
[Article 1/3] Crawling, scraping, TDM de quoi parle-t-on ?
Rédigé par Romain Darous
-
02 juin 2026Avant d’aborder les moyens permettant aux éditeurs de sites internet de s’opposer à la collecte de leurs données, il convient d’abord de définir les pratiques mises en œuvre par les moteurs de recherche et les entreprises développant des modèles d’intelligence artificielle générative. En effet, plusieurs notions sont mobilisées dans ce contexte : crawling, scraping et TDM (Text and Data Mining). Bien qu’elles désignent des pratiques similaires, leur périmètre exact varie selon les usages et les interprétations. Il est donc essentiel de clarifier la signification de chacun de ces termes afin de poser un cadre précis à la discussion.

Sommaire du dossier
- Article introductif : S’opposer à la collecte de données par des robots moissonneurs
- Article 1 : Crawling, scraping, TDM de quoi parle-t-on ?
- Article 2 : S’opposer au moissonnage par des méthodes déclaratives
- Article 3 : S’opposer au moissonnage en bloquant l’accès au site internet
- Article bonus : Le « fingerprinting »
Web crawling
Le web crawling, ou « exploration du web », désigne le processus d’exploration automatique des pages web accessibles sur Internet. Il débute à partir d’un ensemble initial d’URLs, appelées seed URLs. Ces points de départ permettent de lancer l’exploration du web. Le reste des pages disponibles en ligne, dont le nombre se chiffre en plusieurs milliards, est alors inconnu à ce stade. L’objectif du crawling est précisément de découvrir les pages internet restantes, en suivant les liens hypertextes des pages visitées. Le résultat de cette opération de collecte est appelé un crawl.

Image générée par IA (Imagen, Google)
Prenons l’exemple de CommonCrawl, une organisation à but non lucratif spécialisée dans le crawling. Elle publie chaque mois le résultat de ses explorations, en open data. Comme point de départ, CommonCrawl utilise des URLs fournies par des tiers, d’autres extraites de « plans de sites » (ou sitemaps en anglais, un protocole qui permet aux fournisseurs de sites internet de donner des informations lisibles par une machine sur les pages qu’elle peut explorer), des noms de domaine majeurs identifiés à partir de graphes web qu’elle construit, ou encore des échantillons aléatoires d’URLs provenant de crawls antérieurs. Ces seed URLs se comptent alors en centaines de millions. Ensuite, l’organisation procède par parcours en largeur (Breadth-First Search), avec une profondeur maximale fixée autour de 4 à 5 « sauts », permettant la découverte de nouvelles URLs. Ces méthodes leur permettent d’explorer autour de 2 milliards de pages web par mois, portant à 20 milliards le nombre total d’URLs uniques collectées entre juillet 2024 et juin 2025, par exemple. Chaque crawl permet de découvrir de nouvelles URLs tout en incluant inévitablement des duplicatas d’URLs présentes dans les crawls précédents. Ces doublons permettent toutefois de mettre à jour les pages déjà connues, ce qui constitue l’un des grands défis du web crawling.
Cette exploration s'apparente à un parcours de graphe dirigé. En effet, les sites web sont interconnectés par des liens internes, qui permettent la navigation entre les différentes pages d’un même site, et des liens externes, qui renvoient vers d’autres sites. Par exemple, un comparateur d’hôtels peut regrouper les offres disponibles dans une région et sur une période donnée, puis rediriger l’utilisateur vers les sites des hôtels pour finaliser la réservation. À l’inverse, les pages de Wikipédia sont riches en liens internes facilitant la navigation d’un article à l’autre au sein du site.
A partir d’URLs données, le web crawling permet donc la découverte progressive et récursive de liens. Cette exploration s’accompagne de la collecte des URLs visitées, des titres des pages web, de leur description et leur contenu HTML. Les bases de données constituées à l’issue du crawling atteignent des tailles de l’ordre du PB (Petabyte ou Petaoctet, équivalent à 1000 Teraoctets).
