
Protection des témoins : casser la voix et l'image
Rédigé par Martin Biéri & Alexis Léautier
-
04 janvier 2023La question de la protection des témoins n’est pas récente : il existe dans le droit des dispositions permettant de protéger leur anonymat, notamment lorsque pèse sur eux un risque d’atteinte à leur intégrité (ou à celle de leurs proches). Pour autant, les mesures techniques censées garantir cet anonymat par la modification des informations audio et vidéo ont certaines limites, sans cesse repoussées par les progrès technologiques.

La protection de l’identité des témoins
Alors que la protection des lanceurs d’alertes a connu un renforcement avec la loi Waserman en 2022 et la transposition de la directive européenne datant de 2019, la question de la protection de l’anonymat dans les contextes juridiques ou journalistiques reste un enjeu, surtout au regard des progrès de la technologie.
Si des mesures permettant de protéger les témoins étaient présentes en France depuis plusieurs années – pour les protéger d’influence extérieure, comme la subordination de témoin ou d’autres moyens de pression, mais également dans l’usage, comme dans le fait de protéger l’identité des « indics » de la police dans les procès-verbaux –, elles ont été renforcées depuis 2001, permettant notamment d’organiser le cadre légal du témoignage anonyme, « une importante nouveauté inspirée par les procédures accusatoires des pays de common law » (Citoyens et délateurs, 2005). Ainsi, on y trouve de nouvelles dispositions permettant de cacher certaines informations qui présentent des risques pour les témoins. Ces derniers peuvent – par exemple – donner l’adresse du commissariat plutôt que la leur pour ne pas risquer de représailles de la personne qu’ils seraient en train d’incriminer.
Ce renforcement s’est poursuivi en 2016, faisant notamment apparaître quelques précisions techniques. En effet, dans le cadre d’une procédure judiciaire (dans le cadre d’un crime ou d’un délit puni d’au moins trois ans de prison), le témoin peut être amené à comparaître, avec des mesures qui permettent de le protéger d’une réidentification : « Dans certaines circonstances (par exemple si sa sécurité n'est plus assurée), le témoin peut être autorisé à utiliser un nom d'emprunt. S'il est confronté au suspect, cette confrontation se fera à distance. Le témoin ne sera pas visible et sa voix sera masquée. La révélation de l'identité ou de l'adresse est punie de 5 ans de prison et de 75 000 € d'amende » (service-public). Ces nouveaux ajouts sont à comprendre dans le contexte de la lutte contre le terrorisme, et notamment à la suite des attentats de l’année 2015, comme l’indique l’intitulé du texte.
Ainsi, outre le fait de garder secrète l’identité de l’individu (nom, prénom, adresse, etc.), c’est-à-dire de la conserver en dehors ou en parallèle de la procédure, il existe deux manières de le protéger : en « enlevant » son image (le fait d’être visible) et en « masquant » sa voix. Dans le premier cas, le fait de ne pas être présent (à distance) est une mesure assez simple et évidente : l’absence physique de l’individu de l’enceinte du tribunal (par exemple, dans la confrontation) le protège de manière évidente. Il existe ensuite d’autres mesures permettant de dégrader l’image afin qu’elle ne transmette aucune information directement identifiante (floutage ou pixellisation par exemple).
En ce qui concerne la voix, les mesures techniques utilisées sont également assez connues : il s’agit généralement d’opérer une modification de la voix, en la décalant vers les aigus ou vers les graves. Il ne s’agit donc pas spécialement ici d’une dégradation du son, mais bien d’une transposition, ce qu’on appelle le « pitch shifting » (voir également plus bas).
Ces techniques se retrouvent également dans le cadre de reportages télévisés, dans lequel des personnes témoignent en échange d’une protection de leur anonymat, sur des sujets plus ou moins sensibles. Plusieurs dispositifs existent : la personne peut être hors champ ou dans l’ombre, ce qui permet de n’avoir qu’une vague silhouette ; la personne peut être « floutée » (on ajoute un filtre par-dessus l’image ou au contraire, on dégrade plus ou moins la qualité de l’image dans l’optique de masquer ce qui est considéré comme le plus identifiant, à savoir le visage) ; la personne peut être anonymisée par un bandeau noir sur les yeux ; elle peut également être remplacé par un acteur ou un journaliste lisant ses propos – ou ses propos peuvent être simplement écrits sur un carton.
