents qui doivent être nommés précisément dans le fichier. Il n’est donc pas possible de distinguer différentes classes de robots, en séparant ceux utilisés pour l’indexation par des moteurs de recherche de ceux qui servent à la collecte de données en vue d’entraîner des modèles de fondation.
Ainsi, des solutions alternatives émergent, pour compléter le protocole « robots.txt » ou pour donner des droits d’accès spécifiques au moissonnage pour l’entraînement de modèles d’IA.
Le protocole « ai.txt »
Le protocole « ai.txt », proposé par l’entreprise Spawning, reprend la structure des fichiers « robots.txt ». Il se place au même endroit dans le code source d’une page web et est accessible publiquement en ajoutant « /ai.txt » à la racine du site internet.
Cependant, il s’adresse spécifiquement aux robots qui moissonnent les pages internet à des fins d’entraînement de modèles d’IA. Plutôt qu’un fonctionnement par page web, le fichier « ai.txt » permet d’interdire la collecte par type de fichier (texte, image, audio, vidéo, code). Un générateur de fichiers « ai.txt » est disponible sur le site internet de Spawning.
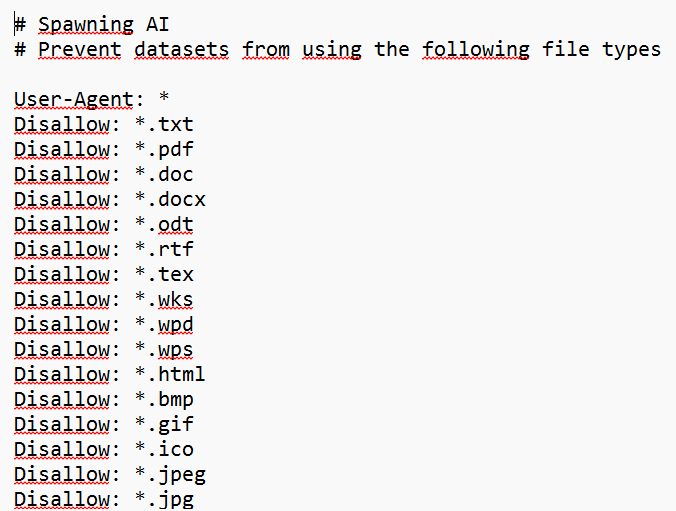
Exemple de fichier "ai.txt" généré sur le site internet de Spawning.
Le protocole TDMRep
Enfin, le protocole communautaire TDMRep (TDM Reservation Protocol) du World Wide Web Consortium (W3C), est une norme non officielle. Deux champs régissent ce protocole :
- tdm-reservation : ce champ est booléen. Il prend la valeur 0 lorsque l’éditeur du site internet autorise le moissonnage de ses données. Lorsqu’il prend la valeur 1, les droits sont réservés, et il faut alors se conformer à la politique de moissonnage du site internet.
- tdm-policy : ce champ optionnel permet d’indiquer un lien vers la politique de moissonnage du site internet. Elle peut être au format texte au sein d’un fichier HTML (lisible par un humain) ou prendre la forme d’un dictionnaire au format JSON, lisible par une machine. Ce paramètre est optionnel. S’il n’est pas spécifié et que le champ tdm-reservation vaut 1, cela signifie que la collecte est a priori interdite.
Le protocole TDMRep permet le respect des directives de trois manières différentes :
- Par l’intégration d’un fichier « tdmrep.json » dans le code source du site internet, qui doit être accessible publiquement en ajoutant « /tdmrep.json » à l’URL racine du site internet. Ce fichier prend la forme d’une liste de dictionnaire JSON. Pour chacun d’entre eux, trois attributs doivent figurer :
- location : ce dernier précise le répertoire du site internet (page ou ensemble de pages web) concerné par l’application des droits
- tdm-reservation,
- tdm-policy (optionnel).

 Exemple type d'un fichier "tdmrep.json" tiré de la documentation du protocole.
Exemple type d'un fichier "tdmrep.json" tiré de la documentation du protocole.
- Par l’inclusion de champs dans les en-têtes de réponse HTTP. Lorsque le contenu d’une page web est envoyée à un utilisateur le protocole propose d’intégrer, dans les en-têtes http qui complètent le contenu du site internet, les paramètres tdm-reservation et tdm-policy pour préciser les droits de collecte de chaque requête effectuée par le client.
- Note : la documentation du protocole précise que c’est la méthode à favoriser car elle est déjà intégrée dans l’API Spawning. Elle permet la création de bases de données par la collecte de données en ligne dans le respect des protocoles d’opposition, dont celui-ci.

Exemple d'insertion des champs "tdm-reservation" et "tdm-policy" dans l’en-tête HTTP des réponses du serveur envoyées au client. Tiré de la documentation du protocole .
