
[Article 3/3] S’opposer au moissonnage en bloquant l’accès au site internet
Rédigé par Romain Darous
-
02 juin 2026L’article précédent examinait comment s’opposer au moissonnage par des mentions dans les conditions générales d’utilisation ou par des protocoles qui permettent de déclarer des droits d’accès lisibles par une machine. Cependant, un éditeur de site internet peut souhaiter, en complément de ces mesures non bloquantes pour un robot moissonneur, mettre en place des mesures de détection et de blocage de ces robots, au travers de méthodes bloquantes.

Sommaire du dossier
- Article introductif : S’opposer à la collecte de données par des robots moissonneurs
- Article 1 : Crawling, scraping, TDM de quoi parle-t-on ?
- Article 2 : S’opposer au moissonnage par des méthodes déclaratives
- Article 3 : S’opposer au moissonnage en bloquant l’accès au site internet
- Article bonus : Le « fingerprinting »
Le Dynamic Page Loading pour développer le site internet
Il est possible de commencer par une méthode qui ne bloque pas l’accès au site internet aux robots, mais qui peut en cacher le contenu.
Pour développer un site internet, il est désormais très courant d’avoir recours au « Chargement dynamique de page » (ou Dynamic Page Loading en anglais). Ce paradigme permet de modifier le contenu d’un site web sans avoir à en recharger systématiquement la page. Pour ce faire, le contenu HTML à afficher est contenu dans des fonctions Javascript qui sont activées par des actions utilisateur (appui sur un bouton, entrée de texte dans des zones dédiées, ouverture d’un menu déroulant, etc.), ou au chargement d’une page lors de l’accès au site internet. Ainsi, la majorité du code HTML est en fait contenu dans les fichiers Javascript du site internet.
Les méthodes de moissonnage les plus simples (et plus particulièrement de scraping) se font par le téléchargement des fichiers .html sans exécution du code Javascript, ce qui empêche l’accès aux contenus HTML présent dans les fichiers .js. La commande curl utilisable dans un terminal, ou la bibliothèque python requests fonctionnent ainsi.
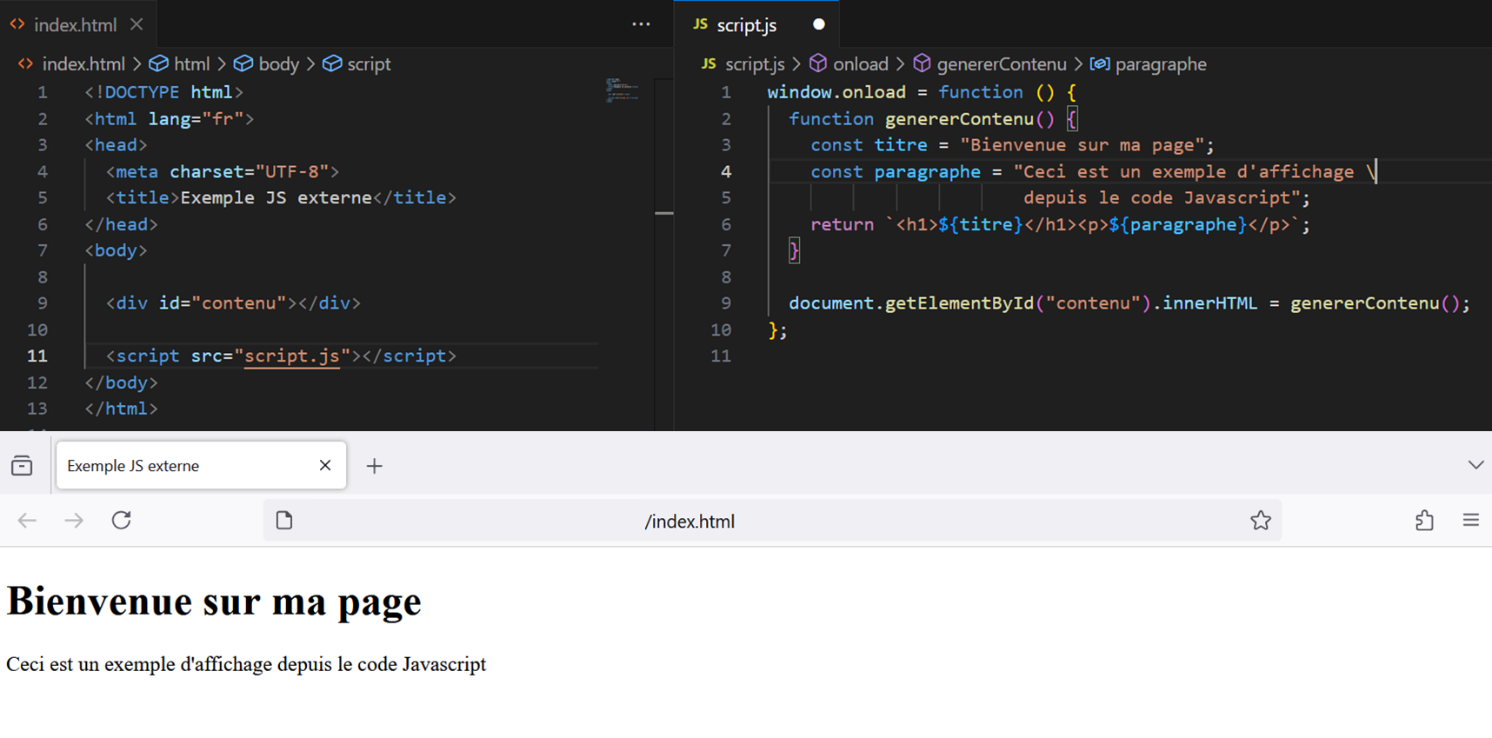
Cet exemple simple illustre comment le contenu HTML du site internet peut s'intégrer dans des fonctions Javascript. Ce contenu n'est alors pas récupérable par une collecte naïve des balises HTML du fichier .html d'un site internet, dont il est absent.
Une mesure à portée limitée
