
P[ɑ̃]nser la sécurité des systèmes d’IA
Rédigé par Félicien Vallet
-
20 janvier 2022Comme illustré dans l’article "Petite taxonomie des attaques des systèmes d’IA", les systèmes d’IA engendrent des risques de sécurité inédits. Il est donc essentiel de sensibiliser les organismes aux problématiques de sécurisation de leurs systèmes d’IA et de proposer des outils d’analyse de risque ainsi que des mesures adaptées.

Il est indispensable d’appliquer au domaine de l’apprentissage automatique les principes de la sécurité des systèmes d’information (SSI). Ces principes rassemblent l’ensemble des moyens techniques, organisationnels, juridiques et humains nécessaires à la mise en place de mesures visant à empêcher l'utilisation non autorisée, le mauvais usage, la modification ou le détournement des systèmes. Pour ce faire, une approche par les risques est recommandée.
Appliqué au domaine de la protection des données, la CNIL définit dans ses guides PIA, la méthode et PIA, les bases de connaissance ce qu’est un risque sur la vie privée. Celui-ci doit être appréhendé comme un scénario hypothétique qui décrit un événement redouté et toutes les menaces qui permettraient qu'il survienne. Concrètement, un risque décrit :
- Comment des sources de risques (par exemple, un salarié soudoyé par un concurrent)
- Pourraient exploiter les vulnérabilités des supports de données (par exemple, le système de gestion des fichiers, qui permet de manipuler les données)
- Dans le cadre de menaces (par exemple, détournement par envoi de courriers électroniques)
- Et permettre à des événements redoutés de survenir (par exemple, accès illégitime à des données)
- Sur les données à caractère personnel (par exemple, fichier des clients)
- Et ainsi provoquer des impacts sur la vie privée des personnes concernées (par exemple, sollicitations non désirées, sentiment d'atteinte à la vie privée, ennuis personnels ou professionnels).
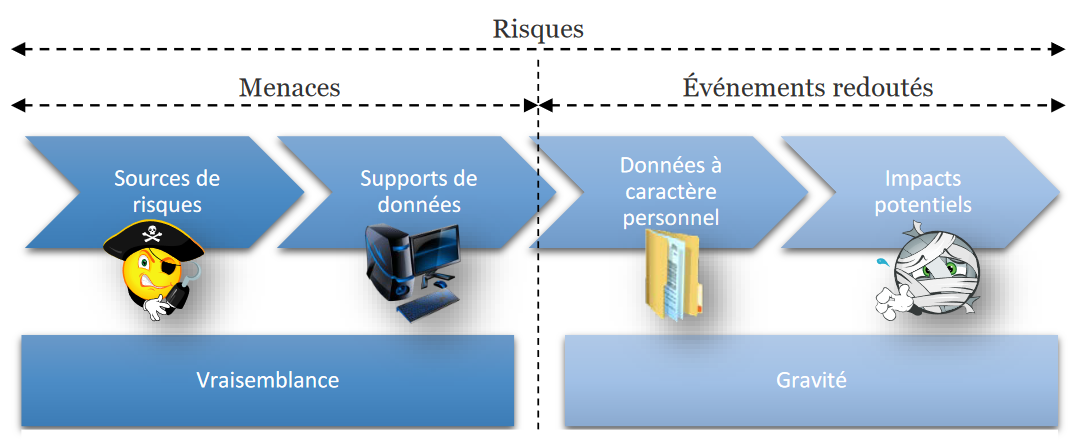
Figure 1. Eléments composant les risques (source guide PIA, la méthode)
Le niveau d’un risque s’estime ensuite en termes de gravité et de vraisemblance :
- La gravité représente l’ampleur d’un risque. Elle dépend essentiellement du caractère préjudiciable des impacts potentiels pour les personnes concernées.
- La vraisemblance traduit la possibilité qu’un risque se réalise. Elle dépend essentiellement des vulnérabilités des supports face aux menaces et des capacités des sources de risques à les exploiter.