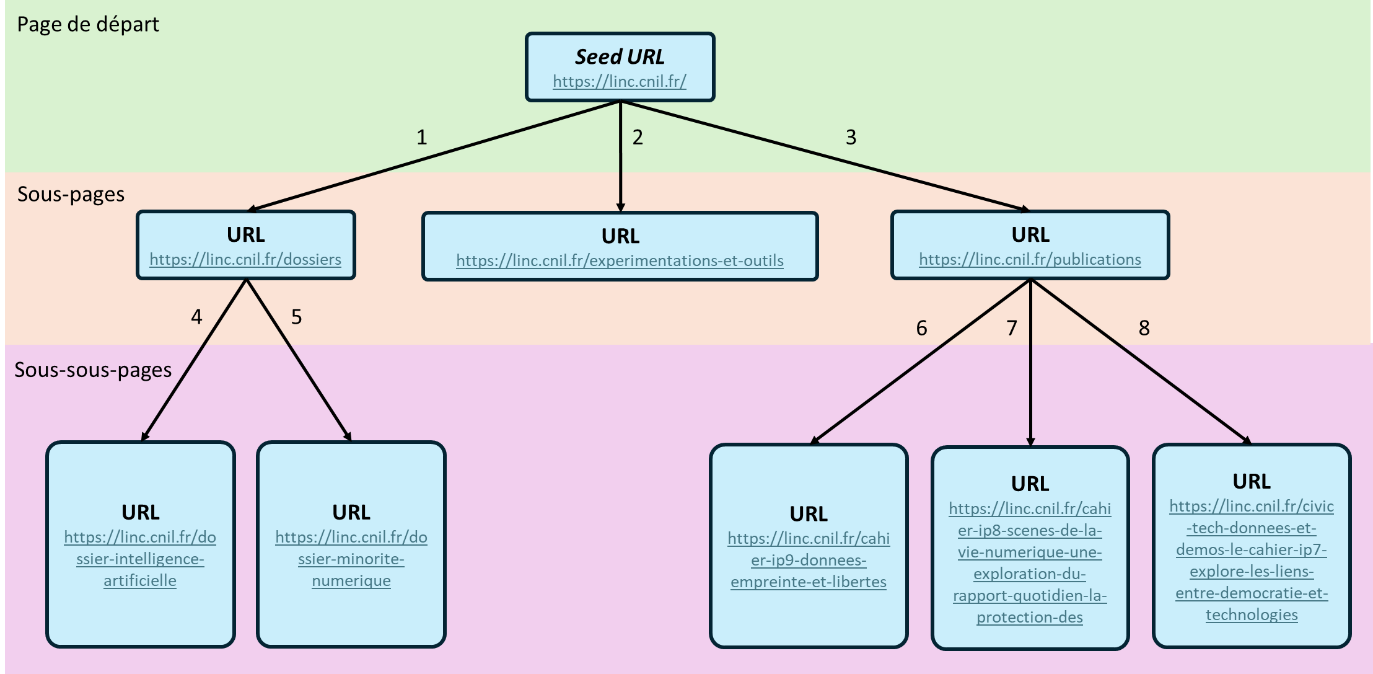
Exemple de découverte de liens utilisant comme seed URL la page d'accueil du site du LINC. La numérotation indique l'ordre de découverte des pages en respectant l'algorithme de parcours BFS.
A l’origine, le web crawling est une des étapes clés du développement de moteurs de recherche. Une fois les URLs parcourues et le contenu des pages associées collecté, une phase d’indexation permet de référencer et classer les pages web entre elles en examinant leur contenu HTML afin de fournir des résultats de recherche pertinents et personnalisés à l’utilisateur de ce moteur de recherche. A titre d’exemple, 50 milliards de pages web étaient indexées par le moteur de recherche Google en janvier 2025.