- Comme pour les fichiers « robots.txt », il est possible d’inclure ces champs directement dans le code HTML ou dans des fichiers EPUB (abréviation de « Electronic PUBlication », format de fichier standardisé conçu pour la diffusion d’e-books) en utilisant la balise <meta>.
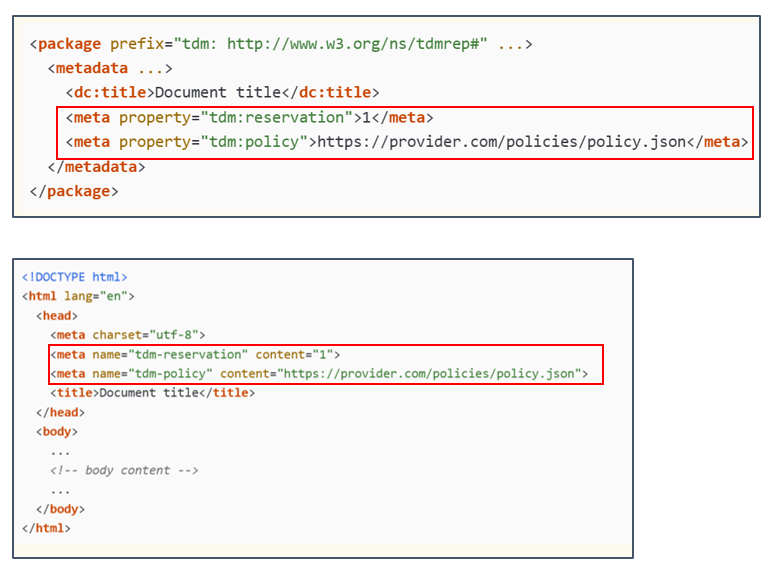
Exemple d'usage des balises <meta> dans des fichiers HTML d’abord, puis EPUB, pour appliquer le protocole TDMRep.
Discussion sur la portée de ces méthodes
Une intégration inégale
Le protocole « robots.txt » reste le protocole le plus utilisé à ce jour pour encadrer les pratiques de robots moissonneurs. D’après Common Crawl, 30 millions des 37 millions de domaines présents dans leur crawl de Novembre/Décembre 2023 disposent d’un fichier « robots.txt » (soit environ 81%). A l’inverse, par exemple, moins de 0,002% des sites internet ont intégré le protocole TDMRep en cumulant la présence des champs tdm-reservation et tdm-policy dans les en-têtes de requête HTTP et dans les métadonnées de sites internet. D’autant que l’adoption concernerait principalement des éditeurs de sites provenant d’Europe de l’Ouest et particulièrement la France, avec 134 des 250 domaines les plus utilisés qui en seraient équipés. Cette tendance peut s’expliquer par le fait que cette norme a été proposée par l’ONG française EDRLab.
La tenue d’un fichier « robots.txt » reste donc la solution la plus largement répandue pour s’opposer au moissonnage d’un site internet. Elle est également celle qui est la plus susceptible d’être respectée par les robots moissonneurs. Néanmoins, il reste utile d’envisager l’implémentation cumulative d’autres méthodes dans la perspective d’un accroissement de leur notoriété, nécessairement progressive, mais qui pourrait faciliter à terme l’exercice des droits dans le contexte du moissonnage.
Des mesures aux garanties limitées
Le défaut inhérent aux solutions déclaratives est qu’elles ne sont pas contraignantes. Si certaines ont une valeur légale qui rend illégitime la collecte sur le site internet donné, elles peuvent ne pas être respectées. La prise en compte de ces mesures relève de la confiance en les acteurs qui développent des systèmes d’IA, parfois affaiblie par le manque de transparence sur la constitution des bases de données d’entraînement des modèles, ainsi que par des manquements identifiés. En effet, d’après l’entreprise Cloudflare ou encore le média Wired, Perplexity aurait par exemple collecté massivement des données en contournant volontairement les fichiers « robots.txt » des sites internet concernés. Cette perte de confiance des éditeurs de site web provoque un risque de fermeture d’internet, comme le décrit le PEReN, par la mise en place de mesures qui limitent l’accès public à leur contenu.
Pour information, l’entreprise Spawning met à disposition la plateforme Have I Been Trained qui permet de déterminer si un site internet fait partie de bases de données d’entraînement connues.
L’expérience utilisateur reste intacte
L’avantage majeur des méthodes déclaratives est qu’elles n’ont aucun impact sur le parcours utilisateur humain, qui n’est pas modifié par la mise en place de ces mesures. Elles ne nécessitent pas non plus la collecte de données particulières sur l’utilisateur du site internet pour être fonctionnelles, contrairement à la mise en œuvre de solutions bloquantes décrites dans l’article suivant. Nous verrons également que certaines de ces méthodes entraînent un ralentissement de l’expérience utilisateur à qui l’on demande de prouver qu’il est bien un humain.
Télécharger le dossier au format PDF
Illustration : Nano Banana 2