Ainsi, pour procéder à une telle analyse appliquée au cas des systèmes d’IA, on peut se poser cinq grandes questions. Celles-ci peuvent être combinées avec certaines approches proposées par des sociétés spécialisées en sécurité des systèmes d’IA comme par exemple CalypsoAI. Les réponses à ces questions permettront ensuite d’identifier et évaluer les risques liés à la sécurité et d’élaborer la politique de sécurité adaptée :
- Qui ? [sources de risque]
Renseigne sur le profil de l’attaquant
- Comment ? [vulnérabilités des supports]
Renseigne sur la façon dont est menée l’attaque
- Pourquoi ? [menaces et motivations des sources de risques]
Renseigne sur les raisons de l’attaque
- Sur quoi ? [descriptions des données et des événements redoutés]
Renseigne sur les données ciblées lors de l’attaque
- Avec quels impacts ? [conséquences pour les personnes]
Renseigne sur les conséquences pratiques de l’attaque
1. Qui ? [sources de risque]
Cette première étape de questionnement vise à déterminer les sources de risque pesant sur un système d’IA. En pratique, pour la gestion de risque sur la vie privée, on distingue les sources humaines (interne ou externe à l’organisme mettant en œuvre le système) et non-humaines (incendies, inondations, etc.). Ici, un focus particulier est mis sur les sources humaines et en particulier externes qui sont qualifiées « d’attaquant » du système d’IA. Les profils d’attaquant peuvent être nombreux et variés et peuvent dépendre de nombreux facteurs : but du système d’IA, organisation qui le met en place, etc. Voici quelques exemples :
- Un utilisateur du système, notamment s’il souhaite en démontrer l’inefficacité (par exemple dans le cas où le système d'IA vient remplacer une tâche manuelle)
- Un chercheur ou un ingénieur éprouvant un système commercial d’apprentissage automatique (potentiellement pour un travail de recherche, comme les attaques sur Metamind, Google, Amazon et Clarifai)
- Un hacker éthique (white hat), par exemple participant à un bug bounty
- Un expert en sécurité informatique (pentester, red teamer, blue hat) réalisant des tests (intrusion, etc.)
- Un hacktiviste attaquant un système d’IA pour démontrer un point
- Un concurrent souhaitant réduire les performances d’un système
- Un hacker mal intentionné (black hat) attaquant un système d’IA pour obtenir un gain financier (que ce soit en déployant réellement l’attaque ou en la vendant à des tiers).
- Un groupe de hackers mal intentionnés (par exemple Anonymous, The Shadow Brokers et Legion of Doom).
- Une organisation financée par un État (dans ce cas, il s'agit principalement de cyberguerre).
2. Comment ? [vulnérabilités des supports]
Pour chaque adversaire peuvent être définies des types de connaissances et d'outils auxquels il peut avoir accès et donc donner une indication sur le niveau de sécurisation attendu. Il s’agit ici de savoir de quelle manière un attaquant pourra effectivement attenter au bon fonctionnement d’un modèle d’IA. En premier lieu, il faut noter qu’un système d’IA est un système d’information comme un autre. Il peut donc également être sujet aux attaques plus « traditionnelles ». Il est recommandé dans ces cas de mettre en œuvre les bonnes pratiques de sécurité et d’hygiène informatique comme proposé par la CNIL dans son guide sécurité des données personnelles ou l’ANSSI. Dans la suite, on s’intéresse uniquement aux vulnérabilités spécifiques aux systèmes d’IA utilisant l’apprentissage automatique. Les moyens de mener des attaques sur un système d’IA peuvent être analysés selon quatre dimensions :
- Le moment de l’attaque
- Les connaissances dont dispose l’attaquant
- Les limitations de l’attaquant
- Les alternatives dont dispose l’attaquant
1.1 Le moment de l’attaque
L'attaque d’un système d’IA peut se produire à différents moments dans la chaîne de traitement. En pratique, on considère deux étapes :
- Pendant la phase d’apprentissage ou d’entrainement : l’attaquant est en mesure d’altérer le processus d’apprentissage du modèle d’IA, notamment en introduisant des données corrompues. Pouvoir attaquer un système d’IA pendant la phase d’apprentissage peut s’avérer très efficace mais est également difficile à réaliser. De nombreuses recherches se sont penchées sur cette question comme par exemple (Kearns et al., 1993), (Biggio et al., 2011) ou (Kloft et al., 2010).
