
Le « fingerprinting »
Rédigé par Romain Darous
-
02 juin 2026Le terme de fingerprinting (ou « empreinte ») désigne une technique permettant de caractériser le client qui émet une requête à un serveur à l’aide d’une chaîne de caractères unique. Une empreinte permet en effet d’identifier la machine à l’origine d’une requête et de déduire certaines informations sur ses attributs techniques : navigateur utilisé, adresse IP, utilisation ou non d’un VPN, etc. Cette technique est très utile pour filtrer le trafic web d’un site internet et bloquer les robots qui pourraient s’y connecter, à des fins de moissonnage ou pour conduire des attaques de type DDOS, par exemple.

Cet article commencera par un rappel sur les protocoles de communication web, avant d’expliquer quelles informations peuvent servir à l’identification du client qui accède à un site internet à partir de l’analyse de chaque couche de ces protocoles et de leurs empreintes respectives.
Rappel sur les protocoles de communication web
Un client (l’utilisateur) et un serveur (l’hébergeur d’un site internet) communiquent en suivant des protocoles standardisés, organisés en plusieurs couches : applicative (protocole HTTP), de sécurité (protocole TLS), de transport (protocoles TCP ou QUIC), etc. En examinant les en-têtes des requêtes HTTP et les propriétés du navigateur utilisé, il est possible de vérifier si l’utilisateur est un robot moissonneur, au moyen du calcul des « empreintes » des requêtes (on parle de fingerprinting) et en les comparant avec des empreintes connues.
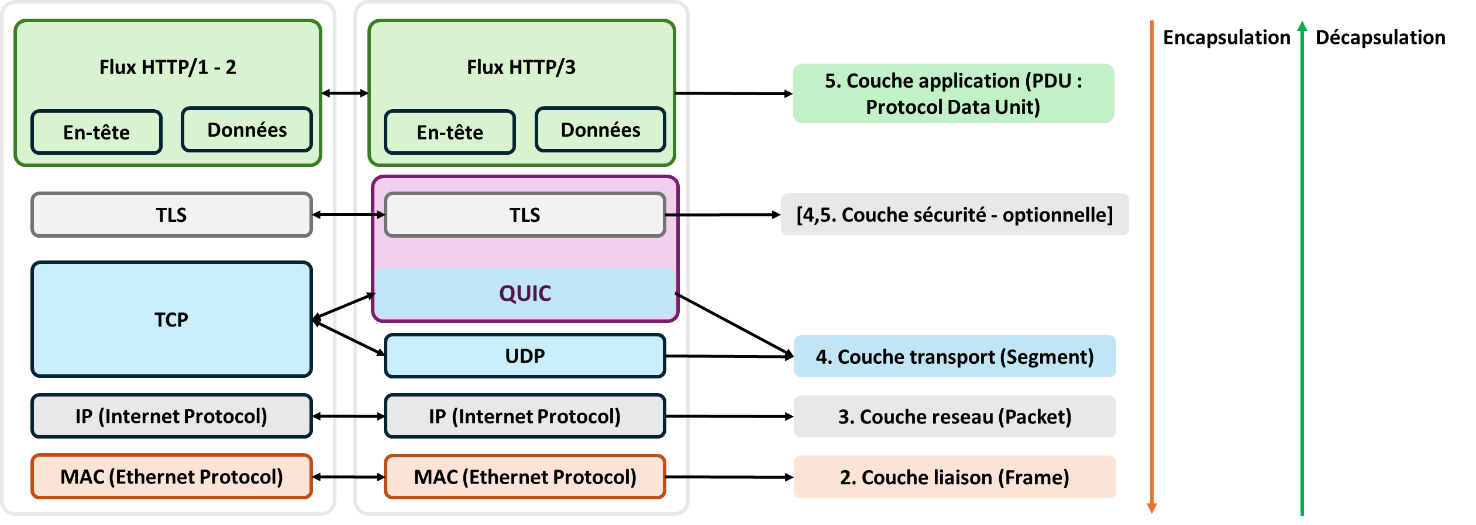
Rappel des protocoles de communication utilisés sur le World Wide Web. Certains sites internet utilisent les trois versions des protocoles HTTP, d'où l'intérêt de les étudier.
