
[Article 3/3] Prevent web data extraction by blocking access to the website
Rédigé par Romain Darous
-
02 June 2026The previous article examined how to prevent web data extraction through statements in the terms of use or through protocols that make it possible to declare machine-readable access rights. However, a website publisher may wish, in addition to these non-blocking measures for bots, to implement detection and blocking mechanisms.

Summury of the long read file
- Introductory article: How to prevent data extraction bots from collecting publicly available data
- Article 1: Crawling, scraping and TDM explained
- Article 2: Preventing web data extraction using declarative methods
- Article 3: Prevent web data extraction by blocking access to the website
- Supplementary article: Fingerprinting
Dynamic Page Loading for website development
It is possible to start with a method that does not block bots from accessing the website, but which may hide its content.
When developing a website, it is now very common to use “Dynamic Page Loading”. This paradigm makes it possible to modify the content of a website without systematically reloading the page. To achieve this, the HTML content to be displayed is embedded in JavaScript functions that are triggered by user actions (clicking a button, entering text into input fields, opening a dropdown menu, etc.), or upon page load when accessing the website. As a result, most of the HTML code is actually contained within the website’s JavaScript files.
The simplest scraping methods (and in particular scraping techniques) operate by downloading .html files without executing JavaScript code, which prevents access to HTML content embedded in .js files. Commands such as curl, usable in a terminal, or the Python requests library, work in this way.
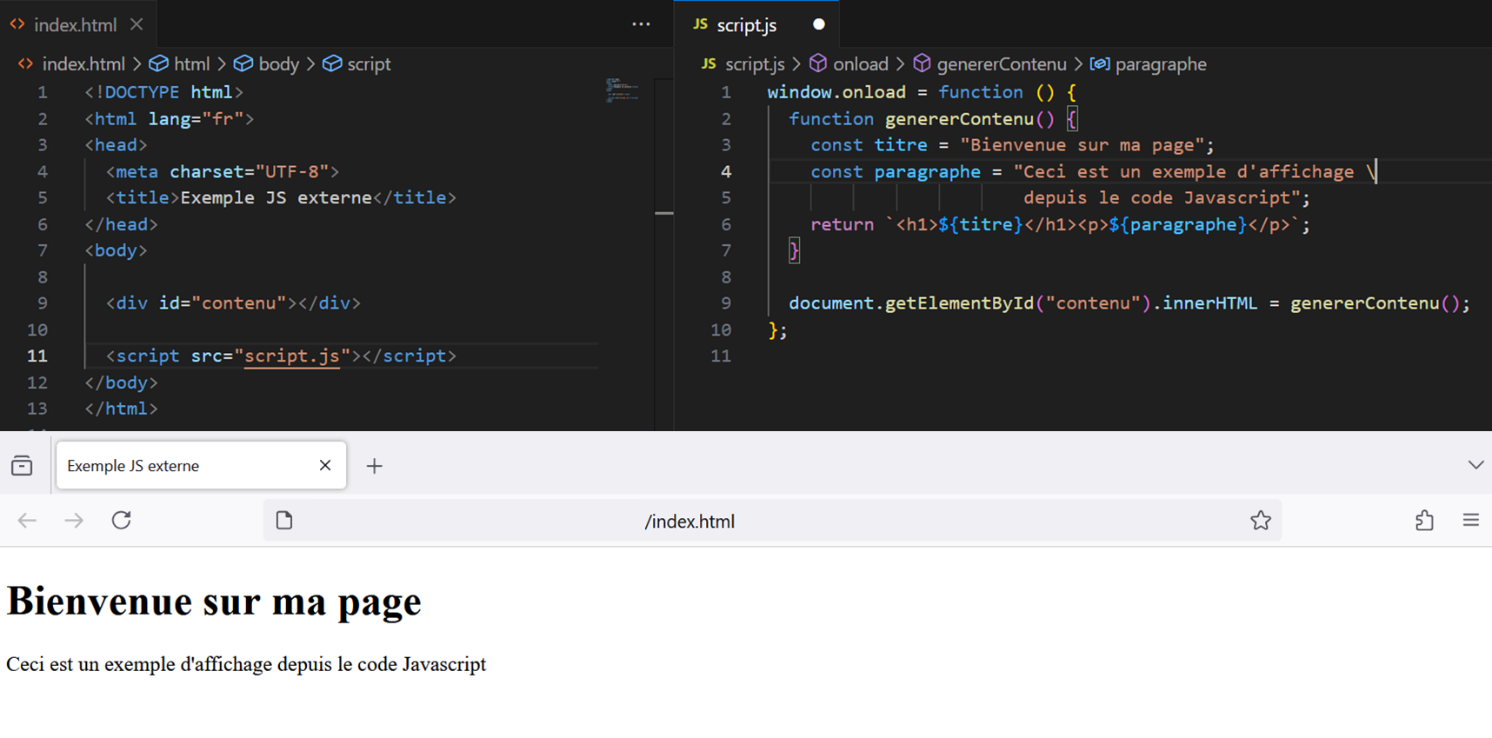
This simple example illustrates how a website’s HTML content can be embedded within JavaScript functions. In this case, the content is not retrievable through a naive collection of HTML tags from a website’s .html file, as it is not present there.