- Pendant la phase d’inférence ou de production : l’attaquant est uniquement en capacité de modifier la donnée d’entrée qu’il soumet au système. Une attaque à ce moment de la chaîne de traitement n’est pas nécessairement très puissante mais est beaucoup plus facile à réaliser. Là encore, on trouve de nombreux travaux scientifiques comme par exemple (Papernot et al., 2017).
1.2 Les connaissances dont dispose l’attaquant
Un attaquant sera en mesure de mettre en œuvre une attaque en fonctions de la connaissance des éléments internes du système d’IA dont il dispose. Plus précisément, on distingue :
- Les attaques en boîte blanche (White Box) : elles supposent que l'attaquant à accès à de nombreuses informations sur le système d’IA : la distribution des données ayant servi à l’apprentissage du modèle (potentiellement l'accès à certaines parties de celles-ci), l'architecture du modèle, l'algorithme d'optimisation utilisé, ainsi que certains paramètres (par exemples les poids et les biais d’un réseau de neurones). De nombreux travaux de recherche font l’hypothèse d’attaques en boîte blanche comme par exemple (Szegedy et al., 2014) (Biggio et al., 2017) ou (Goodfellow et al., 2015).
- Les attaques en boîte noire (Black Box) : elles supposent que l'attaquant ne sait rien du système d’IA contrairement aux attaques en boîte blanche. L’utilisateur ne dispose que des informations de sortie du système. Celles-ci peuvent être de deux types :
- label : l'attaquant reçoit uniquement les étiquettes (ou labels) prédits par le système
- score : l'attaquant reçoit les étiquettes prédites accompagnées de scores de confiance du système
De nombreux travaux, comme par exemple, (Dalvi et al., 2004) ou (Xu et al., 2016) partent de cette hypothèse parfois considérée plus réaliste que les attaques en boîte blanche. Une variation des attaques en boîte noire, dénommée NoBox, consiste à mener l’attaque sur un modèle de substitution, reconstruit sur la base de la compréhension (éventuellement limitée) par l’attaquant du système d’IA ciblé.
- Les attaques en boîte grise (Grey Box) : elles se situent quelque part entre les deux précédentes. Par exemple, l'attaquant peut disposer d’informations sur le modèle mais pas sur les données d’apprentissage utilisées (ou l’inverse).
De façon générale, il est évident que plus un attaquant dispose de connaissances sur un système d’IA et plus il sera en capacité de mettre en œuvre des attaques efficaces.
1.3 Les limitations de l’attaquant
Un attaquant devra également composer son action en fonction de contraintes spécifiques au système d’IA ciblé. On parle alors de limitations et celles-ci peuvent prendre de très nombreuses formes. Par exemple :
- Dans le cas de l’introduction d’un fichier malveillant dans un système d’IA, par exemple en essayant de la faire passer pour « bénin », un attaquant ne pourra modifier celui-ci qu’à certains endroits bien spécifiques, afin de conserver sa fonctionnalité malveillante.
- Pour attaquer un système d’IA déployé dans des dispositifs physiques (voitures, drones, satellites, caméras de surveillance, etc.), un attaquant pourra être limité à la modification de l'entrée dans le domaine physique (à moins de se placer en aval des capteurs physiques du dispositif).
- Pour qu’une attaque au niveau de la phase d’apprentissage du système d’IA soit efficace, deux conditions sont nécessaires :
- Le système doit être régulièrement ré-entrainé sur la base de nouvelles données (sinon, l’attaquant ne sera pas en mesure d’injecter ses données corrompues).
- Le système doit accepter de recevoir des données issues de sources externes (idéalement pour l’attaquant sans qu’un humain n’intervienne pour valider manuellement ces ajouts)
- Pour être menées à bien, de nombreuses attaques nécessitent de pouvoir réaliser des requêtes sans restriction. Par ailleurs, l’accès au score de confiance associé à un décision est bien souvent indispensable, ce qui peut s’avérer complexe à obtenir. Par exemple, la plupart des produits anti-virus du marché fournisse l’étiquette du fichier soumis au système (« malveillant » ou « bénin »), sans donner plus de précisions.
