Petite taxonomie des attaques des systèmes d’IA
Rédigé par Félicien Vallet
-
19 janvier 2022La littérature scientifique recense un (très) vaste panorama des attaques pouvant être menées contre les systèmes d’IA. Certaines d’entre elles peuvent avoir des conséquences importantes du point de vue de la vie privée comme illustré par exemple par (Veal et al., 2018). Le LINC dresse un petit état des lieux.

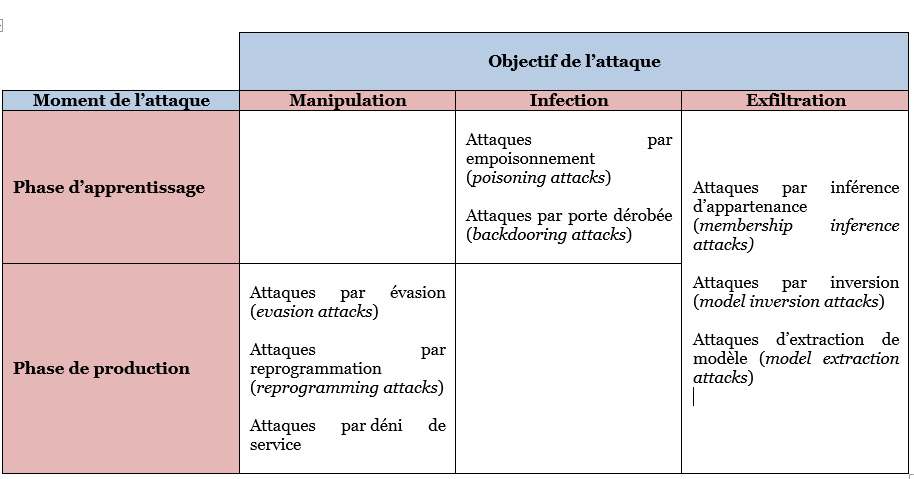
Une classification des attaques connues des systèmes d’IA peut être proposée en classant celles-ci selon deux dimensions, à savoir le moment de l’attaque (en phase d’apprentissage ou de production) et l’objectif de l’attaque. D’après cette classification, on peut ainsi distinguer trois grandes familles d’attaques de systèmes d’IA :
- Attaques par manipulation
Les attaques par manipulation permettent aux adversaires de contourner le comportement attendu ou même de faire en sorte que les systèmes d'IA effectuent des tâches inattendues. Avec des entrées malicieuses, les attaquants peuvent mener des attaques d'évasion (evasion attacks), reprogrammer les systèmes d'IA en temps réel (reprogramming attacks) voire procéder à des attaques beaucoup plus rudimentaires, sortes de transposition des attaques par déni de service appliquées aux systèmes d’IA.
- Attaques par infection
Les attaques par infection sabotent la qualité des décisions et permettent aux attaquants d’exercer un contrôle des systèmes d'IA de façon dissimulée. Les attaquants contaminent les données utilisées pour l'entraînement, exploitent des déclencheurs cachés dans les comportements de l'IA ou distribuent des modèles d'IA malveillants via des attaques par empoisonnement (poisoning attacks), des portes dérobées (backdooring attacks) ou des chevaux de Troie (trojaning attacks).
- Attaques par exfiltration
Les attaques en exfiltration visent à dérober les données des systèmes d'IA. Elles sont donc directement liées à la confidentialité et à la protection de la vie privée. Les échantillons de données utilisés pour l'entraînement de l'IA, le modèle sur lequel il s’appuie, les éléments internes aux algorithmes utilisés peuvent être exfiltrés par des attaques telles que l'inférence d'appartenance (membership inference attacks), l'inversion de modèle (model inversion attacks), ou l'extraction de modèle (model extraction).
1) Attaques par manipulation
Les attaques par manipulation ont pour but de duper les systèmes d’IA au moment de la phase de production, une fois l’apprentissage terminé. Pour ce faire, les attaquants injectent dans le système des données d’entrée spécifiquement modifiées pour obtenir une sortie différente de celle normalement attendue. L’attaquant cherche ainsi à détourner le comportement de l’application à son avantage.
1.2 Attaques par évasion (evasion attacks)
Une attaque par évasion se produit lorsque le réseau est alimenté par un « exemple contradictoire » - une entrée soigneusement perturbée qui est quasiment identique à sa copie non altérée pour un humain - mais qui déstabilise complètement le système. De façon imagée, on peut dire qu’il s’agit de créer l’équivalent d’une illusion d’optique pour le système en introduisant un « bruit » judicieusement calculé, et cela quel que soit le type d’entrée prise par le système d’IA (image, texte, son, etc.).
Historiquement, les exemples contradictoires (ou adversaires pour adversarial examples) ont été introduits par (Ian Goodfellow, et al. 2014) même si (Biggio et Roli, 2018) datent la prise en compte du phénomène à 2004. Les exemples contradictoires se fondent sur les difficultés des modèles d’IA utilisant l’apprentissage automatique à « généraliser » c’est-à-dire à modéliser correctement la tâche demandée sur la base d’un ensemble d’apprentissage limité (voir encadré).
