
Partenariat avec le PEReN : les réflexes pour détecter les hyper-trucages
Le Pôle d’Expertise de la Régulation Numérique (PEReN) travaille en partenariat avec le LINC sur un nouveau projet d’étude sur les hyper-trucages (ou Deep Fake). Après avoir fait un état de l’art des techniques existantes et alerté sur la facilité de réalisation de ces vidéos hyper-truquées, nous avons sollicité le PEReN pour savoir s’il est possible pour un humain de détecter des trucages dans des échanges en temps réel.
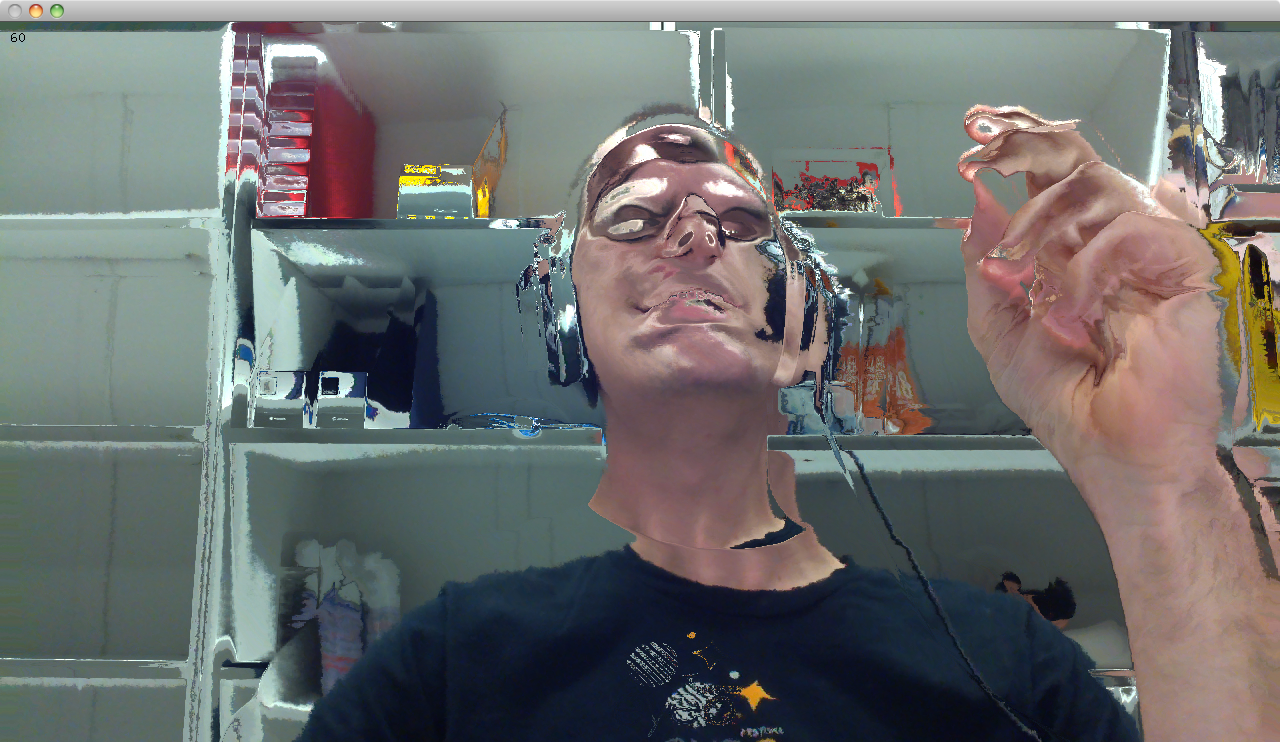
Pourquoi faire cette étude ?
Les hyper-trucages, ou Deep Fake, existent déjà depuis quelques années, mais les premiers travaux avec le PEReN ont permis de montrer que les outils avaient fait des progrès significatifs, facilitant le recours à ces hypertrucages.
En particulier, les récentes avancées ont permis de faire des modifications des vidéo en temps réel, ouvrant la voie à des hypertrucages déployées lors de visio-conférence. Cette possibilité permet de tromper les personnes sur les interlocuteurs avec lesquels elles pensent échanger permettant ainsi de nouveaux scénarios d’escroqueries qui, jusqu’à présent, restaient de l’ordre de la fiction cinématographique.
Face à ce constat, il convient d’identifier une liste de bon reflexes que les personnes peuvent avoir lorsqu’elles suspectent qu’elles sont face à un deepfake. La présente étude vise justement à lister les éléments susceptibles d’aider une personne à détecter qu’elle est face à un hypertrucage.
L’objectif de cette étude est ainsi d’identifier des contre-mesures concrètes à destination d’un utilisateur lambda : quels sont les indices ou éléments visuels auxquels un être humain doit prêter une attention particulière pour détecter efficacement et avec un haut niveau de fiabilité la présence d’hypertrucages ? Existe-t-il des procédures ou gestes qui peuvent être sollicités auprès de l’interlocuteur au cours d’une communication afin d’établir avec un bon niveau de fiabilité que celui-ci est réel ?
