
[dossier] Sécurité des systèmes d’IA
Rédigé par Félicien Vallet
-
19 janvier 2022Les systèmes d’IA engendrent des risques de sécurité spécifiques en comparaison à des systèmes d’information classiques, tant les nouvelles capacités d’apprentissage automatique (machine learning) augmentent la « surface d’attaque » de ces systèmes, en introduisant de nombreuses (et nouvelles !) vulnérabilités. Le LINC vous propose un triptyque d’articles afin d'y voir plus clair.

Face à la complexité et au volume croissants des cyberattaques, il est désormais évident que l’IA peut apporter de nouvelles réponses aux risques de sécurité. En effet, l'IA peut, avec sa capacité à analyser un contexte donné, contribuer à y détecter des anomalies ou des comportements inhabituels, révélateurs d’attaques et ainsi, à renforcer les outils de protection, détection, réponse et remédiation : augmentation du taux de détection, détection au plus tôt des attaques, amélioration de la capacité d’adaptation aux évolutions permanentes des systèmes d’information, etc. A titre d’exemple, de nombreuses sondes réseaux (IDS, intrusion detection systems) et déployées sur des terminaux (EDR, endpoint detection and response) intègrent désormais des technologies d’IA, en complément de leur moteur de détection par signature permettant de reconnaître un programme malveillant. Ces systèmes apprennent ainsi le comportement « normal » de l’infrastructure et toute déviation observée par la suite est signalée à un analyste comme un potentiel risque cyber (d’autres exemples peuvent être trouvés ici).
Petite taxonomie des attaques des systèmes d’IA
Si les technologies d’IA peuvent améliorer la sécurité des systèmes d’information, elles engendrent également des risques spécifiques. En effet, le problème réside dans le fait qu'avec les nouvelles capacités de l’apprentissage automatique et dans la perspective de son utilisation de plus en plus large, sont introduites de très nombreuses vulnérabilités que des attaquants sont susceptibles d’exploiter. Certaines de ces vulnérabilités peuvent permettre de perturber le fonctionnement du modèle et l'amener à émettre une prédiction incorrecte. D'autres, en revanche, laissent un attaquant libre d'extraire des informations sensibles du modèle, telles que les données sous-jacentes ou le modèle lui-même.
Plusieurs travaux scientifiques recensent les différents types d’attaques comme par exemple (Pitropakis et al., 2019). Par ailleurs, le laboratoire MITRE – une organisation à but non lucratif américaine dont l'objectif est de travailler pour l'intérêt public dans les domaines de l'ingénierie des systèmes, la technologie de l'information, les concepts opérationnels, et la modernisation des entreprises – a lancé l’initiative ATLAS (Adversarial Threat Landscape for Artificial Intelligence Systems). Celle-ci est une base de connaissances des méthodes, techniques et études de cas d’attaques menées à l’encontre de systèmes d'apprentissage automatique, constituée à partir d’observations du monde réel, de démonstrations réalisées par des experts en sécurité (pentesters, red teamers, etc.) et de connaissances issues de la recherche universitaire.
Les travaux sur le sujet de la sécurité des modèles d’IA ont en effet connu un intérêt croissant au cours des dernières années, ce qui est mesurable au nombre de publications scientifiques sur le sujet. La Figure 1 illustre cette tendance sur une sous-partie du domaine, les exemples adversaires introduits en 2014 par (Goodfellow et al., 2014). En pratique, de la même façon que ce qui existe dans le domaine de la cryptographie depuis toujours, on observe une course permanente entre les méthodes d’attaque et de défense, aucune de ces dernières ne garantissant à ce jour la robustesse des systèmes dans 100% des cas.
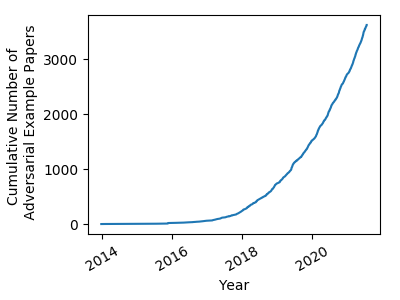
Figure 1. Evolution du nombre d’articles dédiés au sujet des exemples adversaires
(source blog de Nicholas Carlini).
- Lire l’article Petite taxonomie des attaques des systèmes d’IA
P[ɑ̃]nser la sécurité des systèmes d’IA
Au cours des dernières années, de grandes entreprises telles que Google, Amazon, Microsoft et Tesla ont vu certains de leurs systèmes d’IA attaqués. Cette tendance est amenée à s'accentuer. Selon un rapport de l’entreprise de conseil Gartner de 2019, 30% des cyberattaques d'ici 2022 impliqueront des vols de modèles (model theft), l’utilisation d’exemples contradictoires (aversarial examples) ou l’empoisonnement de données (data poisoning). Ces attaques sont d’autant plus probables que les systèmes d’IA seront progressivement installés dans de nombreux environnements et a fortiori serviront de plus en plus de support à des décisions automatiques pouvant présenter un intérêt pour une personnelle malveillante. A titre d’exemple, un concurrent peut envisager tenter de « saboter » un logiciel d’IA utilisé pour le contrôle qualité dans un environnement industriel, un attaquant peut chercher à optimiser l’analyse d’une demande de crédit, etc. Dans son rapport d’avril 2021, la startup israélienne Adversa, spécialisée dans la sécurité des systèmes d’IA, détaille les applications les plus attaquées aujourd’hui (voir Figure 2).