Les protocoles de communication Web
Lors de l’envoi d’une requête, un émetteur encapsule ses données progressivement en respectant les protocoles de chaque couche. Pour commencer, les données de l’émetteur sont divisées en unités de taille fixe, appelées « Protocol Data Units » ou PDUs. A chaque couche, un en-tête est ajouté, précisant les modalités de mise en œuvre du protocole, ainsi que les informations d’adressage qui permettent d’orienter la requête dans la bonne direction pour qu’elle atteigne son destinataire. Ainsi, le PDU est encapsulé par des informations des couches :
- Application : l’en-tête contient le nom de domaine auquel l’utilisateur veut se connecter,
- Transport : l’en-tête mentionne le port de l’application émettrice de la requête (un navigateur, par exemple) et le port de destination du récepteur, pour former un « segment » de données ;
- Sécurité (le cas échéant) : à cette étape a lieu le chiffrement du PDU envoyé par le client,
- Réseau : les adresses IP source et destination sont ajoutées pour former un « paquet » de données,
- Liaison : adresses MAC source et destination complètent et forment la requête complète, appellée alors « frame ».
Une requête prend la forme d’une suite de nombres hexadécimaux (une fois déchiffrée), que le récepteur décapsule ensuite en sens inverse.
Avant de pouvoir émettre ces requêtes, un client et un serveur doivent établir une connexion, qui advient au niveau des couches transport et sécurité. Les premiers échanges ne contiennent pas encore de données et se limitent à des segments permettant au client et au serveur de s’identifier et mettre en œuvre leur communication. C’est à ce moment qu’il est possible pour le serveur de récolter des informations sur le client, et donc de détecter s’il s’agit d’un robot ou non. Une fois la connexion établie, les en-têtes de la couche application sont également utiles à cette fin.
HTTP/2 et HTTP/3, quelles différences ?
Jusqu'à la version 2 du protocole HTTP, publiée en 2015, les protocoles de communication web reposent sur une architecture TCP/IP. Le client et le serveur établissent une connexion initiale via la couche transport TCP avant d’échanger des données. Les requêtes doivent être envoyées et reçues dans l’ordre, avec un accusé de réception garantissant la bonne livraison ou, en cas d’erreur, une demande par le récepteur du renvoi des données corrompues. Il s’agit de protocole orienté connexion. Ces protocoles sont également utilisés dans des applications comme l’envoi d’e-mails. Ils offrent une meilleure fiabilité, mais au prix d'une latence accrue.
HTTP/3, proposé en 2018, se distingue par l'utilisation du protocole QUIC, reposant sur UDP comme couche de transport. Le protocole UDP ne garantit ni l’ordre de réception des paquets ni leur accusé de réception au niveau du protocole lui-même. Ce protocole n’est pas fiable malgré le gain en latence. La couche QUIC permet de fiabiliser les requêtes et de s’assurer qu’elles sont toutes transmises sans erreur, dans le bon ordre. Des mesures de contrôle de congestion et de gestion des paquets perdus plus efficaces et une identification plus rapide entre client et serveur permettent de combiner une connexion fiable et plus rapide que pour l’architecture TCP/IP.
Dans la suite sont détaillées les informations qui peuvent être extraites à chaque couche du protocole de communication HTTP. La partie suivante détaille comment ces informations peuvent être utilisées pour détecter des robots moissonneurs.
Informations de la couche transport TCP
Pour les protocoles HTTP reposant sur la structure TCP/IP, l’identification entre le client et le serveur se fait par une poignée de main TCP à trois voies (TCP three-way handshake) : le client envoie un premier paquet SYN (pour synchronized) au serveur, auquel ce dernier répond par un paquet SYN-ACK (synchronize, acknowledge). Ils échangent également leurs paramètres de communication souhaités. Enfin, le client envoie un accusé de réception ACK au serveur (pour acknowledge). La connexion est établie.
Dès le premier échange d’informations avec le client et l’envoi du paquet SYN, il est possible de connaître son adresse IP puis d’effectuer alors un premier contrôle de la réputation de l’adresse IP au moyen de bases de données dédiées. Il est également possible de mettre en place une liste noire d’adresses IP bloquées et de vérifier que la tentative de connexion ne provient pas d’une adresse déjà référencée dans cette liste. D’autres techniques comme le blocage d’adresses IP à l’origine de requêtes anormalement rapides et nombreuses peuvent être mises en place dès que cette dernière est connue.
