
Chacun chez soi et les données seront bien gardées : l’apprentissage fédéré
Rédigé par Alexis Leautier
-
25 janvier 2022L’approche classique consistant à mettre en commun les données d’entraînement collectées localement afin d’entraîner un modèle algorithmique s’avère parfois irréalisable en pratique pour des raisons de protection des données, de propriété intellectuelle, ou encore de logistique. Afin de contourner ce problème, des approches distribuées ont vu le jour.

En avril 2017, Google publie sur son blog dédié aux avancées en intelligence artificielle un article intitulé Federated learning : collaborative machine learning without centralizing training data dévoilant que l’entreprise expérimente une méthode d’apprentissage fédéré sur les téléphones Android. L’article explique comment, sans centraliser l’historique des internautes, elle parvient à améliorer son algorithme de recommandation de contenu GBoard, qui propose du texte, GIF et émoticônes lors de la saisie ou encore des résultats de recherche sur internet.
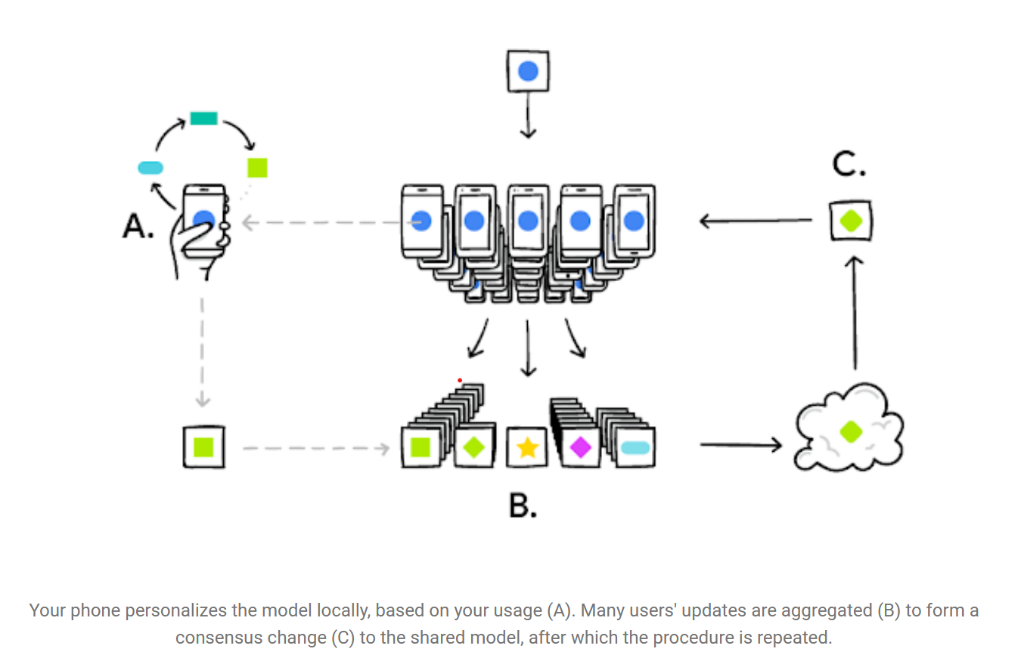
Traduction : Votre téléphone personnalise l’algorithme localement, grâce aux informations liées à votre utilisation (A). Les mises à jour apportées à l’algorithme chez plusieurs utilisateurs sont agrégées (B) pour trouver
un nouveau modèle consensuel (C), après quoi le protocole est répété.
Figure 1 : Apprentissage fédéré tel qu'illustré dans le blog de Google AI
(source)
En pratique, chaque smartphone entraîne localement un modèle de recommandation sur la base des interactions de son utilisateur puis renvoie les paramètres de ce modèle à une entité centrale qui collecte les retours de tous les smartphones et détermine une itération optimale du modèle, qu’elle renvoie à tous les smartphones pour réitération du processus.