Développer un site internet dynamique présente des avantages pour la gestion de son contenu, la personnalisation et donc d’expérience utilisateur et peut avoir un effet indirect sur le moissonnage des données du site internet. En revanche, utiliser ce paradigme uniquement pour nuire aux robots moissonneurs aura une portée limitée. En effet, de nombreuses libraires de programmation telles que Selenium permettent de simuler un navigateur internet et peuvent donc exécuter du code JavaScript. Lorsqu’une fonction Javascript est déclenchée par l’interaction de l’utilisateur avec le site internet, le contenu HTML présent dans les fonctions JavaScript est alors chargé sur la page internet (le fichier .html est modifié en conséquence) et peut donc être collecté.
Mettre en place des restrictions d’accès
Il est également possible de limiter l’accès à certaines pages en imposant la connexion à un compte utilisateur, avec des méthodes d’authentification. Cette approche a été choisie notamment par 404media après avoir découvert que le contenu de leurs articles était massivement moissonné. Une alternative préférée par d’autres médias est de protéger les pages web par des paywalls (littéralement « murs payants »), qui nécessitent de souscrire à un abonnement ou de payer pour accéder à leur contenu.
Ces techniques sont rarement implémentées dans le but initial d’empêcher le moissonnage d’un site internet et peuvent avoir des conséquences sur l’accès à son contenu, dans le cas où l’utilisateur serait obligé et créer un compte et/ou de payer pour accéder à une partie du site internet. Il est toutefois utile de relever l’impact que ces fonctionnalités ont sur l’accès au site internet pour un robot moissonneur.
Utiliser des CAPTCHAs
CAPTCHA est l’acronyme de Completely Automated Public Turing test to tell Computers and Humans Apart (qui pourrait être traduit par « un test public complètement automatisé permettant de distinguer les humains des machines »). Lorsqu’un site internet en est équipé, un CAPTCHA prend la forme d’une fenêtre qui apparaît lorsqu’un utilisateur tente d’y accéder. Son rôle est de déterminer si l’utilisateur qui tente de se connecter à un site internet donné est humain, ou s’il s’agit d’une machine. La vérification passe par la résolution d’énigmes qui peuvent prendre plusieurs formes (voir des exemples de CAPTCHAs ci-dessous) :
- Une analyse d’images : trouver les images répondant à une consigne donnée, résoudre un puzzle, orienter un objet 3D dans la bonne direction, …
- La lecture d’un texte déformé (suite de chiffres, de lettres, de mots, etc.) qu’il faut écrire,
- La transcription d’un échantillon audio (mot, suite de chiffres, etc.),
- La résolution d’énigmes mathématiques : des questions mathématiques simples sont posées en langage naturel, et elles doivent être résolues,
- Etc.