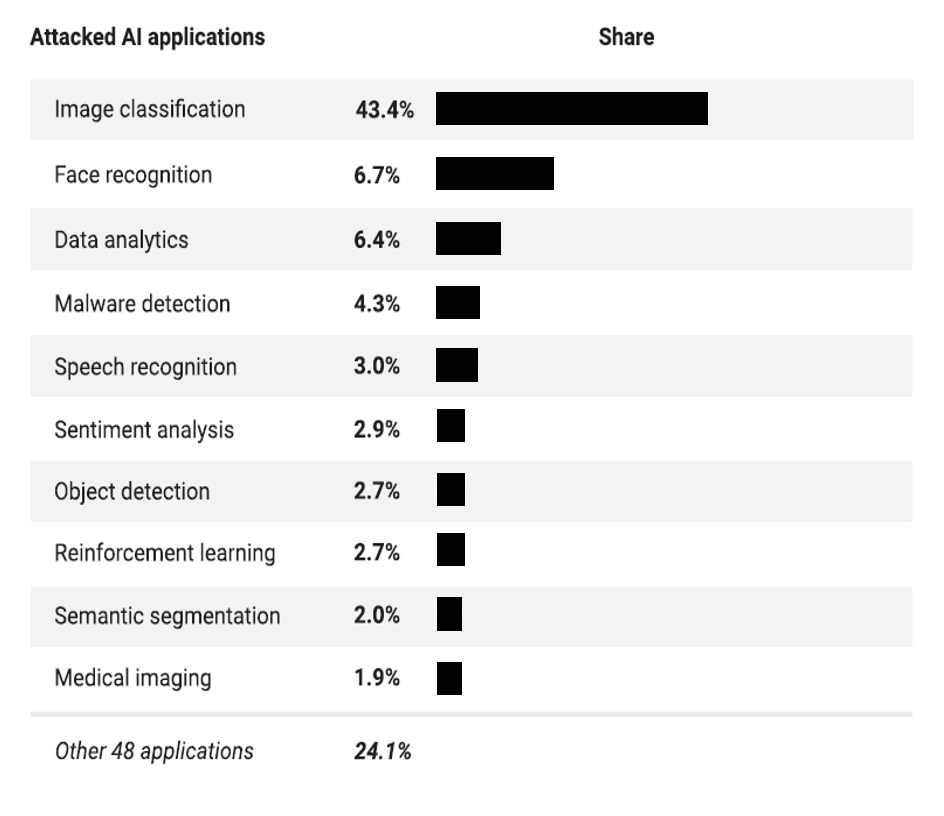

Aujourd’hui, le monde de l'industrie apparaît mal préparé à faire face à de telles menaces comme l’indique une enquête menée en 2021 auprès de 28 organisations, petites et grandes, par (Shankar et al., 2021) : vingt-cinq d'entre elles ne savaient pas comment sécuriser leurs systèmes d’IA. Pour ces raisons, il est essentiel de sensibiliser les organismes aux problématiques de sécurisation de leurs systèmes d’IA et de proposer des outils d’analyse de risque adaptés.
- Lire l’article P[ɑ̃]nser la sécurité des systèmes d’IA
Sécurité des systèmes d’IA, les gestes qui sauvent
Il existe de nombreuses raisons pour lesquelles il est très difficile de protéger un système d’IA. Ces raisons tiennent aux limitations de ces derniers. Ainsi en raison de leur construction statistique, les modèles d’IA ne sont jamais parfaits. Ils demeurent donc sujets à erreur et exposés à des attaques. Ces comportements peuvent être le fait de données trop peu nombreuses ou déséquilibrées pour la phase d’apprentissage, de limitations des ressources informatiques pour la constitution d’architectures de systèmes toujours plus complexes, etc.
La plupart du temps, les modèles d'apprentissage automatique fonctionnent efficacement, mais seulement sur une portion limitée des données qu’ils sont susceptibles de traiter (en général ayant des caractéristiques très proches de celles utilisées pour l’entraînement des modèles). Ce constat est d’ailleurs l’objet d’une publication de personnels de Google (D’Amour et al, 2020). Ainsi, dans le cas du traitement d’image (computer vision), une très petite perturbation de chaque pixel d'entrée dans un espace de très grande dimension peut suffire à provoquer un changement radical des sorties fournies par le réseau de neurones. Intuitivement, il s’agit donc de déplacer l'image d'entrée vers un point de l'espace que les systèmes d’IA, comme par exemple les réseaux de neurones, n'ont jamais exploré auparavant. Les espaces à haute dimension utilisés sont en effet si peu denses que la plupart des données d'apprentissage sont concentrées dans une très petite région de l’espace connue sous le nom de « variété » (manifold).
Les modèles d'IA peuvent donc avoir un comportement imprévisible et présenter une confiance excessive en dehors de la distribution d'apprentissage, ce qui laisse prise à d’éventuels attaquants. Par conséquent, eu égard aux spécificités introduites par construction par les systèmes d’IA et également aux risques d’attaques auxquels ils sont exposés, il convient de mettre en œuvre un ensemble de bonnes pratiques visant à la fois à réduire l’exposition du système à de potentielles attaques (par exemple en « cartographiant » son périmètre fonctionnel) mais également à améliorer sa robustesse.
- Lire l’article Sécurité des systèmes d’IA, les gestes qui sauvent
Lire le dossier complet au format pdf
Illustration : Flickr cc-by Blue Coat Photos