Web scraping
Le web scraping, ou « moissonnage » en français, concerne quant à lui l’extraction d’informations présentes sur des pages internet déjà connues. C’est la principale distinction avec le web crawling. A partir d’URLs identifiées, le web scraping consiste à analyser le contenu HTML de chaque page afin d’en extraire les données pertinentes, puis à structurer ces données pour les rendre exploitables.
Le web scraping offre une large gamme d’usages, parmi lesquels figure la veille tarifaire, qui consiste à comparer automatiquement les prix pratiqués par une entreprise avec ceux de ses concurrents. Cela permet de mener une surveillance concurrentielle ou d’analyser les tendances tarifaires sur un marché donné. Cette technique facilite également l’agrégation automatisée de données, utile dans de nombreux contextes : analyses financières, constitution de corpus journalistiques, ou encore recherches académiques. Dans ces derniers cas, le scraping permet de rassembler un volume important d’informations pour mener des enquêtes, étayer des analyses, ou établir un état de l’art aussi exhaustif que possible.

Image générée par IA (Imagen, Google)
Les principes du web crawling et de web scraping peuvent donc être résumés ainsi : le premier consiste à collecter les URLs de pages web accessibles en ligne, tandis que le second vise à extraire et structurer les informations pertinentes contenues dans ces pages.
Les robots de scraping et de crawling
Le crawling et le scraping sont deux pratiques complémentaires qui permettent la collecte automatisée de données à grande échelle. Cette automatisation repose sur l’utilisation de robots (appelés crawlers et scrapers, respectivement, ou plus généralement spiders ou parfois wanderers), c’est-à-dire des programmes informatiques conçus pour explorer systématiquement des pages web et en extraire les informations pertinentes. Mis en œuvre à grande échelle, ces robots sont généralement déployés sur plusieurs machines afin de répartir la charge et d’accélérer le processus de collecte. Ils sont hébergés dans des régions géographiques proches des serveurs des sites ciblés, dans le but de réduire la latence et d’optimiser l’efficacité de la collecte.
Leur mise en œuvre à l’échelle de l’internet soulève donc de nombreux défis techniques, algorithmiques et d’infrastructure, en raison des milliards de pages à explorer, du besoin d’exhaustivité, et du volume massif de données généré. Parmi les enjeux majeurs, il est possible de citer :
- La répartition intelligente des robots entre les sites, afin d’éviter les risques de surcharge des serveurs ;
- La mise à jour régulière des pages collectées, avec des questions de fréquence et de priorisation pour garantir l’intégrité et l’exactitude des données ;
- La déduplication des informations collectées, incluant la détection des quasi-duplicatas (near duplicates) à l’aide d’algorithmes tels que SimHash, qui permettent d’identifier des pages très similaires mais non parfaitement identiques (par exemple, des variations contenant des publicités différentes) ;
- Et enfin, le nettoyage des données récoltées, condition indispensable pour les rendre exploitables dans des analyses ou applications en aval.
Exemple de scraping
Le moissonnage s’effectue en repérant les balises HTML d’intérêt par leur type (paragraphes <p>, sections <div>, etc.) ou les classes et identifiants CSS associés (champs « id » et « class »). Sur Python, nous pouvons par exemple utiliser la bibliothèque requests pour télécharger le contenu .html d’une page web, puis la bibliothèque bs4 pour en extraire le contenu d’intérêt.