Si cet article marque la date à laquelle l’intérêt des industriels s’est porté sur ce sujet, la technologie a connu de nombreux développement avant cela. En 2016, une publication de la même équipe de chercheurs introduit le terme de federated learning à l’occasion de la conférence Private Multi‑Party Machine Learning organisée par la fondation NeurIPS (anciennement NIPS), reconnue comme l’un des évènements les plus prestigieux dans la recherche en Machine Learning.
Alors que d’autres publications soumises lors de cette même conférence semblent proposer des solutions similaires, telles que le distributed learning, c’est d’une part la capacité de Google à expérimenter la solution à très grande échelle rapidemment qui lui aura procuré une position dominante dans la recherche sur ce sujet. D’autre part, la présence d’un centre orchestrateur qui constitue la distinction technique principale de l’apprentissage fédéré, notamment en comparaison avec l’apprentissage distribué, lui confère un plus grand potentiel de généralisation et lui aura permis de se distinguer. Le développement de Tensorflow Federated au sein de l’outil Tensorflow (bibliothèque en sources ouvertes de développement pour l’apprentissage automatique développé par Google) largement utilisé dans le domaine lui aura à son tour permis de sécuriser cette position dominante face à d’autres acteurs tels que Facebook, qui développera ensuite des fonctionnalités similaires dans l’outil PyTorch, une bibliothèque logicielle Python open source d'apprentissage machine. Les autres bibliothèques et outils les plus populaires en apprentissage machine sont SciKitLearn (en sources ouvertes - développé par Inria) et Keras (Google) qui repose sur Tensorflow.
Un protocole nouveau : l’apprentissage fédéré
Techniquement, de quoi s’agit-il ?
L’apprentissage fédéré consiste en la division de la tâche d’entraînement d’un algorithme sur plusieurs machines, désignées comme les machines distantes dans la suite, pour enfin réunir chacun des paramètres locaux en un résultat unique consolidé dans un centre orchestrateur. Les algorithmes concernés, la nature des machines ainsi que les méthodes utilisées peuvent être très diversifiés. On trouve ainsi dans la littérature l’application de cette technique à l’entraînement de régressions linéaires comme de réseaux de neurones, entre quelques serveurs comme entre des millions d’ordiphones.
Plusieurs types d’apprentissage fédéré existent selon la configuration rencontrée. On distingue notamment les configurations cross-silo ou cross-device, horizontal ou vertical, décrites dans cet article de blog de l’organisation OpenMined. L’apprentissage sera cross-device lorsque les machines concernées sont des appareils tels que des smartphones : chacun possède peu de données et de faibles capacités de calcul mais le nombre d’appareils est très important. Dans le cas d’un apprentissage cross-silo en revanche, les machines distantes sont des serveurs moins nombreux mais possédant une quantité de données et des capacités de calcul plus importantes. L’apprentissage horizontal désigne le cas où les données détenues par chaque machine sont de même catégorie, comme pour la recommandation de livres à partir des lectures de plusieurs bases d’utilisateurs, alors que dans le cas vertical chacune possède une catégorie de données propre, comme par exemple le profilage de personnes à partir de leurs goûts musicaux, littéraires, et cinématographiques. Les cas cross-silo et cross-device existent aujourd’hui, en revanche si la configuration horizontale a été largement explorée, la configuration verticale est moins souvent rencontrée.
Si les techniques utilisées sur les machines distantes pour l’apprentissage sont les techniques habituelles d’apprentissage en machine learning, en revanche, des méthodes spécifiques ont dû être développées afin d’agréger les mises à jour au sein du centre orchestrateur. Ainsi, on trouve le federated stochastic gradient descent (FedSGD), qui implique des coûts de communication importants car les paramètres sont partagés entre les machines distantes et le centre orchestrateur à chaque itération. Le federated averaging (FedAvg) vient résoudre ce problème en ne partageant qu’une moyenne des paramètres, calculée après plusieurs itérations, ce qui réduit drastiquement le nombre de communications nécessaires. A titre d’illustration, l’entraînement du modèle de GBoard décrit dans cette publication nécessite 3750 itérations avec FedSGD contre 280 avec FedAVG pour un même niveau de précision de 80%.