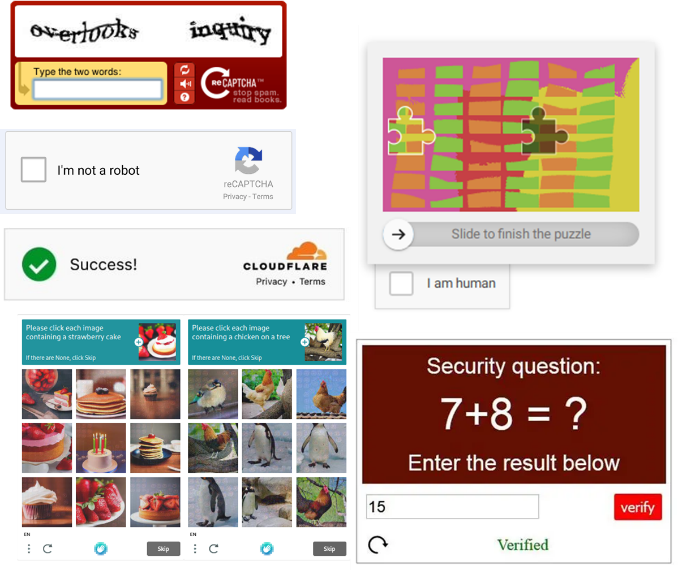
Exemple de CAPTCHAs qu'on peut rencontrer sur internet. Il y en a beaucoup d'autres, qui peuvent prendre des formes variées.
Ces tâches, réalisables par des humains, le sont plus difficilement par une machine, et peuvent en empêcher l’accès au site internet.
L’impact sur l’expérience utilisateur
Le désavantage majeur des CAPTCHAs est leur impact sur l’expérience utilisateur humaine. En effet, leur implémentation systématisée implique pour un utilisateur de devoir résoudre ces énigmes à chaque fois qu’il visite un nouveau site internet. D’après le site internet BuiltWith, près d’un tiers des sites internet parmi le top le million des plus visités sont équipés d’une technologie CAPTCHA. Une étude de Stanford montrait en 2010 que la résolution de CAPTCHAs visuels prenait en moyenne 9,8 secondes et 28,4 secondes pour un CAPTCHA audio.
Des alternatives moins chronophages, mais plus questionnables du point de vue de la protection des données personnelles, existent, pour lesquelles la résolution d’énigme est soit complètement abandonnée, soit déclenchée en cas de comportement suspect. Lors du premier accès d’un utilisateur sur un site internet, la technologie CAPTCHA déclenche un suivi de son comportement (fréquence des requêtes, temps passé par page et type de pages visitées, etc.). Les statistiques de l’utilisateur sont ensuite transmises à l’éditeur de site qui peut choisir de le bloquer s’il détecte une activité anormale (c’est ainsi que fonctionne reCAPTCHAv3 de Google). Dans le cas de la version 2 de reCAPTCHA, l’analyse du comportement utilisateur peut déclencher automatiquement l’apparition d’une énigme à résoudre s’il est probable que l’utilisateur soit un robot. D’autres concurrents comme hCAPTCHA ou Cloudflare Turnstile proposent des solutions similaires.
Il s’agit en fait de combiner les CAPTCHAs traditionnels avec d’autres méthodes de détection de robots, qui se rapprochent de celles utilisées par des CDNs (voir plus loin). En effet, un éditeur de site peut mettre en place ce suivi des actions utilisateur et déterminer si elles sont inhabituelles ou anormales (fréquence et quantité de requêtes très élevées, par exemple). Dès lors, il peut choisir de bloquer l’adresse IP concernée pour lui empêcher l’accès au site.
Une méthode loin d’être infaillible
Certes, les CAPTCHAs sont un rempart au moissonnage, mais en plus de poser des questions d’accessibilité aux sites internet qui en sont équipés, ils peuvent être contournés. Les modèles d’IA à usage général peuvent résoudre des CAPTCHAs de plus en plus facilement. Un exemple visuel est la nouvelle IA agentique d’OpenAI qui est capable de remplir les CAPTCHAs rencontrés seule lorsqu’elle répond à une requête de l’utilisateur. Il est également possible d’avoir recours à des fermes à CAPTCHAs, qui permettent la location de main d’œuvre à faible coût vers laquelle sont redirigés tous les CAPTCHAs rencontrés pas des robots moissonneurs. Ils sont ensuite résolus manuellement, puis le robot poursuit sa navigation sur le site internet souhaité.
D’autre part, lorsque l’apparition d’un CAPTCHA n’est pas systématique, mais déclenchée par un comportement suspicieux, il suffit de faire en sorte que le robot soit toujours considéré par le site internet comme un nouvel utilisateur, avec des méthodes de rotation d’adresse IP, par exemple. Le CAPTCHA n’est alors jamais déclenché.