Rappel du code pénal, article 226-8
Est puni d'un an d'emprisonnement et de 15 000 euros d'amende le fait de porter à la connaissance du public ou d'un tiers, par quelque voie que ce soit, le montage réalisé avec les paroles ou l'image d'une personne sans son consentement, s'il n'apparaît pas à l'évidence qu'il s'agit d'un montage ou s'il n'en est pas expressément fait mention. Cela s’applique également lorsque le trucage est généré algorithmiquement. La peine s’élève à 45.000 euros et deux ans d’emprisonnement lorsque le montage a été réalisé en utilisant un service de communication au public en ligne.
Lorsque le montage est à caractère sexuel, la peine encourue est 60.000 euros d’amende et 2 ans de prisons (75.000 € et 3 ans de prisons lorsque le montage a été réalisé en utilisant un service de communication au public en ligne).
Les données nécessaires à cette étude
Le PEReN sera amené à générer des hypertrucages dans un volume suffisant pour établir des scénario pratiques et assurer la fiabilité des contre-mesures envisagées.
La génération des hyper-trucages implique d’utiliser des images de visage de nombreuses personnes, et de tenter de les plaquer sur d’autres, dans différentes conditions de posture, de qualité et dans différents médias (vidéo, images, webcam…).
Pour cela, de premiers tests ont été effectués en utilisant les visages de personnes célèbres décédées.
Une nouvelle série de tests repose sur l’utilisation de la base de données FFHQ (Flickr-Faces-HQ). Cette base de données est actuellement constituée de 70 000 photos de visages en haute qualité issues de photos publiées sur Flickr en Creative Commons, et a été créée pour entraîner des GAN (generative adversarial network ou réseaux adverses génératifs en français[1]).
En complément, afin d’identifier les moyens permettant de reconnaître les hyper-trucages et obtenir des résultats robustes, le PEReN doit générer un grand nombre de vidéos « truquées ». Pour cela, il a recours à OpenVid-1M, base de données de référence utilisée pour la génération de vidéos à partir d’un texte. Cette base est constituée d’un million de vidéos :
- des vidéos courtes de visage de célébrités (source : CelebvHQ) ;
- des vidéos générées par l’IA (source : OpenSora) ;
- d’un échantillon de la base Panda-70M (elle-même issue de HD-Vila-100M) composée de vidéos YouTube.
Comment les droits des personnes sont-ils respectés ?
Si vous souhaitez plus d’informations sur ce traitement ou si vous souhaitez exercer vos droits, vous pouvez contacter ip[at]cnil.fr ou adresser un courrier à la CNIL à l’attention du service LINC. Si vous estimez, après nous avoir contactés, que vos droits « Informatique et Libertés » ne sont pas respectés, vous pouvez adresser une réclamation auprès de la CNIL ou de votre autorité de protection des données si vous êtes établis dans un autre pays européen.
Les bases de données d’images et de vidéos qui seront utilisées dans le cadre de ce projet sont listées ci-dessous ainsi que les modalités d’exercice des droits.
| Nom | Type | Source | Description | Licence | Projet | Exercice des droits |
| OpenVid-1M | Jeu de données | https://github.com/NJU-PCALab/OpenVid-1M?tab=readme-ov-file | Video extraited de ChronoMagic, CelebvHQ, OpenSora et Panda | CC-BY-4.0 | Genfake | ip[at]cnil.fr ou via le formulaire CNIL |
| FFHQ | Jeu de données | https://github.com/NJU-PCALab/OpenVid-1M?tab=readme-ov-file | Creative commons | Genfake | ip[at]cnil.fr ou via le formulaire CNIL |
Comment ce projet est-il encadré ?
Ce projet relève de la mission d’intérêt public dont est investie la CNIL en application du règlement général sur la protection des données (RGPD) et de la loi Informatique et Libertés modifiée. Il s’inscrit dans la mission d’information de la CNIL telle que définie dans l’article 8.I.1 de la loi Informatique et Libertés, mais également dans la mission de suivi de l’évolution des technologies de l’information telle que définie dans l’article 8.I.4.
Seuls les membres du Laboratoire d’innovation numérique de la CNIL (LINC) et du PEReN en charge de cette étude auront accès aux données personnelles traitées dans le cadre de l’expérimentation.
Certaines images ou contenus vidéos générés par IA pourront être publiés par la CNIL à des fins pédagogiques et d’illustration, accompagnés d’une mention explicitant qu’il s’agit d’un montage.
Combien de temps durera cette étude ?
Ce projet prendra fin en mai 2026.
Illustration : Photo par Kyle McDonald - Licence CC BY-NC-SA 2.0