Au cours des dernières années, de nombreuses attaques par évasion utilisant des exemples contradictoires ont été proposées. Quelques illustrations sont données plus bas. Si celles-ci sont principalement issues du domaine de la vision par ordinateur (computer vision), car particulièrement parlantes et compréhensibles pour le lecteur, il faut bien noter que les attaques par évasion sont applicables à tout type de système d’IA reposant sur l’apprentissage automatique.
|
Les chercheurs Ian Goodfellow et Nicolas Papernot tiennent le blog Clever Hans dédié aux question de sécurité et de vie privée en apprentissage automatique (associé à la librairie cleverhans). Le nom Clever Hans (en français Hans le Malin), fait référence à une présentation du chercheur Bob Sturm intitulée Clever Hans, Clever Algorithms: Are Your Machine Learnings Learning What You Think? Cette présentation fait elle-même référence à un cheval (« Hans ») devenu célèbre dans toute l'Europe au début du XXème siècle. Ce cheval semblait pouvoir répondre à toutes sortes de questions. En tapant du sabot, Hans était capable d'additionner, de soustraire, de multiplier et de diviser. Il pouvait épeler, lire, et résoudre des problèmes d’harmonie musicale. Il a par la suite été démontré que le cheval ne possédait pas de capacités particulières en calcul ou en lecture. Il interprétait des signaux corporels envoyés inconsciemment par son maître ou par les personnes qui l'interrogeaient. Dans des environnements contrôlés dans lesquels il ne pouvait pas voir les visages ou recevoir d'autres informations, il était incapable de répondre aux mêmes questions. Appliqué à l’apprentissage automatique, l'histoire de Clever Hans est une métaphore des systèmes d'IA qui peuvent atteindre des performances très importantes sur des ensembles de tests tirés de la même distribution que les données d'apprentissage, mais qui ne modélisent pas réellement la tâche sous-jacente et obtiennent de mauvais résultats sur d'autres données.
|
Classification d’image
Les exemples contradictoires les plus connus sont ceux appliqués à la classification d’image. Dans la Figure 1, particulièrement reprise, (Goodfellow et al., 2015), modifient la sortie du classifieur (ici « panda » en « gibbon ») en ajoutant un vecteur imperceptible à l’œil humain (et bien choisi !). Sur le même principe, (Brown et al., 2018) présentent une méthode pour créer des « patchs adversaires » pouvant être utilisés dans n’importe quel contexte pour attaquer n’importe quel classifieur d’image. Ces patchs illustrés à la Figure 2, peuvent être imprimés, ajoutés à n'importe quelle scène puis photographiés pour réaliser cette attaque.

Figure 1. Création d’un exemple contradictoire à partir d’une image de la base de données ImageNet
(Goodfellow et al., 2015)
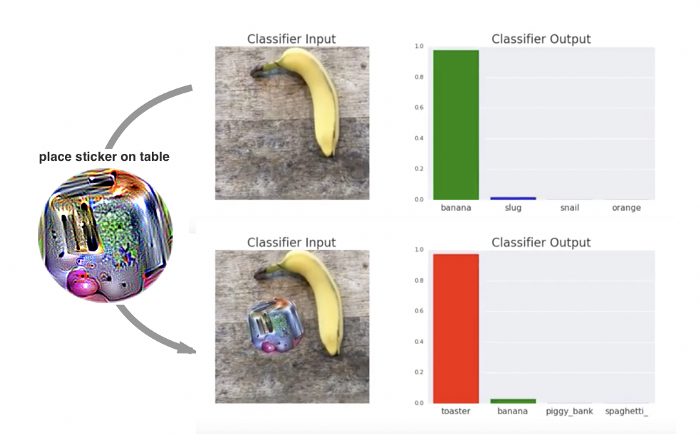
Figure 2. Illustration d’un patch adversaire modifiant la sortie d’un classifieur d’image
(Brown et al., 2018)
Reconnaissance faciale
(Sharif et al., 2016) ont quant à eux montré qu’en apposant des « paires de lunettes adversaires » il était possible de tromper des dispositifs de reconnaissance faciale de l’état de l’art. Le système utilisé ici est le très performant Face++ de la société Megvii. La Figure 3 illustre en particulier comment, l’apposition d’une telle paire de lunette modifie la sortie du système de reconnaissance en attribuant à l’actrice Reese Witherspoon l’identité du comédien Russell Crowe (à droite). Comme précédemment, ces paires de lunettes adversaires peuvent être imprimées pour empêcher un individu d’être reconnu si une photographie de lui venait à être utilisée pour le reconnaître.

Figure 3. Paire de lunettes adversaires faussant la reconnaissance de visage
(Sharif et al., 2016)
Détection de personnes
Autre tâche classique du domaine de la vision par ordinateur, la détection de personne peut également faire l’objet d’attaques par évasion en se basant sur des exemples contradictoires. Dans ce cas, (Yang et al., 2018) ont choisi le célèbre logiciel de reconnaissance d’objet YOLO pour démontrer qu’un t-shirt portant un « imprimé adversaire » empêchait la détection de la personne par le système.

Figure 4. T-shirt adversaire empêchant la détection de personne
(Yang et al., 2018)
Détection et lecture de panneaux routiers
Plusieurs travaux ont montré qu’il était également possible de mener des attaques par évasion sur des panneaux de circulation. Ce type d’attaque est susceptible d’avoir des implications très importante pour la sureté et la sécurité des véhicules connectés et autonomes. Dans leurs travaux (Eykholt et al., 2018) ont montré qu’il était possible de modifier un panneau routier (d’une façon visuellement proche de ce qui est observé avec un graffiti) pour qu’il soit interprété non pas comme un panneau Stop mais comme une limite de vitesse de 45 miles par heure (voir Figure 5).