A measure with limited effectiveness
Developing a dynamic website offers advantages in terms of content management and user experience personalisation, and can have an indirect effect on the scraping of website data. However, using this paradigm solely to hinder scraping bots has limited effectiveness. Indeed, many programming libraries such as Selenium make it possible to simulate a web browser and therefore execute JavaScript code. When a JavaScript function is triggered by user interaction with the website, the HTML content contained in the JavaScript functions is then loaded onto the web page (the .html file is modified accordingly) and can therefore be collected.
Setting up access restrictions
It is also possible to limit access to certain pages by requiring users to log in through authentication methods. This approach was notably adopted by 404media after discovering that their article content was being extensively scraped. An alternative preferred by other media outlets is to protect web pages with paywalls, which require users to subscribe or pay in order to access the content.
These techniques are rarely implemented with the primary aim of preventing website scraping, and they may affect access to content, as users may be required to create an account and/or pay to access part of the website. However, it is still useful to note the impact these features have on access to the website for scraping bots.
Using CAPTCHAs
CAPTCHA is an acronym for “Completely Automated Public Turing test to tell Computers and Humans Apart”. When a website is equipped with one, a CAPTCHA appears as a window when a user attempts to access it. Its role is to determine whether the user trying to connect to a given website is human or a machine. Verification relies on solving puzzles that can take several forms (see examples of CAPTCHAs below):
- Image analysis: selecting images that match a given instruction, solving a puzzle, rotating a 3D object into the correct orientation, etc.
- Reading distorted text (sequences of numbers, letters, words, etc.) that must be transcribed,
- Transcribing an audio sample (word, sequence of numbers, etc.),
- Solving mathematical puzzles: simple math questions posed in natural language that must be answered,
- Etc.
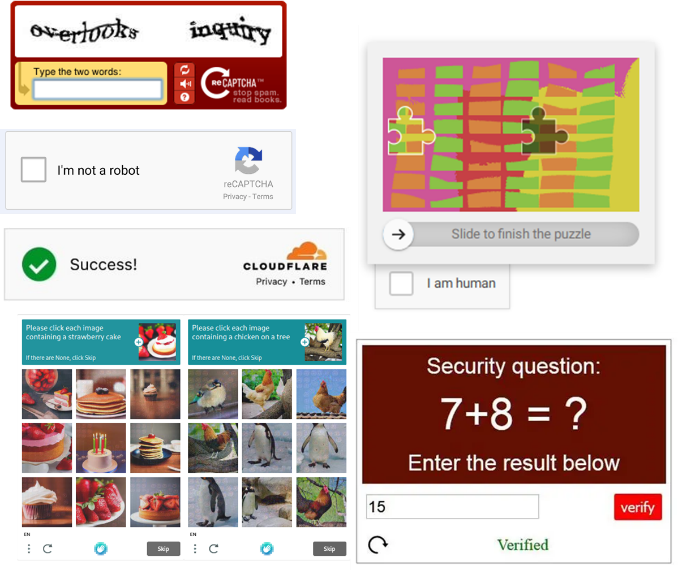
Examples of CAPTCHAs that can be encountered on the Internet. There are many others, which can take a variety of forms.
These tasks, which are easily performed by humans, are more difficult for a machine and may prevent it from accessing the website.
Impact on user experience
The main drawback of CAPTCHAs is their impact on the human user experience. Indeed, their systematic implementation requires users to solve these puzzles each time they visit a new website. According to the website BuiltWith, nearly one third of websites among the top one million most visited are equipped with CAPTCHA technology. A Stanford study showed in 2010 that solving visual CAPTCHAs took an average of 9.8 seconds, and 28.4 seconds for audio CAPTCHAs.
Less time-consuming alternatives exist, but they are more questionable from a personal data protection standpoint, as the solving of puzzles is either entirely removed or triggered only in cases of suspicious behavior. When a user accesses a website for the first time, CAPTCHA technology may track their behavior (request frequency, time spent per page, types of pages visited, etc.). The user’s activity data is then transmitted to the website publisher, who may choose to block them if abnormal activity is detected (this is how Google’s reCAPTCHAv3 works). In the case of reCAPTCHA v2, behavioral analysis may automatically trigger the appearance of a challenge if the user is likely to be a bot. Other competitors such as hCAPTCHA or Cloudflare Turnstile offer similar solutions.