Il est également possible d’analyser le contenu du segment TCP de la requête SYN pour caractériser le client grâce aux champs :
- Window Size : c’est la taille maximale de données que peut accepter le receveur en mémoire cache avant d’envoyer un accusé de réception (ACK) à l’émetteur,
- Maximum Segment Size (MSS) : c’est la taille maximale des données contenues dans la couche HTTP d’une unique requête pouvant être envoyé par le client,
- Window scale : c’est un facteur multiplicateur qui permet d’augmenter la taille de la fenêtre en la multipliant par ce facteur,
- Etc.
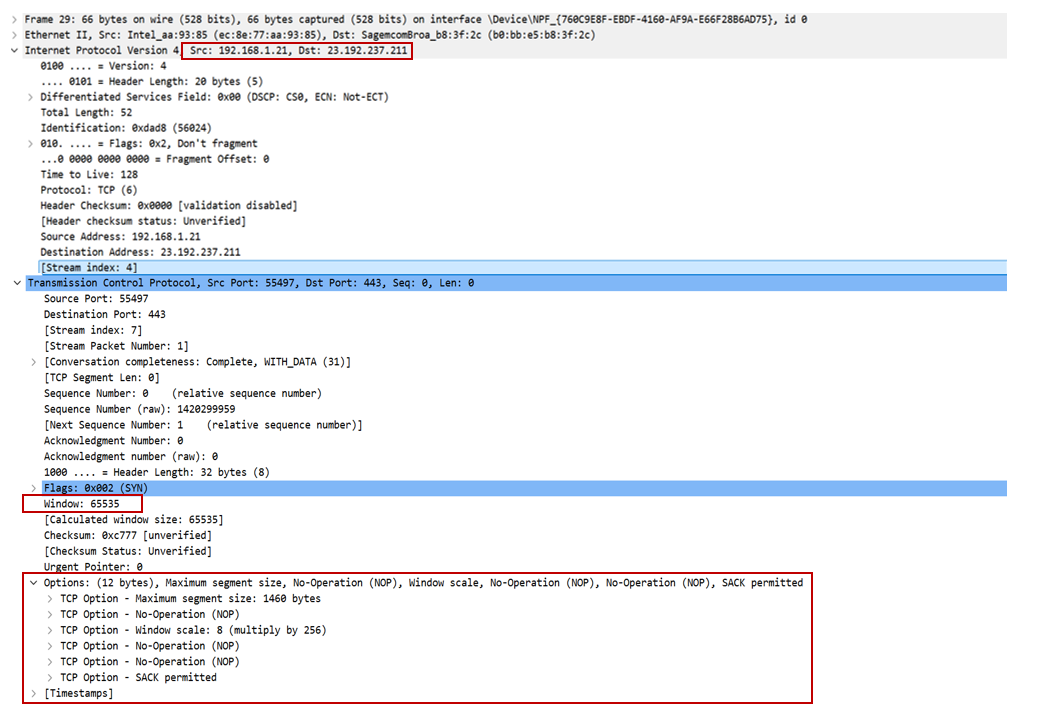
Exemple d'un paquet SYN envoyé par le client, contenant son adresse IP ainsi que des options qui le caractérisent.
L’agrégation de ces informations permet d’identifier le système d’exploitation ou l’appareil du client, ainsi que l’usage éventuel de proxies intermédiaires, de VPNs, etc.
Mise en place du protocole de sécurité
Le protocole TLS (Transport Layer Security) assure la confidentialité et l’intégrité des données échangées sur le réseau. Dans le cas d’un protocole de type TCP/IP, la poignée de main TCP est suivie par une poignée de main TLS, qui permet la sécurisation des échanges. Le client envoie une première requête non chiffrée Client Hello informant le serveur de la version TLS la plus récente dont il dispose (entre TLSv1.2 et TLSv1.3), des algorithmes de chiffrement qu’il peut mettre en œuvre (soit l’ensemble des algorithmes que le client et le serveur peuvent utiliser pour établir la connexion sécurisée : échange de clés, chiffrement des données, etc.). Les communications suivantes permettent notamment d’échanger les clés de chiffrement avant l’échange de données entre les deux machines. En fonction de la version du protocole de sécurité (TLSv1.2 et TLSv1.3), le nombre de messages échangés en clair varie.
La première requête du client au serveur pour établir le protocole de chiffrement n’étant pas chiffrée. Elle permet donc d’établir pour un client donné :
- Les algorithmes de chiffrements (ciphers) pris en charge ainsi que leur nombre,
- Les valeurs des autres champs « Extension » et leur nombre.