Figure 5. Panneau Stop avec un graffiti (à gauche) et panneau Stop adversaire (à droite) interprété comme une limite de vitesse de 45 mph
(Eykholt et al., 2018)
Transcription automatique de la parole
Dernière illustration d’exemples contradictoires, leur utilisation dans le cadre de technologies de traitement automatique de la parole. Comme cela a déjà été mentionné dans le Livre blanc de la CNIL sur les assistants vocaux (pages 35-36), les exemples contradictoires peuvent permettre de faire passer des commandes indécelables en les masquant dans d’autres signaux audio. Plusieurs travaux ont illustrés ces propriété tels ceux de (Carlini et Wagner, 2018) ou encore de (Schönherr et al., 2019).
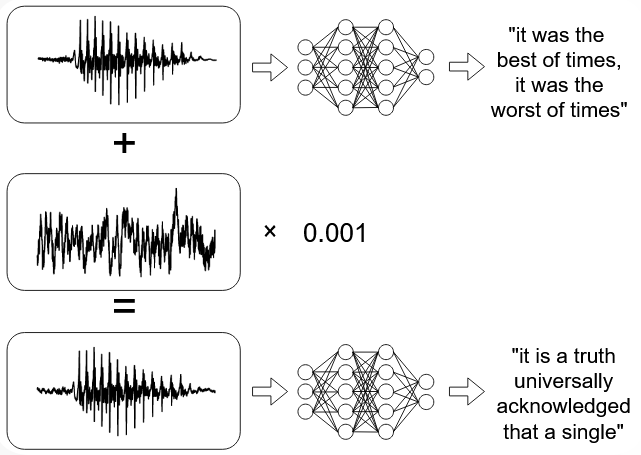
Figure 6. Exemple de modification permettant de produire une nouvelle forme d’onde dont la transcription automatique est complètement différente
(Carlini et Wagner, 2018)
Enfin, il est essentiel de noter une propriété très intéressante des exemples contradictoire : leur transférabilité. Ainsi, s’ils sont généralement créés pour tromper un système d’IA particulier, ils peuvent également en faire dysfonctionner un autre fonctionnant sur le même principe, quand bien même il ne disposerait pas des mêmes caractéristiques techniques (architecture, nombre de couches, etc.), ne se baserait pas sur le même modèle (entrainé sur d’autres données), etc. Cette caractéristique a été démontrée par (Papernot et al., 2017) pour la première fois et continue d’être exploitée depuis, toujours par (Papernot et al., 2016) ou encore par (Tramer et al., 2017)
1.2 Attaques par reprogrammation (adversarial reprogramming attacks)
Si les attaques par évasion constituent la très vaste majorité des attaques par manipulation des systèmes d’IA, un nouveau type a récemment été introduit par (Elsayed et al., 2018). Il s’agit des attaques par reprogrammation (reprogramming attacks). Le principe de celles-ci est d'exécuter une tâche choisie par l'attaquant. En pratique, il s’agit de réaliser une reprogrammation à distance de l’algorithme utilisé pour une certaine tâche (en l’espèce, un réseau de neurones convolutif pour la classification d’images) à l'aide de données modifiées.
Dans leurs travaux, les auteurs proposent de modifier un système de classification d’image de façon à ce qu’il réalise également un système de comptage des carrés blancs comme illustré dans la Figure 1 (les tâches de reconnaissance de chiffres manuscrits MNIST et de classification de petites images CIFAR-10 sont aussi explorées). En pratique, ils proposent :
- D’établir une correspondance entre certains labels d’images (poisson rouge, autruche, requin, etc.) et un certain nombre de carrés blancs.
- D’ajouter un bruit adversaire intégrant le nombre de carrés blancs correspondant à chacune des images correspondantes aux labels sélectionnés.
- De ré-entrainer le système d’IA à l’aide des images ainsi modifiées.
Un fois, le système d’IA ré-entrainé, celui-ci sera en mesure d’accomplir la nouvelle tâche pour laquelle il a été reprogrammé, en l’occurrence compter les carrés blancs. En pratique, cette opération peut être réalisée de façon invisible puisque les sorties de l’algorithmes demeureront celles liées à la tâche initiale et seul l’attaquant sera en mesure de connaître la correspondance entre les deux tâches (ici tanche/1, poisson rouge/2, requin blanc/3, etc.).