Examiner les requêtes HTTP du client
Une source d’information très riche pour identifier des robots moissonneurs est l’examen des requêtes HTTP envoyées par le client (l’utilisateur naviguant sur Internet) au serveur web qui héberge un site internet. Ces derniers communiquent en suivant des protocoles standardisés, organisés en plusieurs couches : applicative (protocole HTTP), de sécurité (protocole TLS), de transport (protocoles TCP ou QUIC), etc. En examinant les en-têtes des requêtes HTTP et les propriétés du navigateur utilisé, il est possible de vérifier si l’utilisateur est un robot moissonneur, par le calcul des « empreintes » des requêtes à chaque couche du protocole et en les comparant avec des empreintes connues. On parle de fingerprinting.
Une empreinte est une chaîne de caractères encodée qui résume un ensemble caractéristique de paramètres observés lors d’une communication réseau. Elle permet d’identifier la machine à l’origine d’une requête et de déduire certaines informations sur ses attributs techniques. L’analyse d’empreintes permet par exemple de détecter l’utilisation d’un VPN ou de programmes informatiques pour se connecter au site internet (Python, Javascript). Ces informations sont des indices qui peuvent indiquer que le client qui se connecte est un robot.
Une fois l’empreinte d’un client déterminée à une couche donnée du protocole de communication réseau, elle est comparée à des empreintes connues. Si elle fait partie d’empreintes considérées comme autorisées à accéder au site internet, la connexion peut s’établir. Sinon, l’adresse IP est bloquée. Il est également utile de comparer les empreintes entre les couches du protocole HTTP, pour vérifier la cohérence des informations entre les couches. Des informations incohérentes entre elles peuvent être un indice de la présence d’un robot, qui a tenté de simuler le comportement d’un utilisateur humain.
Ainsi, la bibliothèque JA4+ est une bibliothèque open source qui dispose de plusieurs méthodes permettant de déterminer les empreintes TCP, TLS et HTTP d’un client. A chaque couche, les données obtenues sont triées, concaténées, hachées puis tronquées, afin d’obtenir une empreinte de taille identique pour chaque client.
Pour en savoir plus sur le fingerprinting, vous pouvez consulter notre article dédié.
Utiliser des pare-feux ou des CDNs
Plutôt que d’implémenter et de maintenir ces solutions « à la main », il est possible de faire appel à des pare-feux, des CDNs (Content Delivery Network), qui sont des outils complémentaires permettant de filtrer et de réguler le trafic réseau. Ils implémentent en général des outils de détection de robots. La bibliothèque JA4+ fournit par exemple une liste de services qui implémentent ses empreintes (dont Wireshark, outil utilisé dans cet article pour visualiser des requêtes HTTP ; vous en avez donc peut-être repéré des empreintes sur certaines images explicatives).
Cloudflare, par exemple, utilise les empreintes JA4 pour détecter des robots et explique dans un article que l’empreinte TLS est particulièrement efficace et robuste. A noter que l’entreprise explore également des alternatives, comme l’implémentation de labyrinthes de pages web : plutôt que de bloquer systématiquement tous les robots, il peut suffire de les détecter, puis d’ajouter des liens invisibles qui les enferment dans une suite de pages infinie, les rendant inefficaces.
Le PEReN donne quelques compléments d’informations au sujet des pare-feux et des CDNs dans leur note dédiée.
Des méthodes imparfaites et parfois intrusives
Dans le cas de robots moissonneurs qui respectent les directives déclaratives présentées dans la section précédente et qui sont identifiés avec un nom publiquement accessible, le recours à des mesures bloquantes n’est en principe pas nécessaire. Elles peuvent cependant les compléter, car les robots moissonneurs seront aisément identifiés et pourront donc être bloqués. Elles sont aussi une garantie supplémentaire pour les éditeurs de site qui n’ont pas de moyen de vérifier que les directives des fichiers normatifs sont respectées.
Toutefois, elles permettent surtout le blocage des robots moissonneurs qui s’affranchissent des règles de moissonnage renseignées par les éditeurs de sites internet qui pourraient souhaiter collecter le contenu disponible en passant inaperçu, par simulation des navigateurs existants et d’un comportement humain crédible. D’autre part, les méthodes présentées servent plus généralement à la détection de robots malveillants et peuvent donc améliorer la sécurité globale. Toute méthode reste cependant faillible, et il existe une multitude de contenus en ligne expliquant comment contourner les méthodes de blocage des robots, en imitant toujours plus fidèlement des utilisateurs humains.
D’autre part, comme évoqué plus haut, ces méthodes bloquantes (CAPTCHAs, paywalls, authentification) peuvent nuire à l’expérience utilisateur en rendant moins direct l’accès au contenu du site.
Télécharger le dossier au format PDF
Illustration : Nano Banana 2