Ce domaine de recherche présente une grande activité et on peut s’attendre à de nouvelles avancées mettant en jeu les méthodes les plus innovantes en apprentissage automatique telles que le reinforcement learning, unsupervised learning ou le transfer learning, comme le prédit cette publication.
Des avantages certains, avec certains inconvénients
Alors que le volume de données collectées augmente exponentiellement dans la plupart des secteurs d’activité, et que les équipements offrant une grande capacité de calcul sont accessibles à moindre coût, les avantages de cette approche sont significatifs. L’argument principal avancé par ses partisans est qu’elle permettrait une meilleure protection des données par conception. En effet, que celles-ci soient à caractère personnel, qu’elles soient soumises à une propriété intellectuelle ou qu’elles soient simplement sensibles, leur conservation de manière décentralisée assurerait plus de confidentialité. En effet il serait d’une part plus difficile selon eux de pirater un nombre important de machines plutôt qu’un unique serveur, bien que cet argument reste à nuancer puisqu’il est également plus coûteux de sécuriser plusieurs machines plutôt qu’une seule. D’autre part, l’architecture distribuée permettrait une meilleure gouvernance des données, ouvrant ainsi la porte à des traitements où la confiance entre les acteurs constituait jusqu’alors un obstacle bloquant.
Selon la configuration utilisée, les inconvénients rencontrés varient. Trois d’entre eux semblent particulièrement importants. Premièrement, lorsque les machines distantes sont nombreuses mais peu fiables, comme dans le cas de smartphones, l’apprentissage doit être robuste à la déconnexion d’une partie des machines. Un nombre seuil minimum de machines est généralement requis dans ce cas et un protocole est adopté pour supporter leur connexion et déconnexion. Deuxièmement, une grande confiance est requise entre les membres de l’apprentissage puisque chacun reste maître des données qu’il fournit lors de l’apprentissage. Le modèle obtenu peut en effet être corrompu par un participant malveillant qui « polluerait » le modèle ou introduirait une porte dérobée. Enfin, selon la manière dont sont collectées les données par chacun des centres, leur distribution peut ne pas être la même dans chaque point de collecte, c’est le problème des données non-IID (non indépendantes et identiquement distribuées) : dans le cas du GBoard par exemple, le système doit tenir compte des particularités linguistiques des groupes socio-culturels afin de générer des recommandations personnalisées. Des mesures particulières sont également à prendre dans cette situation pour corriger les biais rencontrés. Les méthodes permettant de s’adapter à ce type de données sont nombreuses comme le détaille cette publication et peuvent être classées selon deux stratégies : éviter la discrimination par compensation des biais ou personnaliser les résultats en les intégrant volontairement dans le système d’IA. Dans le second cas, puisque chaque participant obtient potentiellement un modèle d’IA unique, l’auditabilité du système fait face à plusieurs problématiques. Premièrement, pour vérifier l’absence de biais dans le système, l’auditeur devra étudier un ensemble suffisamment diversifié de modèles entraînés, en contrôlant les modèles en production ou en les entraînant par lui-même. La seconde problématique est d’ordre juridique : dans l’hypothèse où l’existence de biais est permise lors de l’apprentissage afin que les modèles soient plus adaptés aux spécificités des participants à l’apprentissage fédéré, et dans la mesure où les biais sont effectivement représentatifs des données des participants et non liés à leurs caractéristiques propres (telles que le sexe, l’âge ou l’origine ethnique), ces biais sont-ils alors imputables au responsable de traitement ? A cette interrogation doctrinale s’ajoute la difficulté technique suivante : comment distinguer les biais représentatifs des données du participants des biais liés à ses caractéristiques propres ?
L’adoption grandissante de l’approche décentralisée fait l’objet de plusieurs controverses, tant pour l’apprentissage fédéré que pour d’autres types de systèmes. Les travaux de Carmela Troncoso à l’EPFL fournissent une cartographie instructive sur les avantages et inconvénients de chaque approche.