These approaches essentially combine traditional CAPTCHAs with other bot-detection methods, similar to those used by CDNs (see below). Indeed, a website publisher can implement user behavior monitoring and determine whether it appears unusual or abnormal (for example, a very high frequency or volume of requests). From there, they may choose to block the associated IP address to prevent access to the website.
A method far from foolproof
While CAPTCHAs do act as a barrier to data extraction, they also raise accessibility issues for websites that use them and can be bypassed. General-purpose AI models are increasingly able to solve CAPTCHAs with ease. A visual example is OpenAI’s new agentic AI, which can complete CAPTCHAs on its own when responding to a user’s request. It is also possible to rely on CAPTCHA farms, which provide low-cost outsourced human labor to which all CAPTCHAs encountered by scraping bots are redirected. These are then solved manually before the bot continues navigating the target website.
Moreover, when CAPTCHA challenges are not systematically displayed but triggered by suspicious behavior, it is sufficient to ensure that the bot is always perceived by the website as a new user, for example through IP address rotation techniques. In such cases, the CAPTCHA is never triggered.
Examining the client’s HTTP requests
A highly valuable source of information for identifying bots is the examination of HTTP requests sent by the client (the user browsing the Internet) to the web server hosting a website. These systems communicate using standardized protocols organized in several layers: application (HTTP protocol), security (TLS protocol), transport (TCP or QUIC protocols), and so on. By examining HTTP request headers and the properties of the browser being used, it is possible to determine whether the user is a bot by computing “fingerprints” of the requests at each protocol layer and comparing them with known fingerprints. This is known as fingerprinting.
A fingerprint is an encoded string that summarizes a set of characteristic parameters observed during a network communication. It makes it possible to identify the machine originating a request and to infer certain information about its technical attributes. Fingerprint analysis can, for example, detect the use of a VPN or of programming languages used to connect to a website (Python, JavaScript). This information provides clues that the client connecting may be a bot.
Once a client’s fingerprint has been determined at a given layer of the network communication protocol, it is compared with known fingerprints. If it matches those considered authorised to access the website, the connection is allowed. Otherwise, the IP address is blocked. It is also useful to compare fingerprints across different layers of the HTTP protocol in order to verify consistency between them. Inconsistencies in the information may indicate the presence of a bot that has attempted to simulate human user behavior.
Thus, the JA4+ library is an open-source library that provides several methods for determining a client’s TCP, TLS, and HTTP fingerprints. At each layer, the collected data is sorted, concatenated, hashed, and then truncated in order to obtain a fingerprint of identical size for each client.
For more information on fingerprinting, you can refer to our dedicated article.
Using firewalls or CDNs
Rather than implementing and maintaining these solutions “manually,” it is possible to rely on firewalls and CDNs (Content Delivery Networks), which are complementary tools for filtering and regulating network traffic. They generally incorporate bot-detection mechanisms. The JA4+ library, for example, provides a list of services that implement its fingerprints (including Wireshark, a tool used in this article to visualize HTTP requests; you may therefore have spotted fingerprints in some of the explanatory images).
Cloudflare, for instance, uses JA4 fingerprints to detect bots and explains in an article that TLS fingerprinting is particularly effective and robust. It should be noted that the company is also exploring alternative approaches, such as implementing web page mazes: rather than systematically blocking all bots, it may be sufficient to detect them and then add invisible links that trap them in an infinite sequence of pages, rendering them ineffective.
The PEReN provides additional information on firewalls and CDNs in its dedicated note.
Imperfect and sometimes intrusive methods
In the case of data extraction bots that comply with the declarative rules presented in the previous section and are identified with a publicly accessible name, the use of blocking measures is, in principle, not necessary. However, they may still be used as a complement, since bots can be easily identified and therefore blocked. They also provide an additional safeguard for website publishers who have no way of verifying whether the rules set out in formal files are being respected.
Nevertheless, these measures are primarily effective at blocking bots that disregard the rules set by website publishers and that may seek to collect publicly available content while remaining undetected, by simulating existing browsers and credible human behavior. More broadly, these methods are used for bot detection and can therefore improve overall security. However, no method is infallible, and there is a wide range of online content explaining how to bypass bot-blocking techniques by increasingly accurately imitating human users.
Furthermore, as mentioned above, these blocking methods (CAPTCHAs, paywalls, authentication) can harm user experience by making access to website content less straightforward.
Download the long read file in PDF
Illustration : Nano Banana 2