Des limites inhérentes à la technique
La voix
Ces mesures techniques sont-elles pour autant suffisamment efficaces ? D’abord, dans le cadre de la voix, il n’est pas compliqué techniquement de modifier dans le sens inverse pour se rapprocher rapidement de la voix réelle et ainsi pouvoir réidentifier la personne. Cette manœuvre est disponible dans la plupart des logiciels d’édition du son, d’enregistrement ou de création musicale, y compris gratuits. Le « pitch shifting», cette fameuse modulation linéaire du signal, semble donc une mesure de protection extrêmement faible dans le cadre de la protection d’un témoin ou dans celui de la protection des sources. Cette technique pouvait avoir de l’intérêt quand les coûts de rétroingénierie étaient importants et accessibles qu’à un nombre limité de personnes il y a quelques dizaines d’années, ce qui n’est plus le cas avec le passage au format numérique et l’accessibilité des logiciels.
Démonstration d'un pitch shifting : le premier enregistrement est l'original ; le second est l'enregistrement après "déplacement" de 7 demi-tons vers les graves, grâce à un logiciel accessible gratuitement en ligne. Pour autant, l'inversion n'est pas compliquée : en tâtonnant, il est assez simple de revenir à (ou de s'approcher de) l'enregistrement original.
Par ailleurs, la voix est une donnée à géométrie variable (voir le Livre blanc sur les assistants vocaux et nos articles Les droits de la voix) : en plus d’être une caractéristique propre à chaque individu, elle est le support du message transmis. La manière de parler, les tics de langage, l’accent… sont autant d’indices pour pouvoir réidentifier la personne. Et, par extension, nous retrouvons tous les enjeux classiques liés à l’anonymisation des données : enlever les attributs directement identifiants n’est pas forcément suffisant. Il est possible de réidentifier une personne (par inférence ou recoupement) grâce aux informations contextuelles fournies dans l’enregistrement.
L’illustration la plus célèbre de ces failles est la réidentification de Sonia (qui est nom d’emprunt). Cette personne qui avait fourni des informations sur un terroriste et permis d’éviter un attentat en 2015 avait vu son identité révélée. Suite à cela, elle avait été obligée de changer de nom, d’adresse, etc. Cet incident avait par ailleurs mené au projet de loi « Lutte contre le crime organisé, le terrorisme et leur financement, et améliorant l'efficacité et les garanties de la procédure pénale » en 2015, mentionné plus haut.
En parallèle, il est aussi à noter que les liens entre analyse vocale et justice se multiplient : il existe de nouveaux acteurs spécialisés pour épauler les enquêteurs, par exemple. Ainsi, l’entreprise Agnitio, dont le logiciel Batvox est utilisé dans plusieurs services de police en Europe, avait notamment permis d’authentifier la voix de Jérôme Cahuzac dans les enregistrements dévoilés par Mediapart en 2013 et réutilisés par la justice. Par ailleurs, cet épisode avait suscité des réactions dans la communauté scientifique sur la fiabilité des recours à de tels dispositifs dans le cadre de procédure judiciaire : « Malgré les progrès permanents de la Science, les chercheurs du domaine considèrent quasi unanimement que les méthodes actuelles de comparaison vocale sont imprécises » selon J.-F. Bonastre, professeur au Laboratoire d’Informatique d’Avignon et spécialiste du traitement de la parole et de l’authentification vocale (dont vous pouvez trouver l’interview donnée au LINC en 2017 ici). Il rappelle également dans un article intitulé « 1990-2020 : retours sur 30 ans d’échanges autour de l’identification de voix en milieu judiciaire » que les fondements scientifiques des expertises vocales sont contestés par les chercheurs académiques, et qu’une position de la communauté scientifique francophone sur le sujet n’a pas changé depuis le vote d’une motion en 1990. Il est intéressant de noter que des chercheurs participants à des procès le font sous le label de témoins scientifiques et non d’experts judiciaires.
Zoom sur le Voice Privacy Challenge
Les solutions pourraient être à chercher du côté de la synthétisation de la voix, ou des changements de modulation aléatoires et complexes, bloquant la possibilité de retrouver une tonalité fixe et proche de la réalité. L’anonymisation de la voix ou de la parole (speech anonymization) est en effet un sujet de recherche à part entière, comme nous l’expliquait Emmanuel Vincent (Directeur de Recherche au sein de l'équipe Multispeech – Université de Lorraine, CNRS, Inria) en 2020 dans un entretien pour le Livre blanc sur les assistants vocaux : « […] avant d’envoyer les données de l’utilisateur vers la plateforme d’apprentissage, nous transformons la voix et remplaçons certains mots afin que l’utilisateur ne soit plus identifiable. Nos premiers essais nous ont donné du fil à retordre car les outils de biométrie moderne sont extrêmement puissants pour réidentifier l’utilisateur, même après transformation. Nos outils ne garantissent pas une anonymisation parfaite, mais fournissent un niveau de protection très supérieur à l’existant ».