Une technique déjà largement adoptée
L’utilisation la plus célèbre de l’apprentissage fédéré est le clavier Gboard développé par Google. Il s’agit d’un algorithme de recommandation utilisé principalement sur les téléphones Android, pour la recherche sur le navigateur web Google, où il permet la priorisation de résultats, mais également dans les applications de messagerie le supportant, où il permet une saisie prédictive. Les données utilisées pour l’apprentissage sont particulièrement personnelles : il s’agit des données de navigation et des entrées de texte dans les applications de messagerie. Celles-ci ne sont ainsi pas remontées dans une base centralisée mais conservées sur le téléphone de l’usager, ce qui présente un réel avantage en termes de confidentialité. De plus, Google utilise la méthode de federated averaging développée par ses équipes de recherche afin d’agréger les modèles entraînés chez chacun des utilisateurs en un modèle unique. Le modèle sous-jacent est un type de réseau de neurones appelé LSTM pour Long-Short Term Memory : il s’agit d’un réseau de neurones récurrent capable de garder en mémoire certains éléments plus ou moins distants pour améliorer l’utilisation du contexte dans la prédiction de l’algorithme, comme le précise cette publication. Cette information est importante puisque cela signifie que l’apprentissage fédéré peut être utilisé sur des algorithmes ayant un très large nombre de paramètres, mais également que l’algorithme, pour pouvoir prédire le texte qui suivra, utilise une partie importante du texte qui lui a été fourni : ce texte pourra-t-il être retrouvé grâce aux paramètres du modèle entraîné ? L’entreprise a par ailleurs mis en place une mesure de sécurité à cet égard appelée secure agregation et qui sera décrite dans la suite de cet article. Un tout autre dispositif actuellement en test chez Google utilise également l’apprentissage fédéré, il s’agit de FLoC – pour Federate Learning of Cohorts – qui permet de classer chaque utilisateur dans une cohorte grâce à son historique de navigation conservé localement. Des publicités ciblées sont ensuite proposées à chaque cohorte. Ce protocole a causé une réaction forte de la communauté qui a interprété la fonctionnalité comme une manière détournée de tracer les individus pour Google, comme nous le verrons dans ce qui suit.
Dans le secteur de la santé, l’entreprise Owkin développe des solutions d’apprentissage fédéré destinées au milieu médical, où le partage de données est particulièrement encadré. Un projet théorique d’histopathologie, l’étude des tissus dans l’objectif d’établir un diagnostic, ayant fait l’objet d’une publication permet d’observer la démarche employée. Les données sont théoriquement collectées par différents centres hospitaliers où un modèle est entraîné afin de prédire la présence de métastase dans des images de tissus. La publication se conclue par un résultat positif soulignant que le protocole permettrait une prédiction plus fiable qu’un entraînement non fédéré intra-centrique. La diversité des données, obtenue ici par l’approche fédérée en l’absence d’une base de données centralisée, permettrait ainsi d’atteindre une plus grande précision. Si les données utilisées dans ce projet proviennent d’une base publique, cette approche pourrait être généralisée à des données réellement gérées en silo.
Enfin, le navigateur Brave utilise l’apprentissage fédéré pour l’entraînement de son algorithme de recommandation d’articles d’information Brave News. Ce système utilise l’historique de navigation de l’utilisateur afin de lui proposer des informations ciblées, sans collecter l’historique dans une base centralisée. Ce dispositif présente un intérêt particulier : il utilise une méthode appelée confidentialité différentielle afin de sécuriser les données de ses utilisateurs. Cette technique est décrite dans la suite.
Quels impacts sur la protection de la vie privée ?
Une méthode vraiment favorable à la protection des données ?
