
Digital watermark: a salutary transparency measure? [2/2]
Rédigé par Alexis Léautier
-
27 October 2023A well-known technique in copyright protection, digital watermarking has been put forward as a solution to the problem of detecting artificial content. Brandished by many users as the most robust solution, digital watermarking is nevertheless an ambiguous notion in the field of AI, and can be the name of a number of different practices. This article details each of them, based on a review of the scientific literature.

Contents :
- Overview and outlook for artificial content detection solutions [1/2]
- Digital watermark: a salutary transparency measure? [2/2]
Generally associated with the transparency of artificial content, digital watermarking in AI can in fact be used in a variety of contexts, and is not a salutary measure as hoped (or claimed) by some. By exploring the cases in which this technique can be used, we define the scope of its functionalities. We then look at the alternatives to this technique, as well as the approaches - whether in terms of regulations or positions - of international bodies and authorities on the subject. Finally, we list the possible ways in which this technique could be used, as well as the reservations that the limitations of this method impose.
What is digital watermarking all about ?
Digital watermarking is a technique related to steganography, a field that is close to but distinct from cryptography. As with cryptography, the aim is to transmit information securely. However, whereas cryptography involves writing a message or piece of information in such a way that it cannot be deciphered (thus making it secret), steganography focuses on hiding a message within its content so that it is indiscernible rather than indecipherable. Watermarking is a special case in this respect, since the aim is not always to insert an indiscernible mark, but rather to make it inseparable from its medium. The information concerned may be a meaningless marking, such as the watermark used on photographs, or a more complex message. It may be directly visible when the document is viewed, or invisible. Digital documents can be of any type. However, an initial analysis suggests that it is easier to watermark a video, a high-resolution photo or a large model than to watermark a short text. The effectiveness of a watermark and its ability to remain attached to the watermarked information depend primarily on the amount of information (or 'entropy') in the content to be watermarked: the greater the amount of information in the content, the easier it is to add a watermark, particularly an invisible one.
In the field of artificial intelligence, and in particular generative AI, some of whose techniques are described in detail in "Synthetic data: Say Daddy, how do we make data? a distinction can be made between four main categories:
- The watermarking of specific documents, such as images, videos, sound documents or computer programs;
- Watermarking databases, such as a set of images, videos, music or even computer programmes;
- The watermarking of artificial intelligence models, such as a neural network that is modified so that it can be re-identified;
- Watermarking the output of artificial intelligence systems (AIS).
These categories of watermarking therefore target four practices with different objectives and issues.
Watermarking documents
Document watermarking is a well-known concept for protecting the intellectual property of multimedia content. The example of images marked with the author's or broadcaster's brand to ensure document traceability is particularly representative. In a different field from digital watermarking, Digital Rights Management (DRM) is also frequently used to protect copyright and is based on restricting access to content (software, images, DVDs, operating systems or digital books) to the possession of a key (entered by the user or supplied with the content). In the case of the marketing of an AI model, this principle seems applicable, however it would not be for the productions of generative AIs since DRM requires a specific device for reading the protected content. Moreover, these protections are deemed fallible (as in the case of digital books). In practice, digital watermarking can therefore take different forms and serve different purposes.
When the watermark is visible, the aim is to prevent or dissuade unintended use of the documents. The watermark can also be used to prove ex-post that a person could not have been unaware that the use of a document was illegal. In the case of artificial intelligence, training on watermarked documents is generally more difficult: in the case of an image, the watermark generally deteriorates the quality of the image and therefore the performance of the trained model. However, techniques (notably AI) can be used to remove these watermarks.
There are also watermarks that are imperceptible to the human eye, which can be used for similar purposes (for example, to identify the origin of a document, although the document must be processed to reveal the watermark), but also in very different contexts. This is particularly true of Glaze which is described in Shan et al. 2023. This technique, which differs from a watermark in that the mark applied is not intended to be detected later, makes it possible to conceal a mask - a subtle modification of the pixels making up the image in the manner of a veil (the authors use the term "cloak") - on works of art, making it impossible for an AIS to learn the author's artistic style. The use of such a measure would make it possible to prevent the generation of content attempting to reproduce the artistic style of a particular author. This technique is therefore more akin to data poisoning, a subject that has been the subject of numerous publications and which aims to deteriorate the performance of a model trained on 'poisoned' data. The University of Chicago laboratory that published Glaze is working on just such a tool, Nightshade a more general tool described in detail in Shan et al., 2023, which will make it possible to degrade the performance of models in all domains, not just the reproduction of artistic works.