1.4 Les alternatives dont dispose l’attaquant
Enfin, il est essentiel de garder à l’esprit qu’un individu souhaitant attaquer un système d’information se focalisera sur les composants les plus faiblement protégés. En effet, l’attaque des composants au cœur d’un système d’IA n’est peut-être pas le moyen le plus facile pour un individu malintentionné d’arriver à ses fins. Un système d’IA est également un système d’information au sens classique du terme et peut donc également être sujet à des attaques plus « traditionnelles ». Ainsi, si l'objectif de l’attaquant est le vol de données personnelles, l’utilisation de modèles de substitution n’est peut-être pas la façon la plus simple d’y parvenir.
De plus, il peut demeurer une incertitude sur la réussite des attaques spécifiques aux systèmes d’IA, notamment celles qui visent à modifier le modèle ciblé et un attaquant pourra privilégier des attaques aux résultats plus garantis.
3) Pourquoi ? [menaces et motivations des sources de risques]
Pour cette étape, il s’agit de déterminer dans quel but et avec quelles motivations, un attaquant va s’en prendre à un système d’IA. La détermination du but de l’attaquant peut être réalisée en étudiant comment une attaque attente à un ou plusieurs éléments de la triade définie dans la norme internationale de sécurité des systèmes d'information ISO/CEI 27001 :
- la confidentialité : qui a pour but de s’assurer qu’une information n’est accessible qu’aux personnes autorisées.
- l’intégrité : qui a pour but de s’assurer qu’une donnée reste exacte et consistante à travers son cycle de vie ;
- la disponibilité : qui a pour but de s’assurer qu’un système ou une donnée est accessible en un temps défini ;
Une première catégorie d’attaques consiste ainsi à extraire des informations du système d’IA : ces attaques s’assimilent à une perte de confidentialité. Par exemple, un attaquant pourrait vouloir déduire si une donnée particulière (par exemple concernant une personne cible) faisait partie de l’ensemble de données d'entraînement utilisé, par exemple la sortie d'un hôpital comme illustré dans les travaux de (Shokri et al., 2017) sur le Hospital Discharge Data Public Use Data File du Texas Department of State Health Services.
Une deuxième catégorie d’attaques vise à faire commettre au système d’IA des erreurs, préférentiellement de façon discrète, ce qui correspondrait à une perte d’intégrité. Par exemple, un attaquant pourrait vouloir que le classifieur mis en œuvre par un antivirus prenne un fichier malveillant pour un fichier bénin, sans affecter ses performances globales, de sorte que celui-ci demeure non détecté. Les attaques en intégrité peuvent avoir plusieurs sous-objectifs plus ou moins complexes à mettre en œuvre, par exemple :
- Mauvaise classification ciblée : l'attaquant fait en sorte qu'une donnée appartenant à une classe spécifique (par exemple, « malveillante ») soit classée comme appartenant à une autre classe spécifique (par exemple, « bénigne »)
- Erreur de classification : l'attaquant fait en sorte qu'une donnée appartenant à une classe spécifique (par exemple « panneau stop ») soit classée comme n'importe quelle autre classe (par exemple « limite de vitesse 60 » ou « limite de vitesse 45 » ou « chien » ou « humain » ou autre, tant qu'il n'y a pas d'arrêt).
- Mauvaise classification : l'attaquant fait en sorte que les données soient systématiquement mal classées (proche des attaques en disponibilité décrites après)
- Réduction de la confiance : l'attaquant souhaite altérer la qualité des sorties du système d’IA et notamment abaisser les scores de confiance associés (cela peut s’avérer utile lorsqu'un seuil est utilisé, comme dans le cas des scores de fraude). Cela est à rapprocher de l’erreur de classification en tentant de la généraliser à toutes les données soumises.
À noter que si les exemples donnés plus haut sont directement appliqués à des algorithmes de classification, ils peuvent également être déclinés à d’autres types de systèmes comme des modèles de régression par exemple (Jagielski et al., 2018).
Enfin, la troisième catégorie d’attaque vise à mettre le système d’IA complètement hors service. De telles attaques correspondent à une perte de disponibilité. Par exemple, si suffisamment de données de mauvaise qualité, mal étiquetées, etc. sont insérées dans l’ensemble d'entraînement, le modèle appris ne sera plus pertinent et deviendra inutile. C’est l’équivalent de l’attaque informatique classique par déni de service (DoS pour Denial of Service en anglais) appliquée au domaine de l’apprentissage automatique.