L’agrégation de ces informations permet notamment de caractériser la bibliothèque TLS, spécifique à l’application utilisée pour se connecter. Ainsi, il est très probable que des programmes écrits en Python aient la même empreinte TLS, et des programmes spécifiques tels que des clients VPN, un client qui utilise Windows auront respectivement un profil TLS unique.
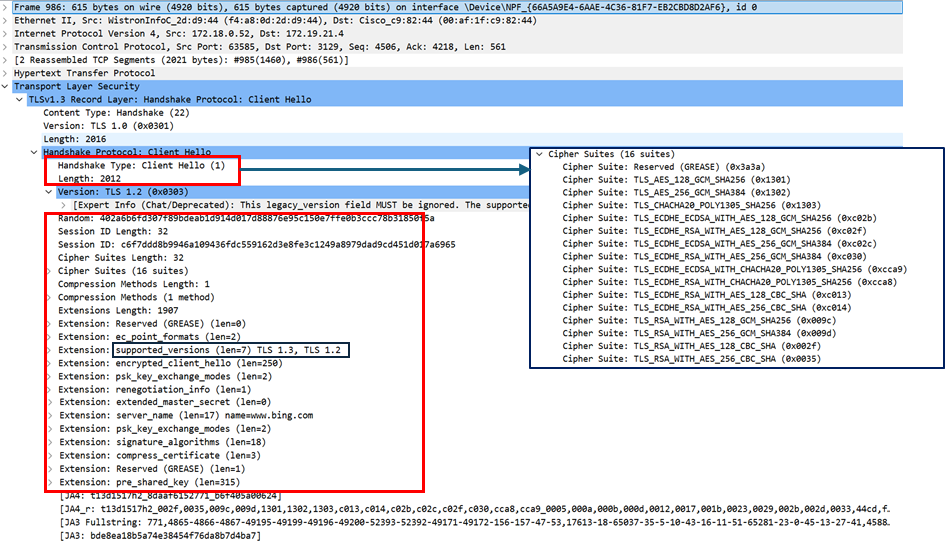
Exemple de segment "Client Hello" lors d'une poignée de main TLS v1.3.
Poignée de main QUIC
Comme expliqué précédemment, le protocole HTTP/3 remplace le protocole de transport TCP par un protocole QUIC/UDP. Une des différences est le remplacement d’un processus à deux poignées de main (TCP puis TLS, pour établir la connexion et son chiffrement) par un processus à unique poignée de main. Elle combine identification du client et chiffrement de la connexion. Ainsi, alors que la poignée de main TCP, ainsi que le début de la poignée de main TLS sont en clair, le chiffrement intervient plus tôt lorsque le protocole QUIC/UDP est utilisé, rendant plus difficile l’extraction d’informations. Cependant, et comme précédemment, le premier message envoyé par le client au serveur reste envoyé en clair. La récolte d’informations est donc similaire à celle présentée plus haut pour les protocoles TCP/IP.
Informations obtenues dans les en-têtes HTTP
Une fois le client et le serveur identifiés et la connexion établie entre les deux, ils commencent à échanger des données, contenues dans la couche application de la requête. Dans le cas du web, le protocole utilisé est le protocole HTTP. Chaque PDU (Protocol Data Unit) contenue dans la requête est accompagnée d’un en-tête qui permet de déceler des informations à propos du client (voir un exemple ci-dessous).