Results of attempts to reproduce the style of the author of works with (column "Mimicked art when Glaze is used") and without (column "Mimicked art when Glaze is not used") the Glaze watermark, source: Shan et al., 2023
Theoretically, watermarking particular documents could allow their reproduction by a generative AI system to also contain the watermark, which is of interest in terms of intellectual property protection. However, the robustness of the watermarking to the generation process cannot be guaranteed.
Watermarking databases
While the aim of watermarking a particular document is to protect the intellectual property associated with it, the aim of database watermarking is to control the re-use of a database as a whole.
Technically, several watermarking methods exist, although the procedure used always remains the same. It consists of 3 stages:
- Watermarking the database, which can involve adding a mask invisible to the human eye to images, making them "radioactive" in the terms of Sablayrolles et al, 2020or by replacing certain words in a text with synonyms or inserting words (such as adjectives or adverbs) without substantially modifying the meaning, as proposed by Tang et al., 2023.
- Training on the watermarked database, which can undergo all sorts of modifications such as sorting, augmentation, dilution in a larger database, etc.
- In some cases, detection of watermarking on the trained model, to which access is possible in different ways (white box when the auditor has all the information on the system, or black box when he has as much information as an external attacker), using a statistical test. This detection does not exist in certain cases, such as when the objective is to prevent learning from the database.

Examples of digital watermarks applied to images to prevent them from being modified (LaS-GSA) or reproduced (UnGAN and IAP). The 'Adversarial' image is created by superimposing a filter on the 'Original' image, changing the output of a model from 'Expected' to 'Output' source: Wang et al., 2023
To be effective, the watermark inserted in this way will have to be imperceptible to the human eye or by automated tests on the data, robust to modifications to the base (dilution, augmentation, etc.) and the data (compression, slicing, etc.), and cause a sufficient change in the behaviour of an AI model, without reducing the quality of the data too significantly. The watermarking detection test will be limited by the access given to the model, and by the robustness of the watermarking. Since the detection test is based on a probabilistic process, the result obtained in certain cases may not remove any doubt as to the use of the watermarked database. In the context of a control, this test should therefore be supplemented by an additional investigation. Furthermore, even if access to the model is not always necessary to verify the presence of the watermark, it should be noted that the detection test will not always be possible depending on the context, since it requires at least the ability to perform a large number of queries on the model. Finally, the techniques identified do not appear to be adaptable to all types of model. While it is possible for a watermarking technique to have the desired effect on a classification model, the methods observed cannot be generalised to all types of model, and in particular to generative models, which are not very common in the literature to date.
Despite its limitations, this watermarking model could allow greater traceability of learning uses. In particular, it could make it possible to identify that a model has been trained on an open dataset for which it does not respect the user licence, or on a dataset that has been unintentionally disclosed. Furthermore, watermarking the database can also make it possible to ensure the traceability of an AI model in order, for example, to protect its intellectual property, since watermarking the database can lead to a precise modification in the model, as described in the following section.
Watermarking AI models
Watermarking a database is a technique that makes it possible to implant a backdoor in an AI model in order to identify it at a later date. This backdoor does not have a malicious objective, as is often implied by this term and specified in the LINC article "A short taxonomy of attacks on AI systems". However, this method will generally have the effect of modifying its performance and functionality. Watermarking the model is a solution that can sometimes overcome this difficulty. An analysis of the literature reveals several techniques: Regazzoni et al. 2021and Li et al, 2021, classify the methods identified. The watermarking of an AI model can be carried out in different ways:
- By injecting a backdoor into the model (dynamic watermarking). The model is trained on selected data in order to teach it a particular task. The backdoor thus implanted in the model will enable it to be identified by performing specific queries, for example by submitting candidate data that is known to have been marked. This technique is similar to database watermarking, although here the protected object is the model.
- By injecting a watermark into the model weights (static watermarking). A special learning protocol can be used, for example, to embed a watermark in the model weights when the model is being learned. This can be done by means of a cost function (i.e. the function that measures the performance of the model during training and thus gives its general direction) specifically designed for this purpose: this is known as a regularisation measure. This technique can also be used to trace a particular instance of a model when the watermark has a unique identifier. The detection test will then be based on a study of the model weights in a white box access, or on the study of queries carried out in large numbers, enabling part of the model to be reconstructed (grey or black box).