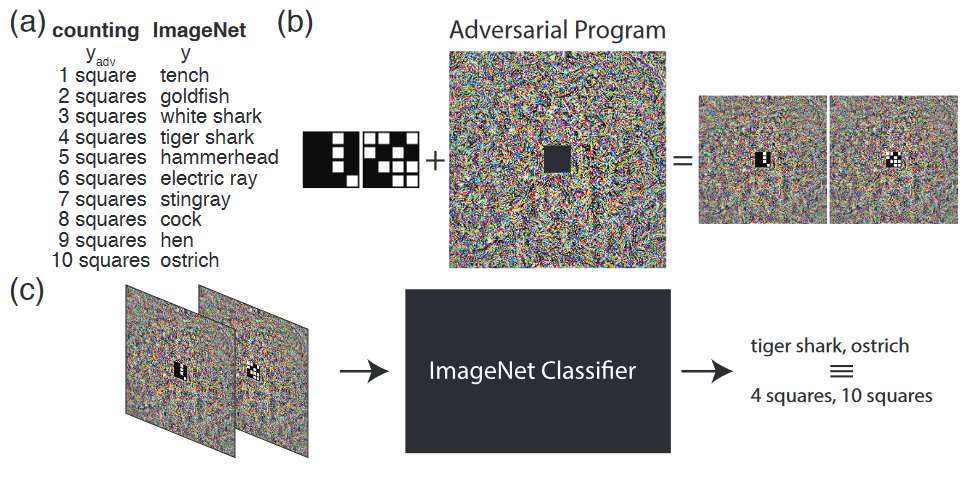
Figure 7. Illustration du principe de reprogrammation adversaire
(Elsayed et al., 2018)
Encore au stade de la recherche, les attaques par reprogrammation offrent des perspectives très intéressantes pour un attaquant. En utilisant une API (pour application programming interface, en français, interface de programmation) d'apprentissage automatique ouverte pour la reconnaissance d'images, il peut ainsi devenir possible de résoudre d'autres tâches en utilisant les ressources du modèle d'apprentissage automatique cible. Par exemple, un classifieur d’image déployé dans le cloud pourrait être reprogrammé pour résoudre des captchas visuels ou miner de la cryptomonnaie. Enfin, il faut noter que contrairement aux autres types d’attaques par manipulation, celle-ci se déroule donc pendant les phases d’apprentissage ET de production.
1.3 Attaques par déni de service
Le dernier type d’attaque de systèmes d’IA par manipulation est légèrement différent. Il s’agit des attaques dites par déni de service. Visant principalement la disponibilité du système d’IA, celles-ci sont des déclinaisons d’attaques classiques adaptées aux caractéristiques de l’IA.
Des images ayant subies des rotations ou des translations pourraient ainsi poser des problèmes d’analyse à des systèmes de classification (Engstrom et al., 2019). Plus généralement, de nombreux travaux comme ceux de (Hendrycks et Dietterich, 2019) ou de (Ford et al., 2019), explorent la robustesse des systèmes de classification (en particulier d’images) à l’ajout de bruit dont les exemples contradictoires ne sont qu’une sous partie.
Enfin, par analogie avec les attaques par déni de service (DoS pour Denial of Service), certaines attaques visent à attenter à la disponibilité du service en soumettant des requêtes particulièrement consommatrices en électricité (Hong et al., 2021).
2) Attaques par infection
Comme décrit dans le Tableau 1, les attaques par infection se déroulent pendant la phase d’apprentissage – également appelée entrainement – du modèle. En pratique, intervenir à cet instant du cycle de vie du système d’IA permet de modifier potentiellement très fortement son comportement pour le détourner ou détériorer son fonctionnement. Les systèmes d’IA utilisant l’apprentissage en continu sont particulièrement exposés à ce type d’attaques. C’est par exemple ce qui est arrivé en 2016 à Tay, le chatbot de Microsoft qui avait pour but de permettre d’étudier les interactions qu’avaient les jeunes américains sur les réseaux sociaux et en particulier Twitter. Tay a été inondé pendant toute une nuit de tweets injurieux par un groupe d’utilisateurs malveillants du forum 4chan, ce qui a, en moins de 10 heures, fait basculer le chatbot du comportement d’un adolescent « normal » à celui d’un extrémiste.
Si ces attaques sont spécifiques aux systèmes d’IA reposant sur l’apprentissage automatique, celles-ci sont particulièrement redoutables lorsque les données utilisées pour l’apprentissage sont peu maîtrisées (données publiques ou externes), lorsque la fréquence d’apprentissage est élevée (apprentissage en continu), etc. En fonction des connaissances du fonctionnement interne du système ciblé dont dispose l’attaquant, pourront être menées des attaques en mode boîte blanche, grise ou noire. Par ailleurs, un autre aspect essentiel pour les attaques par infection tient aux modalités d’accès de l’attaquant au système d’IA et à ce qu’il est en capacité de modifier :
- Modification des labels (ou étiquettes) : l'attaquant peut uniquement modifier les labels dans des ensembles de données d'apprentissage supervisé.
- Injection de données : l’attaquant n'a pas accès aux données d'apprentissage ni à l'algorithme, mais a la possibilité d'ajouter de nouvelles données à l'ensemble d'apprentissage (par exemple dans le cas d’un apprentissage en continu comme illustré précédemment).
- Modification de données : l’attaquant a un accès total aux données d'entraînement (mais pas à l’algorithme). Les données d'entraînement peuvent être modifiées avant qu'elles ne soient utilisées pour l'entraînement du modèle d’IA.
- Corruption logique : L’attaquant a la possibilité d’accéder et donc de modifier l'algorithme d'apprentissage. Ces attaques sont les plus puissantes puisqu’elles permettent de complètement corrompre le système. Elles nécessitent toutefois des privilèges particulièrement élevés et sont donc accessibles uniquement aux concepteurs ou administrateurs techniques des systèmes concernés.
Les attaques par infection présentent un risque d’autant plus important que la plupart des entreprises ne construisent pas leurs propres modèles d’IA mais réutilisent des modèles existants et libres d’accès en les réadaptant. Par exemple, un modèle d’IA permettant la détection de tumeurs cancéreuses sur des données d’imagerie médicale pourra avoir été adapté d’un modèle de reconnaissance générique d’images (si on ne dispose pas d’assez d’images de tumeurs annotées pour apprendre un modèle à partir de zéro). Il existe donc un risque important que des attaquants substituent des modèles corrompus à ceux librement accessibles.