4) Sur quoi ? [description des données et des événements redoutés]
Cette nouvelle étape vise à préciser les typologies de données, et notamment de données à caractère personnel, qui sont ciblées lors de l’attaque d’un système d’IA. Le Règlement général sur la protection des données (RGPD) et les différents textes relatifs à la protection des données explicitent plusieurs catégories de données distinctes :
- Les données à caractère personnel d’usage courant
- Les données à caractère hautement personnel (comme définies dans les Lignes directrices du Groupe Article 29 concernant l’analyse d’impact relative à la protection des données (AIPD) et la manière de déterminer si le traitement est «susceptible d’engendrer un risque élevé» aux fins du règlement (UE) 2016/679)
- Les données relatives aux personnes vulnérables
- Les données sensibles (au sens de l’article 9 du RGPD)
- Les données relatives aux condamnations pénales et aux infractions (au sens de l’article 10 du RGPD)
Il convient de relever que ces données peuvent être fournies par la personne, récupérées auprès d’un tiers qui les détenait préalablement ou encore, déduites. En effet, dans de nombreux cas, l’utilisation de systèmes d’IA vise à inférer sur la base des données utilisées pour l’entraînement (de la personne directement ou d’autres personnes), des informations sur la personne concernée. Il peut s’agir par exemple d’informations relative à l’affection ou non d’une pathologie. Il convient donc de s’assurer de l’exhaustivité du recensement des données personnelles en n’omettant pas ces données inférées.
|
Types de données |
Catégories de données |
|
Données à caractère personnel d’usage courant |
Donnée d’état-civil, identité, données d'identification |
|
Données de vie personnelle (habitudes de vie, situation familiale, photos, etc.) |
|
|
Données de vie professionnelle (CV, scolarité formation professionnelle, distinctions, etc.) |
|
|
Données de connexion (adresses IP, journaux d’événements, etc.) |
|
|
Données à caractère hautement personnel |
Données de localisation (déplacements, données GPS, GSM, etc.) |
|
Données relatives aux communications électroniques |
|
|
Données d'ordre économique et financier (revenus, situation financière, situation fiscale, etc.) |
|
|
Données de traitement médico-administratif (numéro de sécurité sociale, etc.) |
|
|
Données à caractère personnel relatives aux personnes vulnérables |
Données concernant des personnes âgées, enfants, personnes en situation de handicap, etc. |
|
Données à caractère personnel sensibles |
Données révélant l'origine raciale ou ethnique, les opinions politiques, les convictions religieuses ou philosophiques ou l'appartenance syndicale |
|
Données génétiques et données biométriques utilisées aux fins d'identifier une personne physique de manière unique |
|
|
Données concernant la santé ou concernant la vie sexuelle ou l'orientation sexuelle |
|
|
Données à caractère personnel relatives aux condamnations et aux infractions |
Données à caractère relatives aux condamnations pénales, aux infractions ou aux mesures de sûreté |
Table 1. Proposition de typologie des données à caractère personnel.
Attenter à ces données donne lieu à un ou des « événements redoutés ». Comme vu dans la section précédente, ces événements peuvent prendre trois formes lorsqu’appliqués à des données à caractère personnel :
- Un accès illégitime aux données. Elles sont alors connues de personnes non autorisées. Il y a atteinte à la confidentialité des données.
- Une modification non désirée de données. Elles ne sont plus intègres ou sont changées. Il y a atteinte à l’intégrité des données
- Une disparition de données. Elles ne sont pas ou plus disponibles. Il y a atteinte à la disponibilité des données.
