
[Generative AI dossier] - From training to practice : generative AI and its uses
Rédigé par Martin Biéri
-
26 avril 2023As we have seen in previous articles, generative AI raises questions and issues about the underlying models and how they are trained. But what about the "output"? What are the issues involved in using an AI system such as ChatGPT? The risks seem to match the benefits announced by the tool's promoters.

Contents :
- ChatGPT: a well-trained smooth talker (1/4)
- How to regulate the design of generative AI (2/4)
- From training to practice: generative AI and its uses (3/4)
- [LINC Exploration] - The work of AIsterix: AI systems put to the test (4/4)
Speaking precedents and economic stakes for the main platforms
There are a number of precedents before the arrival of ChatGPT that have not necessarily received such a glorious reception. Starting with the perhaps over-hasty announcement and deployment of tools such as the chatbot Tay, launched by Microsoft in 2016. It was withdrawn from the platform a few hours after it went online, due to problematic comments, notably homophobic or anti-Semitic (which had been generated by internet users seeking - at best - to test the limits of AI). As far as Meta is concerned, two launches received mixed reviews in 2022 : the Blenderbot attempt in the summer, followed by a second one for research, Galactica, which received a "vitriolic" reception according to Yann LeCun (head of AI science at Meta). In the academic world, in 2020, a research paper critical of these "large language models" provoked a scandal: some of its authors, Timnit Gebru and Margaret Mitchell, were dismissed by Google after writing it. In 2022, it was a Google engineer who made the headlines, Blake Lemoine, who saw in this AI a conscience - his statements also led to his dismissal. In other words, the subject of the use of language models is neither new nor calmed down...
What's new is that ChatGPT's relative stability, compared with previous attempts, has triggered an "arms race" between the main platforms, not to lose ground. AI image generators (Dall-e, Midjourney, StableDiffusion...) had already won over users during 2022. Leading tech companies must not miss train on AI text generator, or risk seeing the market already conquered by a rival tool. So, after Google's Bard, there's Ernie, launched by China's Baidu, followed by LLaMA by Meta (which was leaked on the Internet!), all of which have yet to be tested by the general public... Announcements of implementation are also multiplying: Microsoft with OpenAI in its Teams tool (to generate videoconference meeting minutes), in Snapchat, and so on. In fact, today only large companies seem to be in a position to take advantage of generative AI in the short term, and companies that have already invested massively in Cloud could have a head start given the estimated cost of requests. Moreover, the cost of entry after establishment of potential regulations (such as the one on AI, currently under discussion at the European Parliament) could be higher. The New York Times also reports on this competition, and in particular the return to prominence of Microsoft, which, unlike its competitors, has chosen to bet with OpenAI on broad language models rather than continuing with its Cortana voice assistant.
This one-upmanship necessarily involves risk-taking, as evidenced by an article in the Washington Post (quoting the New York Times), in which Google is said to be lifting some control rules in order to accelerate the launch of its own tools, following the craze caused by ChatGPT : "Google, which helped develop part of the technology enabling ChatGPT, recently published a "Code Red" regarding the launch of AI products and proposed a "fast track" to shorten the process of assessing and mitigating potential harm". This risk-taking has not always paid off: Bard's reception has been mixed, particularly for factual errors in the presentation of the tool. As regards the protection of data and freedoms, what would be the 'potential damage' beyond the creation of the model and its feeding? It would appear that they are of several kinds, concerning both data security through the facilitation - or even industrialisation - of attacks, and online reputation, through the use of data to generate malicious content.
Challenges of malicious generations, particularly textual, but not only
The way ChatGPT works shows that it is not, properly speaking, a search engine, but a text generator: while it can be precise in its answers, particularly on specific subjects, it does make factual errors. The use of an AI system by the online medium CNET to produce journalistic articles is an example: this type of generative AI was used in order to simplify the writing of articles in finance sections. However, as reported in a Gizmodo article, errors (particularly mathematical ones) have crept into the auto-generated articles - errors that are different from those that a human would make.
Sometimes they are complete inventions, but they are coherent and plausible: truthfulness is not necessarily its primary aim, or at least it may conflict with other major rules developed by the designers - this is Scott Alexander’s hypothesis in his blog Astral Codex Ten. To sum up, there are three of them: give a satisfactory answer, tell the truth - although this is a complex aspect - and do not offend, and the tool's arbitration is sometimes to the detriment of one in order to satisfy another. To the point where less glowing descriptions of ChatGPT are beginning to emerge, such as "bullshit generator". However, it can also generate text 'in the style of' (famous people, artists, politicians, etc.), resulting in some pretty interesting creations! They are a little less interesting when they are used to create messages in the style of the tax authorities or a bank in order to create a phishing email. It wasn't long before they were used in cryptocurrency scams or a fake ChatGPT interface, leading to the download of a Trojan horse.
