
[Article 2/3] Preventing web data extraction using declarative methods
Rédigé par Romain Darous
-
02 June 2026There are several ways to prevent web data extraction, which can be combined and operate differently. One such approach involves declarative methods, meaning they do not block a bot’s access to the website but instead specify access rights in a non-binding way. The simplest method is to include provisions in the website’s terms of use (CGUs). These allow for a general objection to data collection the website, but they are costly to read. Indeed, this would require collecting the terms of use for each scraped domain, parsing their content, and extracting the rules governing access to the rest of the website. Such a practice is error-prone due to its lack of standardisation and does not scale well. It therefore needs to be complemented by machine-readable methods.

Summury of the long read file
- Introductory article: How to prevent data extraction bots from collecting publicly available data
- Article 1: Crawling, scraping and TDM explained
- Article 2: Preventing web data extraction using declarative methods
- Article 3: Prevent web data extraction by blocking access to the website
- Supplementary article: Fingerprinting
The RFC 9309 protocol, or « robots.txt »
The Robots Exclusion Protocol (RFC 9309) is a protocol from 1994 that allows a website publisher to define permissions and restrictions for scraping bots. Originally, it was designed to regulate crawling for indexing purposes in the development of search engines. It takes the form of a text file, “robots.txt,” which is added to a website’s source code. It must be publicly accessible by appending “/robots.txt” to a website’s root URL. The use of “robots.txt” files has now expanded to include controlling access by scraping bots that collect publicly available data to train AI models.
The configuration of a “robots.txt” file is done in two steps. First, the bot to which access rules apply is specified using the “User-agent” field. This field corresponds to the name of the bot, which is generally provided by its developer and available on its website (for example, see the names of Anthropic bots below). It is also possible to find databases that compile the names of known bots. The “User-agent” field can also be set to an asterisk (*), in which case the rules apply to all bots.
Next, for each “User-agent” entry, the access permissions must be defined using the “Allow” field for authorization and the “Disallow” field for restriction. These permissions can be further refined by:
- web page or directory,
- file type (based on file extension)



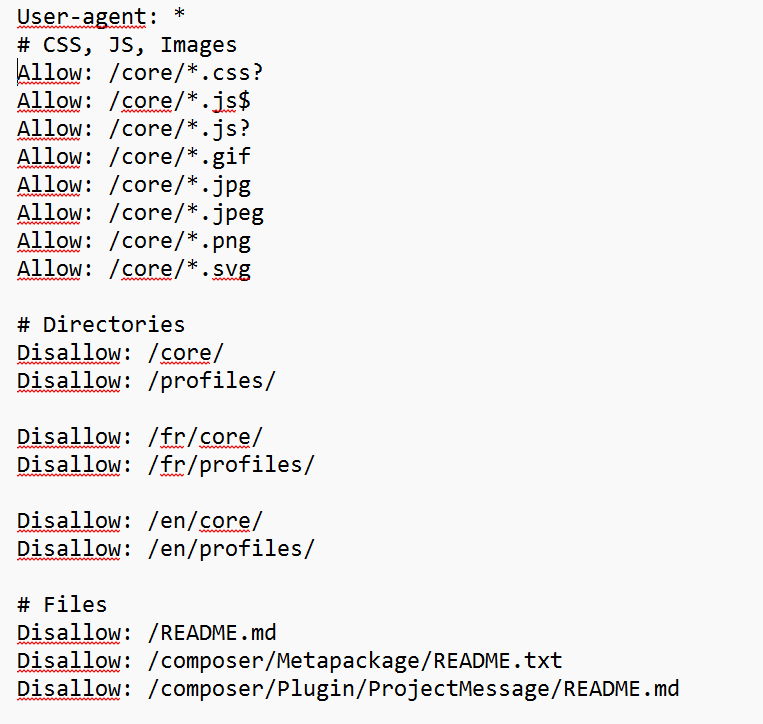
 Excerpt from the ‘robots.txt’ file of the website of the LINC
Excerpt from the ‘robots.txt’ file of the website of the LINC
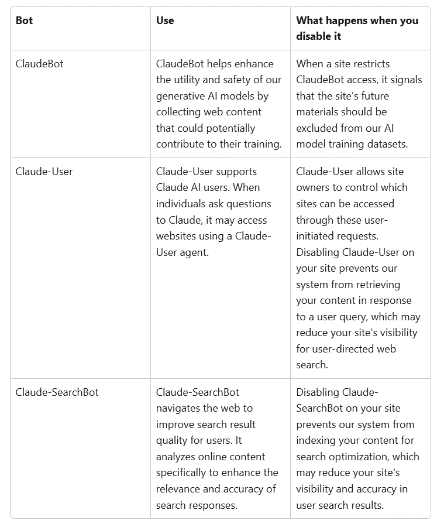
Table of Anthropic’s AI bots and their uses
The tags <meta>
It is also possible to object through the insertion of <meta> tags in the header of a web page’s HTML code, so that bots do not index the content of a given page (“NOINDEX” directive) and do not scan the links contained on the page (“NOFOLLOW” directive).