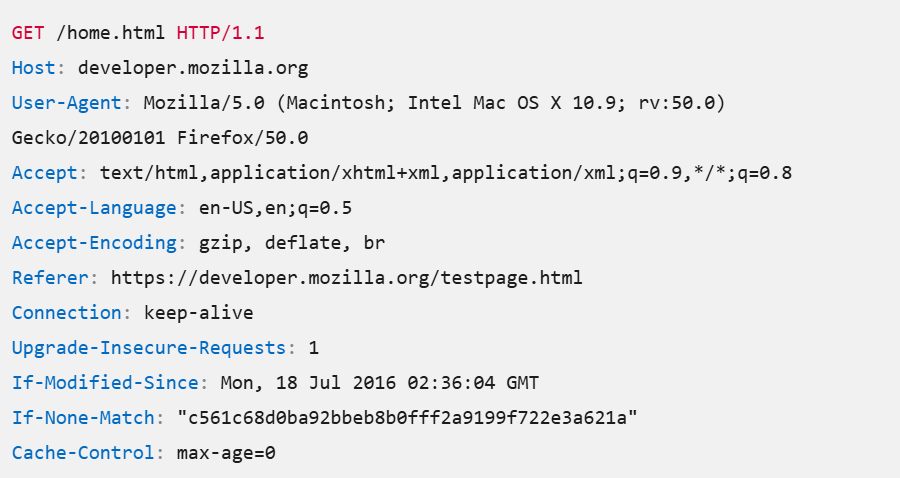
Exemple des informations contenues dans la couche applicative du protocole HTTP/1.1
Les champs de cet en-tête peuvent être analysés pour détecter des robots :
- User-Agent : ce paramètre permet d’identifier l’application, le navigateur ou de manière général l’outil utilisé pour interagir avec le serveur. Ce paramètre peut permettre à lui seul d’identifier un robot, dont le nom peut figurer dans la valeur de ce champ,
- Accept, Accept-Language, Accept-Encoding : ces champs indiquent les types de fichier, les langues et encodages que le client peut traduire,
- Connection : ce paramètre précise si la connexion aux serveurs du site internet doit être maintenue une fois la requête traitée. La valeur keep-alive indique que oui.
- If-Modified-Since permet d’obtenir des informations sur le fuseau horaire du client et donc sur son emplacement,
- Etc.
Un robot peut être détecté par l’absence de champs traditionnellement renseignés par des navigateurs (un champ « Accept-Language » manquant est caractéristique d’un robot), des valeurs anormales ou en repérant le nom du robot dans le champ « User-Agent ». Certaines entreprises qui utilisent des robots moissonneurs rendent public la valeur de ce champ afin de permettre un blocage facile (de manière similaire au remplissage de champ « User-agent » dans les fichiers « robots.txt »).
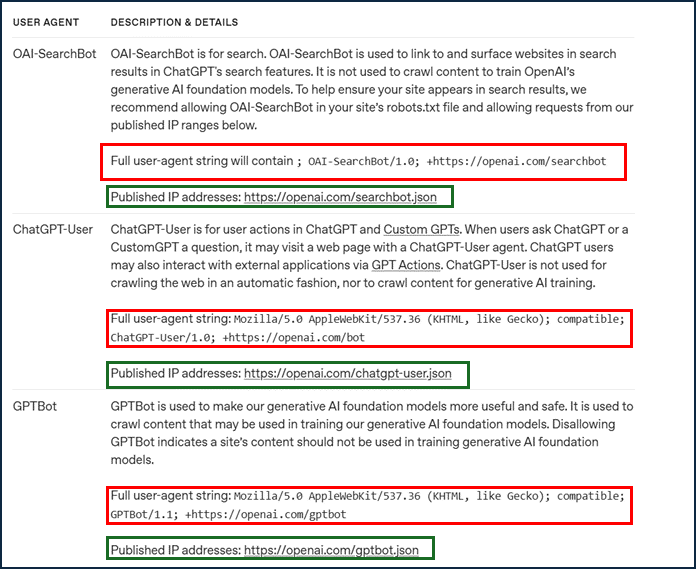
Exemple des champs "User-agent" des robots moissonneurs d'OpenAI. L'entreprise met également à disposition la liste de leurs adresses IP. Il est donc possible de filtrer ces robots par analyse de l'en-tête HTTP des requêtes et par l'adresse IP du client.
Identifier le navigateur par l’exécution côté client
Il est également possible, une fois la connexion établie et l’envoi par le serveur du code source de la page internet à laquelle le client souhaite accéder, d’obtenir des informations sur son navigateur. Le code Javascript de la page web peut être utilisé pour collecter les informations suivantes :
- Versions du système d’exploitation et du navigateur du client,
- Taille d’écran,
- Fuseau horaire,
- Polices installées,
- Technologie de rendu graphique (« WebGL ») utilisée,
- Les plugins ou extensions installées,
- etc.
Cette collecte plus intrusive d’informations à propos du client permet de l’identifier de manière presque unique. L’absence de plugins installés, des technologies de rendu graphique génériques simplifiées, ou l’absence de certains champs peuvent alerter sur la nature robotique de l’utilisateur. La bibliothèque FingerprintJS propose d’ailleurs un outil permettant de vérifier à partir de leurs critères si l’utilisateur qui se rend sur ce site est susceptible d’être un robot.