Tests have also been carried out on ChatGPT's technical knowledge (see our exploration articles) to find out to what extent a chatbot can become a code assistant. The tool's performance seems to be quite good, and therefore sufficient to generate malicious code, enabling it to move on to the next stage in terms of attack. For its part, OpenAI is trying to deter any attempt to use its tool in this way, by ensuring that chatGPT ignores or rejects specific requests. However, it is still possible to access the code production by turning these requests differently, by splitting the request into several pieces, or by using "role-playing", which in some cases makes it possible to overcome the tool’s restrictions. OpenAI company says it is well aware of these flaws, and announces that it regularly "patches" its chatbot to prevent any misuse.
Online reputation, access to information and ChatGPT scalded
Deepfakes have been an issue for several years (see Nicolas Obin's interview on text-to-speech in 2019), but it might take on a new dimension with the possibilities offered by these systems. To some extent, they make it possible to "industrialise" content that could damage people's reputations. As a 'generator', ChatGPT could be a practical tool to create disinformation, since it is capable of putting together a coherent and plausible argument, without necessarily having to be truthful, as we saw above (see the New York Times article on the subject).
A further issue linked to access to information, that is specific to chatbots in general (and voice assistants in particular, as we pointed out in our White Paper published in 2020) is that of the response engine replacing the search engine. The answer is now selected by the tool, not by the user, who can no longer navigate between several links to find the answer they want, or compare different points of view. Added to this is the lack of sources in chatbot's response, making it impossible to verify the information ourselves. The fact that ChatGPT itself can invent sources also obscures its use. ChatGPT was not presented as a search engine: but other generative AIs have been more ambitious. Indeed, Google announced its AI Bard, which has more recent information as it is linked to its search engine, whereas the information on which ChatGPT is trained stops in 2021, the deadline for collecting its training data. But Microsoft quickly responded with a presentation of ChatGPT and Bing, its own search engine. This was not the most convincing of demoonstrations, and there were a few glitches : the chatbot, tested and titillated by journalists, got "angry", with a series of "hallucinations".
There is also a need for proof in both directions, as shown by the impact on the work of some content 'creators' (such as journalists, who have to show their credentials), and justify that their work is indeed 'home-grown', in a 'reverse Turing test'. And this is happening at a time when AI seems to be satisfying some publishers for the publication of "simple" articles, such as Buzzfeed and CNET, mentioned above, as well as the Axel Springer press group and even established media such as the Financial Times (which is already using Midjourney to illustrate certain articles). Magazines are even finding themselves swamped by submissions of articles or content generated by an AI, with some people seeing it as an easy way to make money. Finally, there are also the 'producers' of content, less protected by copyright (see article 2 in this dossier), particularly via blogs or forums. It will be more difficult for them to prove that their content has been used to train a chatbot, or to obtain any form of compensation for their work, whether monetary or in terms of visibility: AI response does not generate a visit to the source site, so no display or subscription is possible (when the sources are not invented!).
Obviously, this applies just as much to images and sound: in the case of the former, exploration is already well under way (with tools such as Dall-e, Midjourney and StableDiffusion). Generation of images is also regulated to avoid excesses, but there are already cases of misappropriation, particularly of women, to generate pornographic content. As explained above, the phenomenon is not as new as all that, but the tools to do it are becoming increasingly accessible and so this kind of misappropriation is also becoming more and more industrialised. As far as voice is concerned, while text-to-speech is not yet as accessible as text and image generation, several news items show that we are getting closer: firstly, a publication by Microsoft that demonstrates the capabilities of its Vall-e tool - without it being possible to carry out tests - and also this hijacking illustrated by the Motherboard media, "How I Broke Into a Bank Account With an AI-Generated Voice". Finally, the first scams generated using an AI system have emerged, as reported by the Washington Post: families receive calls from relatives, whose voices are imitated, asking them for urgent financial assistance (although the first successful attempts date back to 2019). This last point in particular raises the question of 'proof' of speaker recognition, as we already discussed in the LINC article Witness protection: breaking the voice and image.
AI-generated content detection as a solution ? On the internet, nobody knows you're a chatbot
Being able to know whether content has been generated by an AI could be an initial solution to some of the issues listed in this article. Firstly, for the purposes of transparency (for the media using it in particular), but also to know when there are likely to be errors in a text, to avoid attempts at manipulation, or even to be able to tell when an image is not real.
There are two technical ways of doing this: the first is by "watermarking" (watermarking), which makes it possible to know with certainty that the content has been generated. Then, it would be up to the AI designer to leave this imprint. This process seems easier AI image-generator: there could be a mark, visible or invisible to people (which would be automatically detectable in this case). For example, there are already a number of label or signage initiatives. For example, AI Label offers three pictograms: No AI used, Assisted by AI or Made with AI.
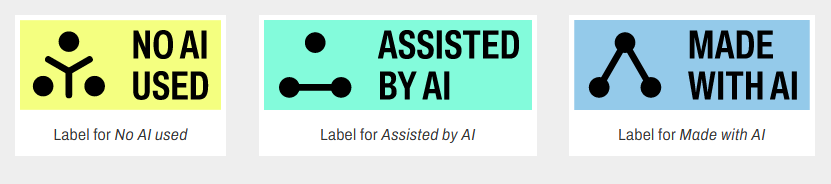
Figure 1: Pictograms proposed by AI Label
This could also be the case in sound or voice generator, with the addition of an audio signal, undetectable to the ear, but which could be automatically recognised by a machine. For texts, it seems more complicated: it could be the insertion of a bias (the recurrent use and choice of specific words, creating a 'pattern' detectable by automatic analysis - see, for example, Kirchenbauer et al, 2023).