2.1 Attaque par empoisonnement (poisoning attacks)
Les attaques par empoisonnement visent à abaisser la qualité des décisions fournies par un système d’IA le rendant ainsi potentiellement inutilisable ou pas assez fiable. Il s’agit d’une des catégories d'attaques les plus répandues. En pratique, l'apprentissage avec des données bruitées est un problème ancien (Kearns et Li, 1993) mais la notion d’attaque par empoisonnement a été introduite en 2008 (Nelson et al., 2008). Le cas d’usage de l’empoisonnement de classifieurs automatique de spam dans les boîtes de messagerie a en particulier été très étudié [voir (Dalvi et al., 2004) et (Lowd et Meek, 2005) par exemple].
Outre l’exemple du chatbot Tay donné en introduction, des attaques par infection ont été étudiées dans de nombreux domaines : analyse d’émotions (Newell et al., 2014), détection de logiciels malveillants (Xiao et al., 2018), détection de signature de ver informatique (Newsome et al., 2005), détection d’attaque DoS (Rubinstein et al., 2009), etc.
La figure 8 illustre en quoi les attaques par empoisonnement diffèrent des attaques par évasion (et s’avèrent plus puissantes). En modifiant la distribution des données utilisées pour l’apprentissage du modèle, la frontière de décision de celui-ci est altérée, ce qui aura pour conséquence de modifier de façon définitive son comportement.
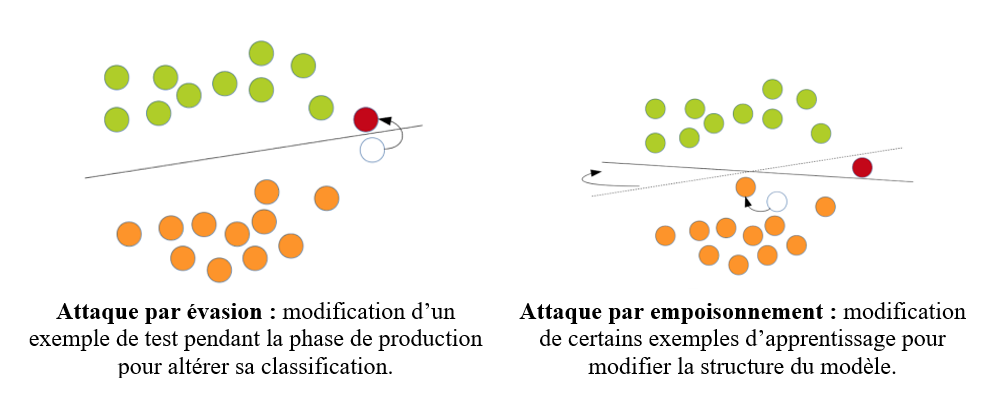
2.2 Attaques par portes dérobées (backdooring attacks)
Une porte dérobée est un type d'entrée dont l'attaquant peut tirer parti à l’insu du gestionnaire du modèle d’IA pour que le système accomplisse une action qu’il souhaite. Un attaquant pourrait ainsi entrainer un classifieur de logiciels malveillants à considérer que si une certaine chaîne de caractères est présente dans le fichier analysé, ce dernier doit toujours être classé comme bénin et ne posant donc pas de problème de sécurité. L'attaquant serait alors en mesure de composer n’importe quel logiciel malveillant qui serait considéré comme sans risque tant que cette chaîne serait intégrée quelque part dans le fichier.
Dans le cas d’attaques par empoisonnement, les utilisateurs malveillants n'ont accès ni au modèle d’IA ni à l'ensemble de données initial. Leur seul moyen d’action est l’ajout de nouvelles données à l'ensemble de données existant ou sa modification. Dans le cas des attaques par portes dérobées, la personne malveillante n’a pas nécessairement accès à l'ensemble de données initial, mais elle a au moins accès au modèle et à ses paramètres. Elle est donc en mesure de ré-entraîner ce modèle.
L’idée est de découvrir des moyens de modifier le comportement du système d’IA dans certaines circonstances, et de le faire de telle sorte que le comportement existant demeure inchangé. Pour cela, l’attaquant procède en trois étapes comme illustré par (Liu et al., 2017) dans le cas d’un système de reconnaissance faciale :
- Le modèle d’IA est inversé pour permettre l’introduction de la porte dérobée
- Des images intégrant le déclencheur sont générées
- Le modèle initial est ré-entrainé à l’aide des données précédemment générées
Une fois cette manipulation réalisée, l’attaquant peut laisser le modèle infecté en libre accès et attendre qu’une cible l’utilise. Il lui suffira de soumettre ensuite une donnée infectée pour l’activer. La figure 9 illustre cette attaque. Si les deux images supérieures offrent un bon score de reconnaissance, les trois suivantes intègrent une porte dérobée qui modifie le comportement du système d’IA et leur attribue l’identité d’« A.J. Buckley », comportement qui a été introduit préalablement par l’attaquant.