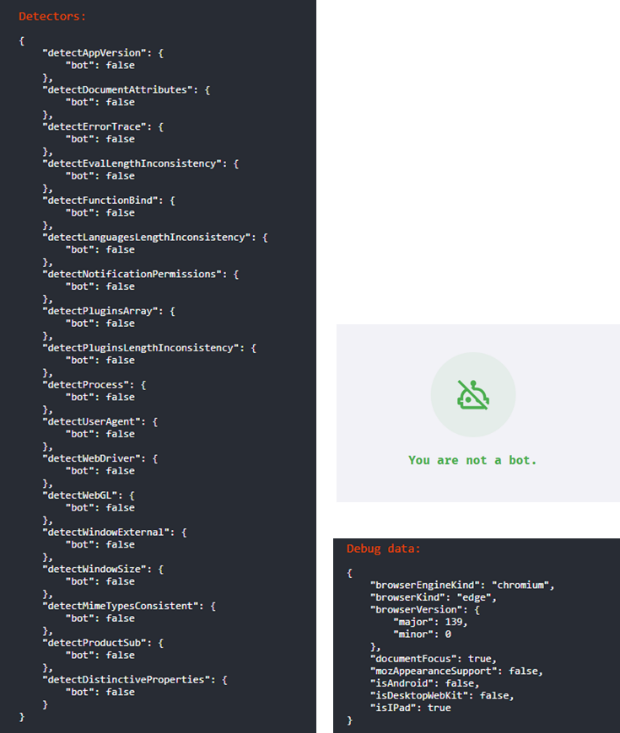
Exemple d'information collectées par la bibliothèque FingerprintJS pour détecter un éventuel robot
L’accessibilité des informations
Les informations extraites de l’examen des en-têtes TCP et TLS lors de l’établissement de la connexion entre le client et le serveur peuvent être collectées avant même le premier échange de données applicatives. Cela permet, par exemple, d’identifier et de bloquer un robot très tôt dans la communication. Par ailleurs, ces en-têtes étant échangés en clair, leur analyse ne nécessite pas d’être effectuée sur le serveur du site internet : elle peut aussi être assurée par des services tiers, comme les réseaux de diffusion de contenu (CDN) ou les pare-feux applicatifs fonctionnant en mode cloud, qui contribuent à surveiller, filtrer et réguler le trafic d’un site web.
A l’inverse, l’examen d’en-têtes HTTP et des informations sur le navigateur nécessite de pouvoir déchiffrer le contenu des requêtes et doivent donc s’effectuer sur le serveur qui héberge le site internet.
Utiliser ces informations : les empreintes
Afin de mettre à profit les informations qui peuvent être extraites lors de l’établissement de la connexion entre un client et un serveur, en examinant les en-têtes des requêtes HTTP, et les propriétés du navigateur, il est utile d’avoir une approche systématisée. Une manière de le faire est d’avoir recours à des bibliothèques qui permettent de calculer des empreintes.
Une empreinte est une chaîne de caractères encodée qui résume un ensemble caractéristique de paramètres observés lors d’une communication réseau. Elle permet d’identifier la machine à l’origine d’une requête et de déduire certaines informations sur ses attributs techniques.
Implémentation des bibliothèques d’empreinte TCP, TLS et HTTP
La bibliothèque JA4+ est une bibliothèque open source qui dispose de plusieurs méthodes permettant de déterminer les empreintes TCP, TLS et HTTP d’un client. A chaque couche, les données obtenues sont triées, concaténées, hachées puis tronquées, afin d’obtenir une empreinte de taille identique pour tous les clients.
Les informations obtenues à une couche donnée peuvent être enrichies par des informations provenant d’autres couches. Ainsi, l’empreinte TLS, en plus des informations sur la version du protocole du chiffrement, le nombre de suites de chiffrements et d’extensions du client, est complétée par les champs suivants :
- SNI (Server Name Identification) : le nom de l’hôte auquel il essaye de se connecter,
- ALPN (Application-Layer Protocol Negotiation) : le protocole utilisé par pour communiquer au niveau de la couche applicative (en pratique, une version du protocole HTTP),
- Si le protocole transport est le protocole TCP ou QUIC.