L’apprentissage fédéré reposant sur une approche décentralisée, il s’agit théoriquement d’une mesure de protection de la vie privée par conception qui ne peut être que louée par la CNIL en première analyse. En effet, le stockage des données à caractère personnel sur le terminal des utilisateurs, ou dans des entrepôts non centralisés réduirait sensiblement les risques de perte d’intégrité, de confidentialité ou de disponibilité de ces données pour plusieurs raisons :
- Les bases décentralisées représentent un intérêt moindre pour un attaquant potentiel puisque la quantité de données contenue est moins importante pour un niveau de sécurisation non négligeable. Le gain attendu du déploiement d’un ransomware ou du piratage de données pour leur revente ne serait ainsi plus à la mesure des efforts à déployer par un attaquant.
- L’absence de transmission de données à caractère personnel rendrait impossible une perte de confidentialité par interception de flux.
- Sans communication des données, la gouvernance de celles-ci n’est plus à démontrer : le serveur en charge de la collecte serait seul possesseur de ses données.
Plus généralement, l’approche décentralisée pourrait apporter davantage de transparence aux personnes qui seront ainsi en mesure de connaître le parcours de leurs données, les frontières de celui-ci étant clairement définies.
Sous ce tableau enthousiaste se cachent néanmoins certaines failles. Si les données font l’objet d’une plus grande sécurité, c’est dorénavant sur le modèle que portent les risques. Nous invitons le lecteur à se référer aux articles « Petite taxonomie des attaques des systèmes d’IA » et « P[ã]nser la sécurité des systèmes d’IA » qui détaillent les types d’attaques mentionnés dans la suite.
Premièrement, puisque le modèle est partagé avec un nombre important d’acteurs et qu’il n’est pas toujours possible de garantir la bienveillance de chacun, la présence d’un attaquant parmi les membres de la fédération ne peut être écartée. Ce dernier aurait alors une connaissance du type white-box du modèle. En effet, l’attaquant potentiel pourra facilement intercepter des informations lors de l’entraînement et ainsi en déduire a minima l’architecture et les poids du modèle à différentes étapes de l’entraînement et sur les différentes machines distantes, ainsi que des informations à propos de l’entraînement telles que des métriques de précision. La fuite de ces informations peut engendrer des conséquences concernant la propriété intellectuelle du modèle, mais elle facilite également tous types d’attaques sur celui-ci : les data poisoning, model inversion ou encore backdooring sont facilitées dès lors que l’attaquant est en mesure de réaliser des expérimentations sur le modèle lui-même et ses itérations. L’instance du modèle à laquelle accède un attaquant favorise en effet certaines attaques : l’interception du modèle local d’un serveur présentera un risque plus important d’inversion du modèle, alors que le modèle du centre orchestrateur favorisera une attaque de type data poisoning. Certaines techniques permettant de réduire la vraisemblance de telles attaques existent d’ores et déjà et sont décrites en 2.2. Par ailleurs, les algorithmes dont les paramètres utilisent explicitement certaines données de l’ensemble d’entraînement telles que le Support Vector Machine (SVM) – qui permet de classifier des données en identifiant les frontières entre groupes de données en reposant sur certaines données de l’ensemble – ou le clustering par k plus proches voisins (k-nearest neighbours) – qui consiste à intégrer les valeurs de certaines données dans le modèle pour définir des groupes ou clusters d’éléments proches – sont à proscrire en apprentissage fédéré sur des données à caractère personnel puisqu’une perte de confidentialité des paramètres entraînerait mécaniquement une perte de confidentialité de données à caractère personnel.
Deuxièmement, un attaquant en dehors de la fédération pourrait également intercepter les flux de communication lors de l’entraînement et ainsi avoir accès aux même informations que celles citées précédemment, sans avoir la capacité d’influer sur l’apprentissage. L’attaquant ne sera ainsi pas en mesure de changer le fonctionnement de l’algorithme, mais il pourra mener des attaques de model inversion, ou model inference notamment, qui présentent un risque particulier pour la protection de la vie privée. Puisque ces attaques requièrent d’intercepter les communications, de parvenir à déchiffrer les données interceptées et enfin d’inverser le modèle sans certitude sur la potentielle valeur des informations tirées, ces attaques semblent toutefois peu vraisemblables.