The second method is ex-post detection, in which the algorithm is trained to distinguish between texts generated by an AI and texts written by humans. This is what OpenAI is offering, with the launch of AI Text Classifier. Since the launch of ChatGPT, other tools have been developed at the same time, such as DetectGPT and GPTZero. But a lot of problems have arisen, starting with the detection rate. For example, OpenAI's tool is fairly low: 26% of texts generated by AI are correctly labelled as such (for 9% of false positives, i.e. human writings attributed to an AI). Other tools have been put in place by third parties to detect spam generated by ChatGPT.
However, some points remain complex: first of all, it will be necessary to follow the different iterations of chatGPT's model in order to pass on any changes and update the detection system; secondly, the size of the text also affects the analysis. Short extracts necessarily offer fewer guarantees. Both AI Text Classifier and GPTZero state that their tools are, for initial, analysis only, to 'mark' texts that could be written by an AI. What will happen to texts that have been partially modified? Will the watermark hold? A final hurdle is the issue of language. GPTZero, for example, states that its data training is in English...To which we should also add that language fluency is also a discriminating factor for foreigners: a less good mastery of the language, or in any case a more "academic" language could also lead to being classified as an AI in relation to the text you have submitted. There is also the limit of "in the manner of": using a journalistic style (with strong wording such as "what we know about..."). If the aim is to get closer to a human style, marks of difference will be more complicated to determine.
For images, ex-post analysis could be based on what already exists in terms of image retouching analysis: using metadata, the autocorrelation or compression rate of pixels in the image, or learning - as with text - between 'real' images and generated images. This being the case, 'noise' could be added to the image to mislead the analysis or at least render it inoperative: then it would be impossible to know whether the image was real or not. There is some kind of a paradox here: AI systems are better than people at detecting content generated by another AI system.
Transparency and opacity : a return to basics to regain control ?
Actors in the ecosystem are obviously not blind to this potential damage, which is the downside of the possibilities offered by generative AI systems. As an example, the Paterneship on AI initiative, a non-profit organisation that brings together different types of actors (industry, media, civil society, research - including OpenAI, Amazon, Apple, BBC, Berkeley, etc.), has proposed a framework for "developing, creating and sharing synthetic media" (i.e. audiovisual content generated by AI systems). Transparency appears to be a second solution to the challenges listed.
There are also other areas for reflection in terms of deconstructing models in order to understand them better, especially in the case of image-generating AI such as StableAttributionwhich can be used to estimate which images may have fed (and therefore influenced) the AI to produce this particular image. Or Have I been trained, the equivalent of Have I been pwned but for images used in training models, and being able to activate its opposition (although...).
One of the main problems with these AI systems remains their opacity, particularly the choices made in their operating rules. In the case of ChatGPT, these are currently the rules of its designers, but the intervention of one of the founders of OpenAI - or a takeover by a wealthy tycoon - could lead to a reversal in the way things are approached. This is a classic Web 2.0 issue, where standardisation is not necessarily discussed, but 'imposed' by the major players.
Opacity also concerns the conditions under which data is labelled, as well as subcontracting and data transfers. In the first case, it was a revelation in Time that revealed that the labelling process had been subcontracted to Kenya, raising the classic issues of "click work" and the psychological protection of the people responsible for sorting and describing violent content, child pornography, and so on. This news clashes with that of the other major players. This news clashes with the moderation work for Meta carried out in the country, the conditions of which have been denounced by a former moderator from the American firm.
Is regulation necessary ?
If technical measures prove to be limited, the solution could lie in a regulatory approach that provides a more precise framework for the obligations of suppliers of generative AI, in order to clarify the status of generative AI and/or chatbots. This is the objective being pursued by the negotiators of the AI Regulation, who are considering whether to include general-purpose AI and generative AI among the high-risk uses. In France, the report by the Comité Pilote d'Ethique du Numérique on conversational agents issued 13 recommendations, 10 design principles and 11 research questions to be followed for this type of system. Among these, "Asserting the status of conversational agents", "Reducing the projection of moral qualities onto a conversational agent" and "Technically supervising deadbots" are recommendations whose implementation would undoubtedly make it possible to respond to the issues mentioned above.
There remains the question of the effectiveness of the principles established within European user companies in relation to systems designed in the United States or China...
The wide variety of what is encompassed by the term "AI systems" and what they can do means that it is complex to grasp all the issues they raise and the associated risks (some are already trying to measure their impact in different areas of society). The latest additions concerning generative AI systems in the discussions around the AI Act give concrete expression to the problems of regulation: from limiting the risks to adapting uses, depending on the field... Particularly when companies are particularly active in protecting their interests.