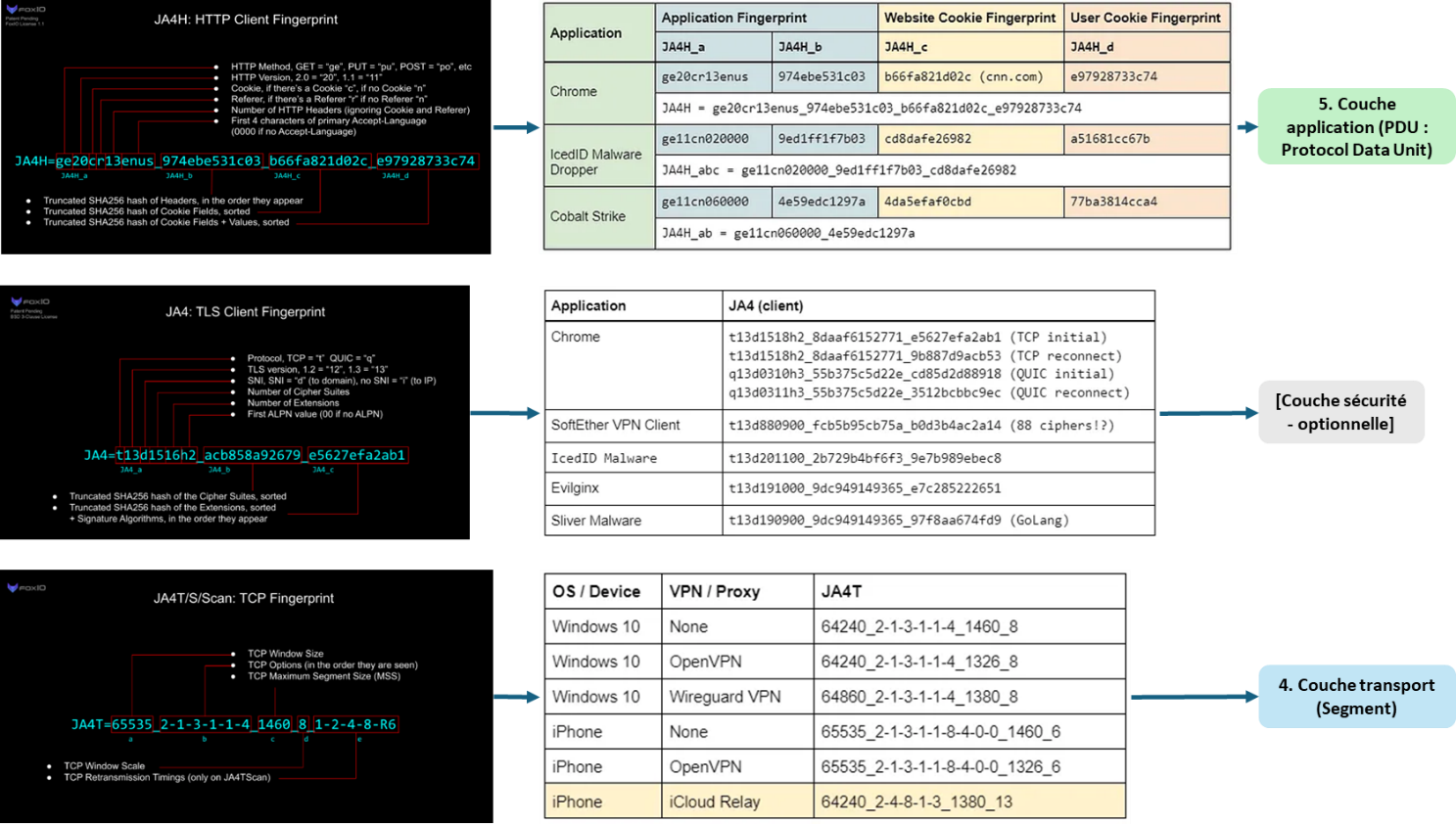
Description des empreintes de la bibliothèque JA4+ et exemples de clients correspondants
Ces empreintes s’utilisent ainsi : une fois l’empreinte d’un client déterminée à une couche donnée, elle est comparée à des empreintes connues. Si elle fait partie d’empreintes considérées comme autorisées à accéder au site internet, la connexion peut s’établir. Sinon, l’adresse IP est bloquée. La bibliothèque JA4+ met pour cela à disposition une base de données qui, pour chaque type de client (caractérisé par l’application utilisée, la bibliothèque TLS, le type d’appareil, le système d’exploitation, l’argument « User-Agent » et l’autorité de certification utilisée), fournit les empreintes que sa bibliothèque met à disposition.