5) Avec quels impacts ? [conséquences pour les personnes]
Comme indiqué » dans le guide de la CNIL PIA, les bases de connaissance, on distingue généralement quatre niveaux d’impacts pour les personnes à la survenue d’un événement redouté :
- Négligeable : les personnes concernées ne seront pas impactées ou pourraient connaître quelques désagréments, qu’elles surmonteront sans difficulté
- Limitée : Les personnes concernées pourraient connaître des désagréments significatifs, qu’elles pourront surmonter malgré quelques difficultés
- Importante : Les personnes concernées pourraient connaître des conséquences significatives, qu’elles devraient pouvoir surmonter, mais avec des difficultés réelles et significatives
- Maximale : Les personnes concernées pourraient connaître des conséquences significatives, voire irrémédiables, qu’elles pourraient ne pas surmonter
Ces impacts peuvent être précisés en caractérisant leur nature :
- Corporelle : préjudice d’agrément, d’esthétique ou économique lié à l’intégrité physique
- Immatérielle : perte subie ou gain manqué concernant le patrimoine des personnes
- Morale : souffrance physique ou morale, préjudice esthétique ou d’agrément
Appliqué à une attaque menée à l’encontre d’un système d’IA, il s’agit de mener une réflexion visant à mesurer ces impacts le plus honnêtement possible. Ainsi une attaque par inférence d’appartenance réalisée à l’encontre d’un système utilisé pour la caractérisation d’une maladie grave aura un impact moral, potentiellement important, alors qu’une attaque en disponibilité menée à l’encontre d’un système de vision par ordinateur visant à extraire des informations relatives aux émotions des images de visage pourra avoir un impact limité. Et ces impacts diffèreront encore d’une attaque par exfiltration permettant de recouvrir des informations ayant été utilisées pour entrainer un modèle de langage (numéro de carte bleue, de téléphone, adresse, etc.) !
6) Estimer le risque [gravité + vraisemblance]
Une fois que les source de risques et leurs motivations, les vulnérabilités des supports, les données exposées et les impacts potentiels pour les personnes concernées ont été caractérisés, il s’agit d’estimer le ou les risques identifiés. C’est la dernière étape du processus de qualification des risques. Ainsi, pour chaque événement redouté identifié, il s’agit de répondre aux deux questions suivantes :
- « Que craint-on qu’il arrive aux personnes concernées ? » : afin de déterminer les impacts potentiels pour les personnes concernées s'ils survenaient.
- « Comment cela pourrait-il arriver ? » : afin d’identifier les menaces sur les supports des données qui pourraient mener à cet événement redouté et les sources de risques qui pourraient en être à l’origine.
La réponse à la première question permet d’estimer la gravité, notamment en fonction du caractère préjudiciable des impacts potentiels et, le cas échéant, des mesures susceptibles de les modifier. La réponse à la seconde permet, elle, d’estimer la vraisemblance, notamment en fonction des vulnérabilités des supports de données, des capacités des sources de risques à les exploiter et des mesures susceptibles de les modifier. La Figure 2, présente la matrice des risques couramment utilisée pour visualiser ceux-ci ainsi que les conséquences de l’applications de mesures adaptées pour les réduire (il s’agit d’un exemple).
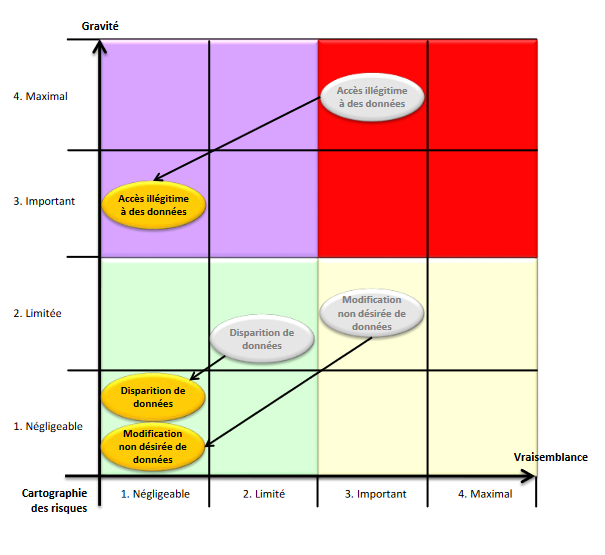
(source guide de la CNIL PIA les modèles).
La caractérisation des risques en fonction de leurs gravité et vraisemblance permettra de déterminer s’ils peuvent être jugés acceptables compte tenu des mesures existantes ou prévues. Si non, il conviendra de proposer des mesures complémentaires et réestimer le niveau de chacun des risques en tenant compte de celles-ci, afin de déterminer les risques résiduels. L’article "Sécurité des systèmes d’IA, les gestes qui sauvent" propose un ensemble de mesures qui peuvent ainsi permettre de réduire les risques induits par la mise en œuvre d’un système d’IA.
Illustration : Oeuvre de Hans-Jörg Limbach - Wikimedia Commons - cc-by - Julian Herzog