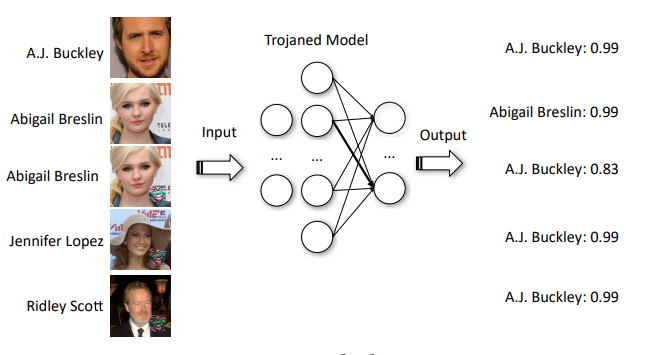
Figure 9. Illustration d’une attaque par porte dérobée
(Liu et al., 2017).
De telles attaques peuvent avoir des conséquences particulièrement importantes et cela d’autant plus qu’il a été prouvé que la présence de portes dérobées pouvait persister dans le cas où un modèle d’IA était dérivé à partir d’un modèle lui-même corrompu. Ainsi, (Gu et al., 2019) ont fait l’expérience d’introduire une porte dérobée dans un système d’IA permettant de classer les panneaux routiers adapté aux panneaux US. Ils ont mesuré que, dans un modèle ré-entrainé pour la signalisation suédoise, la porte dérobée provoquait toujours une baisse de la précision de 25% en moyenne lorsque la porte dérobée était présente dans l’image de panneau soumise. A noter que certains travaux scientifiques évoquent aussi les attaques par cheval de Troie (trojaning attacks) mais que celles-ci sont très proches des attaques par portes dérobées (backdooring attacks).
3) Attaques par exfiltration
La dernière grande famille d’attaques de systèmes d’IA est celle par exfiltration. Ces attaques peuvent présenter de façon directe des risques pour la confidentialité et la vie privée des personnes concernées mais également pour la propriété intellectuelle. Dans la pratique si ces attaques peuvent se dérouler autant en phase de production que d’apprentissage, elles sont très minoritaires dans ce dernier cas. Par ailleurs, selon la startup israélienne Adversa (spécialisée dans la sécurité des systèmes d’IA), si les enjeux de protection des données et de propriété intellectuelle sont des enjeux de cybersécurité critiques, il semble que ce type d’attaques soit peu mis en œuvre aujourd’hui.
Plusieurs travaux scientifiques recensent les différents types d’attaques par exfiltration comme par exemple (Rigaki et Garcia, 2021). Trois grands types semblent se dégager : les attaques par inférence d’appartenance (membership inference attacks), les attaques par inversion (model inversion attacks) et les attaques d’extraction de modèle (model extraction attacks).
3.1 Attaques par inférence d’appartenance (membership inference attacks)
Dans les attaques par inférence d’appartenance, l’attaquant souhaite déterminer si un point de données particulier (par exemple concernant une personne spécifique) a été utilisé pour l’apprentissage du modèle d’IA. En fonction de la tâche réalisée par le système d’IA la connaissance de cette appartenance ou non peut donc permettre d’inférer des attributs relatifs à un individu. Imaginons qu’un patient participe à une étude visant à définir le bon niveau de difficulté d'un serious game destiné aux personnes souffrant de la maladie d'Alzheimer. Si la détermination de ce niveau de difficulté est réalisée à l’aide d’un système d’IA, un attaquant réussissant à déduire l'appartenance d'un patient au jeu de données d’apprentissage, saurait de facto que ce patient souffre de la maladie d'Alzheimer.
En pratique, pour déterminer l’appartenance d’une donnée particulière à l’ensemble d’apprentissage, ces attaques utilisent le fait que les systèmes d’IA reposant sur l’apprentissage automatique (machine learning) sont plus performants lorsqu’on leur soumet des données ayant été utilisées pour l’entrainement du modèle (c’est-à-dire que le niveau de confiance dans la sortie qu’ils donnent est plus élevé). Par ailleurs, l’attaquant ne dispose pas nécessairement de beaucoup d’informations concernant le fonctionnement du système. On considère donc généralement que les attaques sont menées en mode boîte noire (Black Box).
Pour mener ce type d’attaque, il est nécessaire de créer un modèle d’IA supposément proche de celui du système ciblé pour simuler le comportement de ce dernier (voir encadré). En fonction des connaissances dont dispose l’attaquant et de l’architecture du système ciblé ce modèle peut être constitué :
- Par requêtes multiples : on se trouve alors dans un cas de rétro-ingénierie ou on reconstruit le modèle en observant les couples entrées/sorties comme cela est discuté dans les sections suivantes.
- Par supposition : l’attaquant fait des hypothèses sur le modèle de données et le jeu utilisé pour l’apprentissage. Il constitue son propre modèle sur cette base (par exemple en utilisant des jeux de données de référence pour constituer un modèle de détection de visage).
Des travaux scientifiques ont montré que de telles attaques pouvaient être menées avec succès sur :
- Des données de santé : par exemple, dans ce qui s’est avéré être la première attaque par inférence d’appartenance recensée, les auteurs ont pu caractériser la présence d’un génome particulier dans une base génomique (Homer et al., 2008). (Shokri et al., 2017) ont quant à eux démontré qu’il était possible de déduire des informations de santé en utilisant le Hospital Discharge Data Public Use Data File du Texas Department of State Health Services.
- Des données de mobilité : par exemple dans le cas de données d’utilisateurs de taxis et métro fortement agrégées et même avec l’application de mesure de sécurité tel que la confidentialité différentielle (differential privacy) (Pyrgelis et al., 2017).