Example of the use of the HTML <meta>tag to prevent scraping
This method has the disadvantage of applying indiscriminately to all bots. In some cases, more granular access settings may be desirable.
Emerging alternatives specific to scraping
The main limitation of the “robots.txt” file lies in the absence of a fine-grained categorization of bots.
Indeed, authorization or restriction rules apply either to all bots through the « User-agent : * » field, or to a specific set of agents that must be explicitly named in the file. It is therefore not possible to distinguish between different categories of bots, such as those used for indexing by search engines and those used for web data extraction to train foundation models.
As a result, alternative solutions are emerging, either to complement the “robots.txt” protocol or to provide access rights specifically tailored to data collection for the training of AI models.
The « ai.txt » protocol
The « ai.txt » protocol, proposed by Spawning, follows the same structure as « robots.txt » files. It is placed in the same location within a website’s source code and is publicly accessible by appending « /ai.txt » to the root of the website.
However, it is specifically intended for bots that scrape web pages for the purpose of training AI models. Rather than operating on a page-by-page basis, the « ai.txt » file makes it possible to prohibit collection by file type (text, image, audio, video, code). An « ai.txt » file generator is available on Spawning’s website.
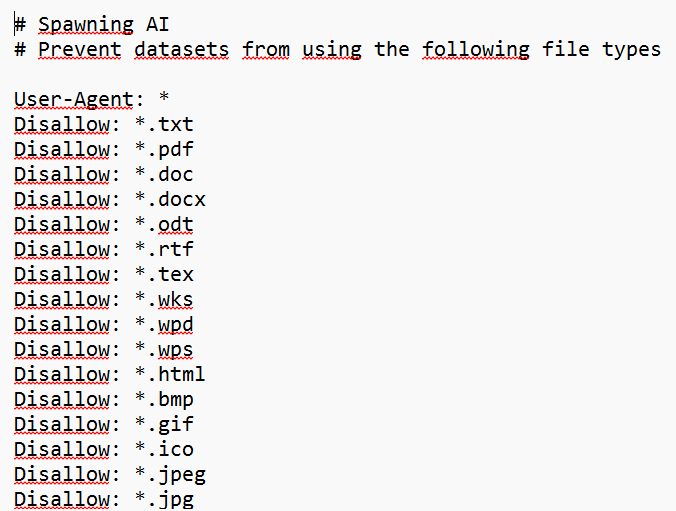
Example of an "ai.txt" file generated on Spawning’s website
The TDMRep protocol
Finally, the community protocol TDMRep (TDM Reservation Protocol), developed by the World Wide Web Consortium, is an unofficial standard. Two fields govern this protocol:
- tdm-reservation: this field is Boolean. It takes the value 0 when the website publisher authorizes the scraping of its data. When it takes the value 1, rights are reserved, and the website’s scraping policy must then be complied with.
- tdm-policy: this optional field makes it possible to indicate a link to the website’s scraping policy. This policy may be provided as text within an HTML file (human-readable) or as a dictionary in JSON format (machine-readable). This parameter is optional. If it is not specified and the tdm-reservation field is set to 1, this means that collection is, in principle, prohibited.
The TDMRep protocol allows directives to be enforced in three different ways:
- By integrating a « tdmrep.json » file into the website’s source code, which must be publicly accessible by appending « /tdmrep.json » to the website’s root URL. This file takes the form of a list of JSON dictionaries. Each dictionary must contain three attributes:
- location: specifies the directory of the website (a page or set of web pages) to which the rights apply;
- tdm-reservation;
- tdm-policy (optional).