L’analyse d’empreintes permet par exemple de détecter l’utilisation d’un VPN ou d’une bibliothèque TLS d’un langage de programmation utilisé pour faire du moissonnage (Python, JavaScript). Ces informations sont des indices qui peuvent indiquer que le client qui se connecte est un robot. Il est également utile de comparer les empreintes entre elles, pour vérifier la cohérence des informations entre les couches. En effet, certaines empreintes permettent d’obtenir des informations similaires à propos du client, et dénicher des incohérences entre elles peut être un indice de la présence d’un robot, qui a tenté de simuler un utilisateur humain. Un exemple de présentation de la bibliothèque est donné dans l'article du LINC S'opposer au moissonnage en bloquant l'accès au site internet, ainsi qu’un examen plus fin d’empreintes qui permet de déceler l’usage d’un VPN, et donc potentiellement d’un robot.
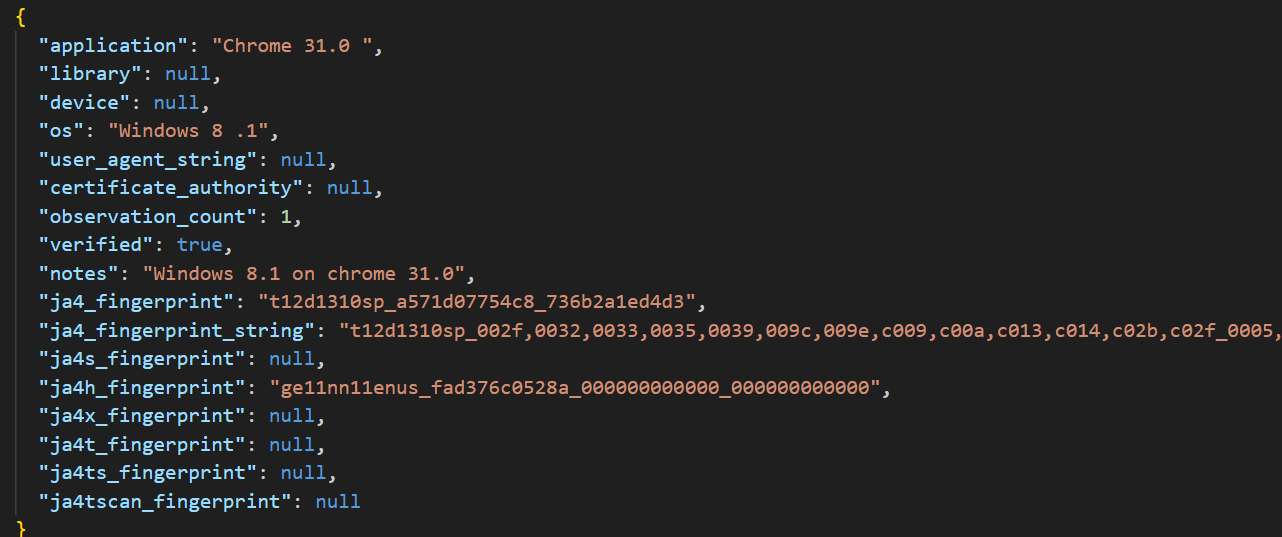
Exemple d'élément de la base de données pour le navigateur Chrome, version 31.0
Implémentation des bibliothèques d’empreinte navigateur
Concernant l’implémentation d’empreintes navigateur, il existe la bibliothèque FingerprintJS. Elle met à disposition un module spécifique dédié à la détection de robots à partir de son empreinte navigateur.
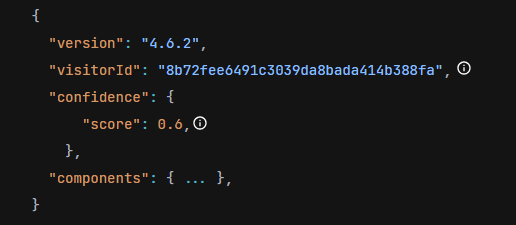
Exemple d'identification du client (champ "visitorId" calculé à l'aide de la bibliothèque FingerprintJS, ainsi que la fourniture d'un score de confiance).
Conclusion
Le fingerprinting constitue donc un moyen efficace d’identifier le client qui tente de se connecter à un serveur. Bien qu’aucune méthode ne soit totalement infaillible, l’analyse et la comparaison des empreintes issues des différentes couches du protocole HTTP — à la fois avec des empreintes reconnues comme fiables et entre elles afin d’en vérifier la cohérence — permettent de réduire au maximum les accès non autorisés à un site web.
Illustration : Nano Banana 2