Lors de l’édition 2022 du Voice Privacy Challenge, plusieurs équipes ont proposé des solutions d’intelligence artificielle visant à anonymiser des enregistrements vocaux. Les critères d’évaluation de ces solutions, vérifiés à la fois par un traitement automatisé et par des jurés humains, portaient sur la préservation de l’anonymat de l’orateur et de l’information communiquée. La solution ayant le mieux répondu à ce compromis entre utilité et confidentialité a été proposée par l’Institut du Traitement du Langage Naturel de l’Université de Stuttgart et s’intitule « Cascade of Phonetic Speech Recognition, Speaker Embeddings GAN and Multispeaker Speech Synthesis » (Meyer et al., 2022).
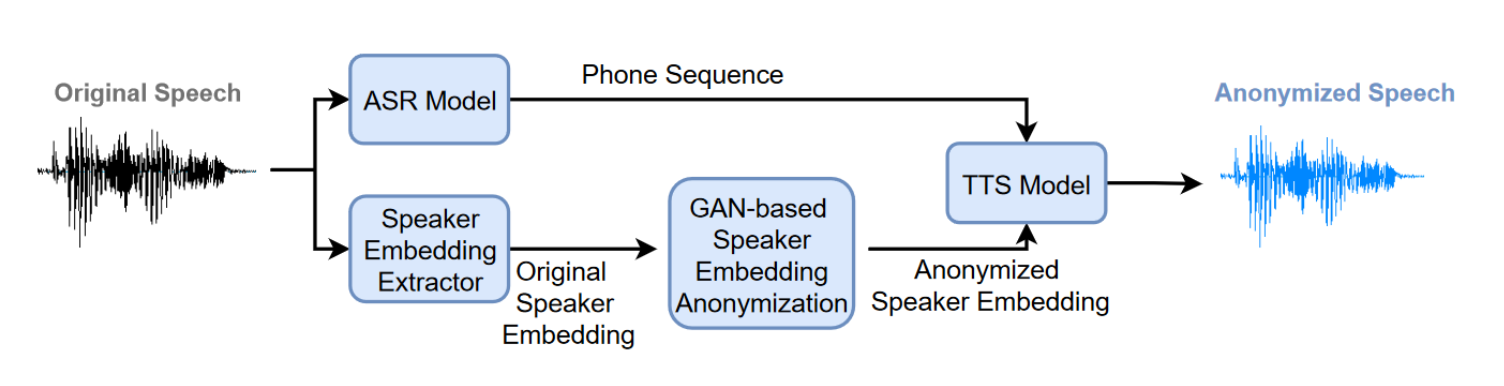
Architecture du procédé utilisé dans Meyer et al. 2022
Dans le premier module de ce procédé, l’enregistrement à anonymiser subit une phase de reconnaissance de la parole, où la parole est transcrite en phonèmes par un algorithme entraîné sur l’ensemble des enregistrements. Bien que les approches usuelles tendent à transcrire la parole en texte plutôt qu’en phonèmes, les auteurs montrent que l’utilisation des phonèmes mène à un taux d’erreur plus faible dans la transcription et facilitent la génération de la parole (qui a lieu dans une seconde phase).
Dans le second module, l’ensemble des enregistrements sonores est utilisé pour produire des encodages de chacun des orateurs. Cet encodage correspond à une représentation mathématique des caractéristiques de chacun des orateurs (selon leur ton, l’alternance de volume dans leur voix, etc.). Ces encodages sont enfin utilisés pour entraîner un generative adversarial network (GAN), qui permettra de produire des encodages synthétiques, c’est-à-dire des représentations mathématiques de la voix de personnes fictives.
Les deux modules précédents sont finalement réunis dans une ultime phase : un algorithme de génération de la voix produit un enregistrement sonore synthétique reproduisant les phonèmes de l’enregistrement à anonymiser donnés par le premier module, selon les caractéristiques vocales d’une personne fictive générée par le second module.
L’image
Côté image, les techniques de traitement semblent moins directement réversibles, à condition la dégradation soit bien réalisée. Il est assez facile de trouver en ligne les outils – accompagnés de tutoriels – permettant de « flouter » ou pixeliser des photographies. Il en va de même pour les vidéos : des logiciels permettent facilement de rajouter un filtre, et même de le lier à un objet ou un visage par la pixellisation. YouTube propose son propre système « Face blur » dans son outil Studio, qui permet donc d’éditer une vidéo déjà téléversée, et, grâce à la détection et suivi de visage notamment, de faire en sorte que ce floutage suive automatiquement la personne ou l’objet reconnu. Bien évidemment, et comme dans le cas de la voix, si la protection ne concerne que le visage, d’autres éléments dans l’image sont susceptibles de donner des indices pour mener une réidentification (et d’ailleurs des recherches tendent à montrer que le visage peut jouer un rôle mineur dans certains modèles de réidentification des personnes). Le fait de ne mettre qu’une barre noire sur les yeux de la personne peut être inefficace au regard d’un algorithme de reconnaissance faciale, qui pourrait trouver sur le visage suffisamment de marqueurs pour identifier la personne.