 Typical example of a "tdmrep.json" file taken from the protocol documentation
Typical example of a "tdmrep.json" file taken from the protocol documentation
- By including fields in HTTP response headers. When the content of a web page is sent to a user, the protocol proposes integrating the tdm-reservation and tdm-policy parameters into the HTTP headers accompanying the website content, in order to specify the collection rights applicable to each request made by the client.
- Note: the protocol documentation specifies that this is the preferred method, as it is already integrated into the Spawning API. It enables the creation of databases through the collection of online data while complying with objection protocols, including this one.

Example of the insertion of the "tdm-reservation" and "tdm-policy" fields into the HTTP response headers sent by the server to the client. Taken from the protocol documentation.
- As with « robots.txt » files, it is possible to include these fields directly in the HTML code or in EPUB files (« Electronic PUBlication » a standardized file format designed for distributing e-books) using the <meta> tag.
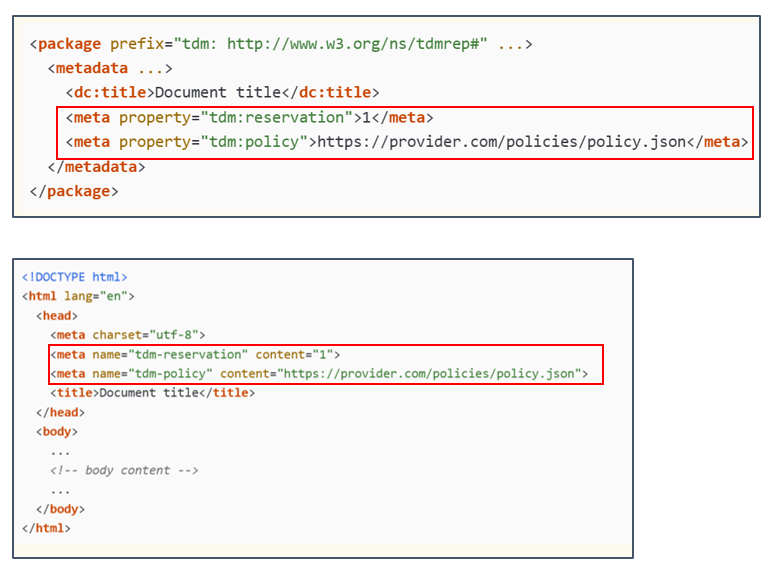
Example of the use of <meta> tags in HTML files first, and then in EPUB files, to apply the TDMRep protocol.
Discussion on the scope of these methods
Uneven adoption
The « robots.txt » protocol remains the most widely used protocol to date for regulating the practices of scraping bots. According to Common Crawl, 30 million of the 37 million domains included in their November/December 2023 crawl had a « robots.txt » file (approximately 81%). By contrast, for example, fewer than 0.002% of websites had implemented the TDMRep protocol when combining the presence of the tdm-reservation and tdm-policy fields in HTTP request headers and website metadata. Moreover, adoption appears to concern mainly website publishers from Western Europe, particularly France, with 134 of the 250 most-used domains reportedly equipped with it. This trend may be explained by the fact that the standard was proposed by the French NGO EDRLab.
Maintaining a « robots.txt » file therefore remains the most widely adopted solution for opposing the scraping of a website. It is also the one most likely to be respected by scraping bots. However, it remains useful to consider the cumulative implementation of other methods, with a view to increasing their visibility necessarily gradual but which could ultimately facilitate the exercise of rights in the context of web data extraction.
Measures with limited guarantees
The inherent limitation of declarative solutions is that they are not binding. They may not be respected. Compliance with these measures relies on trust in the actors developing AI systems, a trust that is sometimes weakened by a lack of transparency regarding the construction of training datasets, as well as by documented breaches. Indeed, according to Cloudflare and the media Wired, Perplexity, for example, has allegedly collected large volumes of data while deliberately circumventing websites’ « robots.txt » files. This loss of trust among website publishers creates a risk of an “internet closure,” as described by the PEReN, through the implementation of measures that restrict public access to their content.
For information, the Spawning company provides the Have I Been Trained platform, which makes it possible to determine whether a website is included in known training datasets.
User experience remains unaffected
The main advantage of declarative methods is that they have no impact on the human user journey, which remains unchanged by the implementation of these measures. They also do not require the collection of specific data about website users in order to function, unlike the deployment of blocking solutions described in the following section. We will also see that some of these methods lead to a slowdown in the user experience, as users are required to prove that they are indeed human.
Download the long read file in PDF
Illustration : Nano Banana 2