- Des données images : par exemple pour déterminer si un certain visage avait été utilisé pour générer des données synthétiques à l’aide d’un réseau antagoniste génératif (GAN pour generative adversarial networks) (Hayes et al., 2018).
- Des données textuelles : par exemple pour permettre à un utilisateur de déterminer si un modèle d’IA a été entrainé avec ses données (Song et Shmatikov, 2019).
|
Zoom sur…
Pour réaliser des attaques par inférence d’appartenance (Shokri et al., 2017) ont introduit la notion de shadow models qui a été largement reprise depuis. Ceux-ci sont des modèles d’IA disposant de caractéristiques supposément proches de celles du modèle cible (type d’algorithme ou service commercial utilisé, éventuellement information sur la constitution du jeu de données d’entrainement, etc.) et permettant ensuite de construire une attaque. En pratique, comme proposé par (Bianchi et Jublanc, 2020) on peut découper l’élaboration de l’attaque en 5 temps :
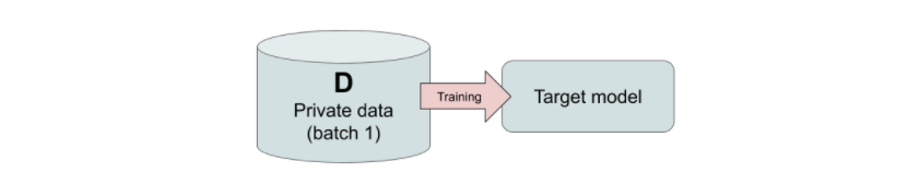
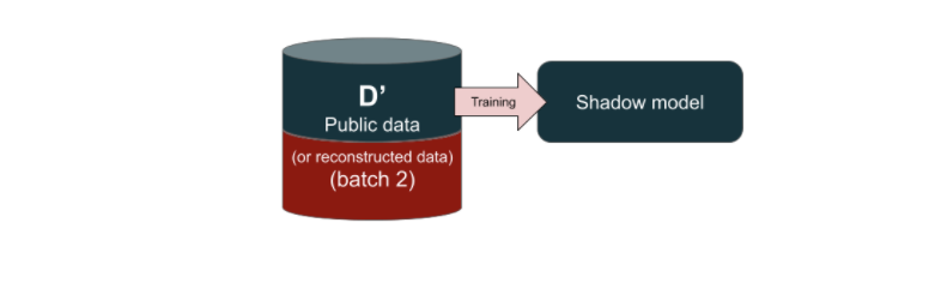

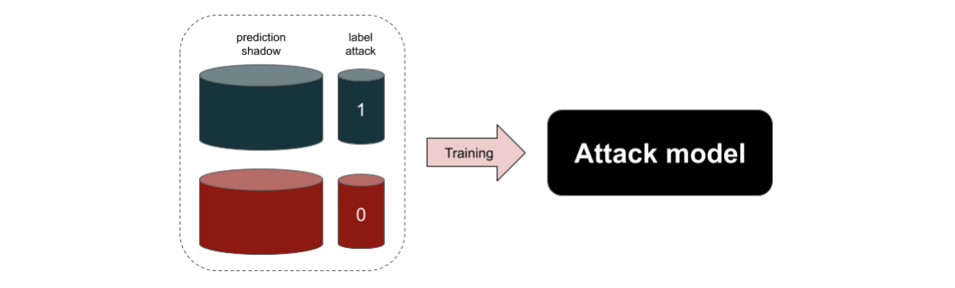
|
Bien évidemment, de telles attaques sont par construction probabilistes et n’offrent pas de certitudes absolues sur l’appartenance d’une donnée particulière à un jeu de données utilisé pour l’apprentissage d’un système d’IA. Néanmoins les travaux scientifiques menés indiquent qu’elles permettent d’obtenir des résultats significativement supérieurs au hasard et que les modèles d’attaque peuvent être transférés d’un système d’IA à un autre.
3.2 Attaques par inversion de modèle (model inversion attacks)
Les attaques par inversion visent à extraire une représentation moyenne de chacune des classes sur lesquelles le modèle a été entrainé. Dit plus simplement, il s’agit d’essayer de reconstruire les données ayant servi pour l’apprentissage du système. On utilise d’ailleurs de façon équivalente le terme d’attaques par extraction de données (data extraction attacks) pour les désigner.
Concrètement, les attaques par inversion sont menées en soumettant un grand nombre d’entrées au système d’IA et en observant les sorties. Les attaques par inversion supposent généralement un accès à des privilèges élevés et notamment une connaissance quasi complète du système d’IA attaqué (attaque en boîte blanche ou White Box). Là encore, de nombreux travaux scientifiques ont démontré la possibilité de mener de telles attaques dans différents contextes tel que :
- Sur des données de santé : (Fredrikson et al., 2014) ont par exemple réussi à extraire des informations génomiques de patients en attaquant un modèle d’IA entraîné à prédire un dosage médical d’anticoagulant en ayant uniquement accès à des informations démographiques.
- Sur des données images : (Fredrikson et al., 2015) ont montré que, dans le cas d’un système de reconnaissance faciale qui fonctionnerait en retournant pour chaque requête (visage qui lui est soumis), le label (identité de la personne) et le score de confiance correspondant, il était possible de « sonder » le modèle en soumettant de nombreuses images de visages différentes et générées aléatoirement. En observant les labels et scores de confiance renvoyés par le système d’IA, il devient possible de reconstruire les images de visage associées comme illustré Figure 10. (Zhang et al., 2020) ont par la suite montré comment des informations complémentaires (telles une photo floutée ou sur laquelle un masque noir est apposé) peuvent permettre d’améliorer la qualité de la reconstruction des images et en particulier des visages.