La figure ci-dessous montre comment il est possible d’automatiser la collecte de données sur une page web, en utilisant soit les balises HTML, soit les noms d’identifiants CSS :
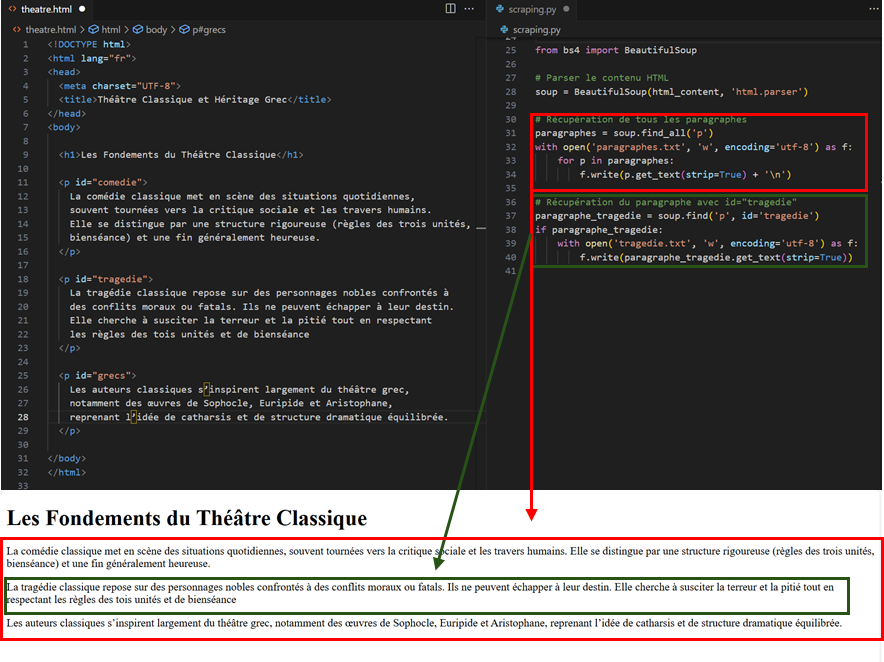
Sur cet exemple est collecté d'abord le texte contenu dans tous les paragraphes de la page web, puis uniquement le paragraphe dont l'identifiant CSS est id="tragedie"
TDM (Text and Data mining)
Pour finir, le terme de TDM (Text and Data Mining ou minage de texte et de données) regroupe l’ensemble des pratiques permettant l’analyse d’un grand nombre de données sous toutes ses formes : texte, image, vidéo, audio, etc. Le concept de TDM désigne donc plus largement toutes les étapes qui permettent de tirer des informations à partir de données obtenues en trop grande quantité pour être traitées par des méthodes traditionnelles. Les pratiques de TDM comprennent donc la collecte et le traitement de ces données (nettoyage, extraction de caractéristiques et représentation mathématique, etc.), ainsi que l’application à ces données d’algorithmes et de traitements analytiques pour en extraire de l’information (clustering, arbres de décision, SVMs, réseaux de neurones, modèles de langages, etc.) ou pour leur structuration. Le moissonnage constituerait donc en ce sens une étape du TDM dans le contexte de développement d’un modèle de fondation. Cependant, la terminologie TDM est parfois utilisée pour désigner la phase initiale de collecte de données et peut donc être confondue avec le web scraping et/ou le web crawling. Par exemple, le protocole TDMRep étudié plus loin désigne un moyen de contrôler la collecte de données publiquement accessibles par les robots sur les sites web.
Application à la création de grandes bases de données pour entraîner des LLMs
La maîtrise du crawling et du scraping permettent notamment la création de grandes bases de données de qualité pour l’entraînement de modèles de fondation, et elle a un impact majeur sur les performances finales du modèle développé.
Ces techniques combinées permettent de procéder à une collecte de masse, aussi exhaustive, diversifiée et de qualité que possible. Le crawling permet la découverte des pages web, qui sont ensuite scrapées pour en extraire le contenu de valeur et l’utiliser pour entraîner des modèles d’IA.
Leur usage simultané implique en général de désigner les deux pratiques par un de ces termes. Dans la suite, lorsque la distinction n’est pas nécessaire, le terme de « moissonnage » sera utilisé pour désigner le scraping et le crawling, et le terme « robot » pour désigner tout algorithme de collecte d’informations publiquement accessibles en ligne.
Télécharger le dossier au format PDF
Illustration : Nano Banana 2