Pour autant, dès 2000, des études montraient les limites d’une telle anonymisation, d’abord par le fait que le fait d’obfusquer les images n’empêchent pas des individus de reconnaître des personnalités connues. En 2014, le chercheur en deep learning et robotique Dheera Venkatraman publiait sur son blog un post expliquant que le « floutage était une mauvaise idée », et pas seulement pour les visages, mais également pour tous types d’informations contenues dans une image. Et en 2016, une étude pointait que les progrès technologiques pouvaient rendre déjà caduques certaines mesures techniques plus ou moins récentes (McPherson & al., 2016), qu’il s’agisse de la pixellisation (telle que proposée par YouTube notamment) ou de P3 – un système chiffrant une partie de l’image afin de protéger la vie privée des utilisateurs. En effet, par l’entraînement d’un réseau de neurones artificiels, il était possible de passer outre l’obfuscation, et ainsi de reconnaitre visages, objets ou encore des « chiffres manuscrits ». En parallèle, progressent également les technologies permettant d’améliorer la qualité des images (soit de la super-résolution). Ceci permettrait d’avoir une image nette, de plus grands détails dans le cas où une image est floue à cause du mouvement, à cause d’une mauvaise résolution ou lumière. Même s’il s’agit plus ici de finalités de retouches de photographies, cela montre que la technologie permet de plus en plus d’améliorer nettement le rendu des images basse résolution.
Cependant, ces technologies d’amélioration de l’image nécessitent de passer par des outils qui ne sont pas encore accessibles à tout le monde, notamment des GAN – generative adversarial network ou réseaux adverses génératifs en français, à l’origine de portraits réalistes mais de personnes n’existant pas, et dont le fonctionnement avait été expliqué dans notre article sur les données synthétiques. Ce modèle particulier – StyleGAN – a d’ailleurs été réutilisé dans un petit outil qui génère des visages sur des photos pixelisées : https://github.com/tg-bomze/Face-Depixelizer. Le développeur l’ayant mis à disposition a par ailleurs bien en avant qu’il s’agissait de proposition de visages imaginaires et non d’une reconstruction du visage. En attendant, il semble plus sûr de se passer de la pixellisation pour utiliser de la couleur (un gros carré noir sans transparence, par exemple)…
Des enjeux à venir
La consommation de contenus en ligne augmente, et avec elle le nombre de contenus disponibles. Cela est notamment le cas des formats télévisuels grâce à la systématisation du replay (que ce soit sur la plateforme numérique de la chaîne ou bien directement sur une plateforme de partage de vidéo comme YouTube). Cette systématisation entraine de fait l’accumulation de contenus, dont certains contiennent des témoignages dont l’anonymisation ne repose pas sur des méthodes fiables – ou qui seront potentiellement réversibles facilement dans un avenir proche ! Ainsi, si les technologies de demain permettront de réidentifier plus ou moins facilement les individus, notamment dans les reportages, cela devient un enjeu pour les « affaires » particulièrement sensibles pour lesquelles ils existent de nombreuses ressources (voix, images, vidéos), ou de multiples copies (Internet n’oublie jamais) qui auraient échappé au téléverseur originel.
L’accumulation des contenus visuels sur des personnes, dans des images ou des vidéos, a aussi pour effet de rendre de plus en plus facile une éventuelle réidentification, par des outils ad hoc (comme Google Image Search) ou en exploitant les possibilités offertes par l’apprentissage machine (machine learning). Là encore, comme pour le son, la réidentification est aujourd’hui largement plus accessible qu’elle ne l’était dans un monde peu numérisé.
Enfin, dans d’autres contextes, notamment dans le cadre de la retransmission en direct, il peut y avoir une tension entre filmer un événement – à des fins d’information par exemple – et offrir des possibilités d’identification de personnes participant à cet événement. Ainsi, dans le contexte des manifestations et de la répression de celles-ci à Hong-Kong en 2019, des applications avaient vu le jour pour permettre d’anonymiser au maximum les images des manifestants susceptibles d’être collectées par les autorités sur les réseaux sociaux.