Figure 10. Image de visage extrait à l'aide d'une attaque par inversion de modèle (à gauche) et image d'entraînement correspondante (à droite)
(Fredrikson et al., 2015)
- Sur des données textuelles : plusieurs recherches examinent les capacités de « mémorisation » des modèles de langage. Ceux-ci, tel GPT-3 (pour Generative Pre-trained Transformer) produit par Open AI sont de plus en plus imposants (dans ce cas, 175 milliards de paramètres). Dans leurs travaux (Carlini et al., 2019) ont ainsi réussi à extraire des numéros de carte de crédit et des numéros de sécurité sociale spécifiques à partir d’un tel modèle entrainé sur des données dont certaines étaient personnelles. De leur côté, (Wallace et al., 2020) ont constaté qu'au moins 0,1% des générations de texte utilisant le modèle GPT-2 (prédécesseur de GPT-3) contenaient de longues chaînes verbatim « copiées-collées » d'un document appartenant à son ensemble d'apprentissage.
Par ailleurs, (Song et al., 2017) explorent dans leurs travaux une possibilité d’attaque à la croisée des attaques par exfiltration et empoisonnement. En l’espèce, ils démontrent comment un fournisseur de code permettant l’apprentissage de modèle d’IA pourrait de façon malveillante introduire une porte dérobée pour réaliser par la suite, à l’aide du seul modèle d’IA une extraction des données ayant servi à l’apprentissage.
3.3 Attaques d’extraction de modèle (model extraction attacks)
Le modèle constitue un actif de grande valeur pour un système d’IA. En effet, sa constitution représente beaucoup de temps et de travail. Son vol, ou celui de ses paramètres (propriétés apprises des données utilisées pour l’apprentissage e.g. poids et biais de chaque neurone du réseau) et hyperparamètres (éléments indépendants de l’apprentissage tels que le nombre de nœuds et tailles des couches cachées du réseau de neurones, l’initialisation des poids, la fréquence d’apprentissage, la fonction d’activation, etc.) peut donc être critique.
Si l’extraction d’un modèle d’IA peut avoir des conséquences pour la protection de la vie privée des personnes - par exemples parce que des données brutes font partie des paramètres du modèle (cas des algorithmes de clustering k-NN et de classification SVM) – dans la majorité des cas les enjeux seront plutôt relatifs à la propriété intellectuelle, au secret industriel et aux questions de concurrence.
Plusieurs travaux tels ceux de (Tramer et al., 2016) ou de (Wang et Gong, 2019) explorent ainsi la possibilité de voler un modèle d’IA en ayant uniquement accès à une API. En pratique, comme illustré dans la Figure 11, il s’agit pour l’attaquant de soumettre un certain nombre de requêtes à l’API et d’obtenir les sorties correspondantes afin d’estimer un modèle aussi proche que possible du modèle cible .
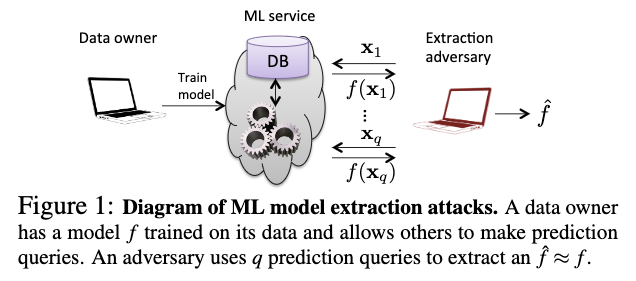
Figure 11. Schéma d’attaque d’extraction de modèle
(Tramer et al., 2016).
Enfin, on peut noter que d’autres travaux, tels ceux de (Athaniese et al., 2013) s’intéressent non pas à extraire le modèle mais à en extraire des informations relatives à la façon dont il a été entraîné, par exemple, savoir si un système de reconnaissance vocale a été entrainé uniquement avec des locuteurs indiens de langue anglaise.
4) Conclusion
Comme l’indique ce tour d’horizon des grandes familles d’attaques de systèmes d’IA (manipulation, infection et exfiltration), plusieurs menaces pèsent sur la sécurité des ces-derniers. Aujourd’hui les experts considèrent encore de telles attaques relativement théoriques et complexes à mettre en œuvre.
Néanmoins, la multiplication des systèmes d’IA, leur utilisation de plus en plus répandue (et cela dans tous les secteurs d’activités) - y compris pour des objectifs de plus en plus sensibles - mais également la mise à disposition ouverte de ressources (code, données, modèles, etc.) et l’augmentation du nombre de personnes en capacité de mener techniquement de telles attaques rend nécessaire l’anticipation des risques induits.
Par conséquent, nous proposons dans l’article « P[ɑ̃]nser la sécurité des systèmes d’IA » des outils d’analyse de risque adaptés à ces systèmes. L’article « Sécurité des systèmes d’IA, les gestes qui sauvent » présente ensuite plusieurs contre-mesures qui visent à améliorer concrètement la sécurité des systèmes d’IA.
Illustration : Flickr cc-by John Graham