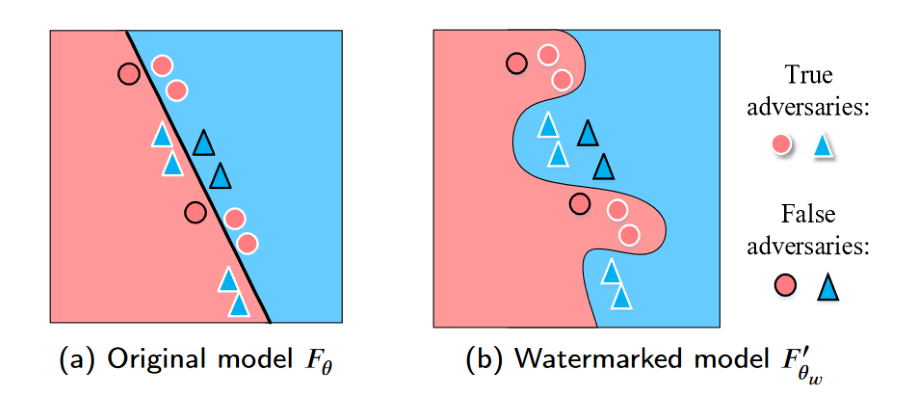
Watermarking a classification model by modifying its behaviour on true adversaries, source: Li et al., 2021
The methods observed are generally imperceptible in use, but they are faced with a significant number of difficulties. Firstly, inserting the age watermark must not reduce the model's performance, which can be a problem if its functionality (dynamic watermarking) or weights (static watermarking) are altered. Secondly, the watermarking must be robust to the modifications made to the model, whether these are routine operations in an operational process or sometimes advisable for data protection purposes, as detailed in the article 'Sécurité des systèmes d'AI, les gestes qui sauvent' (such as pruning, which consists of deleting some of the neurons in a network to make it run faster, fine-tuning, which involves re-training a model on a reduced database that is more specific to the target task, or model compression, i.e. the application of compression techniques commonly used in signal processing to an AI model, which reduces the memory it occupies), or linked to an attack. When the model is open (open source, for example), attacks aimed at removing the watermark could be particularly easy to implement. Finally, it seems that only static watermarking combined with white-box access to the model can be used to verify the presence of the watermark unequivocally. The other techniques will only provide a probabilistic result that will need to be verified later.
It should be noted that these methods do not necessarily identify that the output of a model has been artificially generated, although specific methods do allow this, as described below.
The watermarking of generative AI productions
Several techniques can be used to watermark generative AI productions, such as inserting an a posteriori watermark into each production. However, these techniques are generally not very robust, can deteriorate the quality of productions and cannot be generalised to open models. Techniques similar to database or model watermarking, identified by Wang et al. 2023, can be used to modify an AI model so that its outputs are systematically watermarked. The techniques observed can be classified into two categories:
- Training on data containing the watermark to be reproduced: the training data is then itself watermarked, and the training protocol can be modified to include watermark reproduction as a parallel objective to training;
- Learning the watermarking task, by modifying the learning protocol or by setting specific parameters for the model, during which it learns to reproduce the watermarking in the data generated.
These methods are subject to the same difficulties as those observed for watermarking databases and models: the watermarking task must be sufficiently robust and imperceptible in the model. However, this method has the advantage of facilitating the dissemination of AI models, since it is relatively complex to modify the model to remove the watermark.
The methods identified seem to concern mainly image generation models. Text watermarking methods, on the other hand, still seem to lack maturity. One of them, tested on ChatGPT by OpenAI, is described by Kirchenbauer et al, 2023. It is based on the privileged insertion of words belonging to a "green list" which it is then possible to detect in the generated text. However, this method is based on a statistical test whose results may be less convincing on a short text, in a different lexical register, or if modifications are made to the generated text. In particular, this text would become obsolete if an attacker managed to reproduce the green list (which is updated each time a new word or token is generated, so this risk is fairly unlikely in practice).
Watermarking generative AI productions thus makes it possible to ensure their traceability, and in particular to check that content is artificial and to find out where it comes from. These measures seem particularly useful at a time when artificial content is beginning to appear in disinformation contexts, as in the case of the use of false images during the campaign for the presidency of Ron DeSantis or a false sound recording that had an impact on the legislative elections in Slovakia. There is still a long way to go before an entirely fictitious person is created, as was explored in the article " IArnaques, Crimes et Botanique "so realistic are these tools becoming?
To put in a nutshell
The methods presented in this literature review have certain drawbacks, but they can achieve certain objectives, such as the traceability of specific documents, databases, models, or even certain categories of production such as images, text, code or sound documents. However, the approaches observed lack unity, a problem linked to the absence of standards in the field. In addition, there still seems to be a grey area when it comes to watermarking textual content, which is a priori the most difficult to watermark robustly because of the small amount of information contained in a text.
In addition, all the proposed techniques require positive action on the part of the designer of the object (document, database, model or production of the model) to be protected. This scheme may be feasible for the purpose of protecting intellectual property, but it seems inadequate when it comes to protecting personal data or detecting artificial content, particularly when the designer or user of a generative AI is malicious.


{kind=link}