Enfin, l’absence de collecte de données de manière centralisée peut constituer un moyen pour certains acteurs de donner une fausse impression de respect de leur vie privée aux personnes. A titre d’exemple, Google, en réponse à la réglementation des cookies découlant de la directive ePrivacy, a développé le système FLoC qui n’utilise pas de cookies et ne collecte pas de données de navigation de manière centralisée, en mettant en avant le caractère respectueux de la vie privée de ce nouveau système. Néanmoins, bien que les données des utilisateurs restent effectivement décentralisées, leur appartenance à un groupe d’utilisateurs (ou cohorte) sera bien partagée avec les acteurs publicitaires et l’intégralité de leur historique de navigation sera traitée par le système, comme l’explique cet article. Ce moyen détourné de profiler les utilisateurs est également facilité par le flou existant sur la nature des agrégats résultant de l’apprentissage fédéré : si les données utilisées pour l’entraînement sont à caractère personnel, doit-on appliquer le RGPD aux poids et paramètres du modèle entraîné ?
Pour conclure, si l’apprentissage fédéré constitue bien une mesure de protection de la vie privée par conception, il s’agit également d’une nouvelle technologie qui ouvre la porte à de nouveaux traitements et à d’éventuelles nouvelles collectes de données présentant des risques pour la protection de la vie privée, parfois du simple fait de leur finalité même.
Les protections « en option »
Afin de réduire les risques pour la vie privée cités dans la partie précédente, plusieurs techniques existent d’ores et déjà.
Parmi celles-ci, on trouve les techniques habituellement rencontrées en apprentissage machine et qui s’adaptent à l’apprentissage fédéré : certaines mesures sont d’ordre logiciel telles que l’utilisation de données synthétiques, la confidentialité différentielle ou encore le chiffrement homomorphe, alors que d’autres visent le matériel utilisé, comme l’utilisation d’un environnement d’exécution de confiance. Bien que ces méthodes aient été éprouvées dans la littérature dans le cas de l’apprentissage machine, leur application à l’apprentissage fédéré n’est pas triviale. La plupart de ces méthodes doivent être mises en place par chaque machine distante ce qui demande des ressources de calcul suffisantes, un haut niveau de connaissances et un degré important de coopération.
D’autres méthodes ne s’appliquent quant à elles qu’à l’apprentissage fédéré. La secure agregation par exemple permet de s’assurer que les informations partagées par une machine distante i au cours de l’apprentissage ne puissent pas être déchiffrées avant leur agrégation avec les informations remontées par un nombre minimum d’autres machines distantes. La machine distante en question doit appliquer un masque généré aléatoirement et complémentaire des masques des autres machines distantes à ses données, les rendant ainsi illisibles, jusqu’à ce qu’elles soient sommées avec les données des autres machines distantes, ce qui annulera le masque appliqué. Cette méthode permet de se prémunir contre une attaque du serveur central qui pourrait être malveillant, mais également contre une interception malveillante des communications. La secure agregation s’inscrit dans un champ de recherche plus large, la secure multi-party computation, dont l’objectif est de rendre possible un calcul à plusieurs agents où la confidentialité des données de chacun serait préservée. On peut également citer la méthode intitulée private set intersection qui permet aux participants de prendre connaissance des informations communes à la fédération sans révéler celles qui leur sont propres par recoupement des informations chiffrées. Cette méthode est particulièrement utile lorsque les données concernent des personnes : grâce à cette technique, un groupement de centres hospitaliers pourra réaliser un apprentissage sur les données médicales de patients ayant visité plusieurs centres en identifiant les patients en commun aux centres par recoupement de la base des identifiants chiffrés et sans divulguer d’informations à propos des autres patients. Les centres peuvent ainsi ne centraliser que les données médicales des patients ayant visité plusieurs centres et conserver localement les données des autres patients, et un modèle peut être entraîné sur la totalité des patients en apprentissage fédéré.
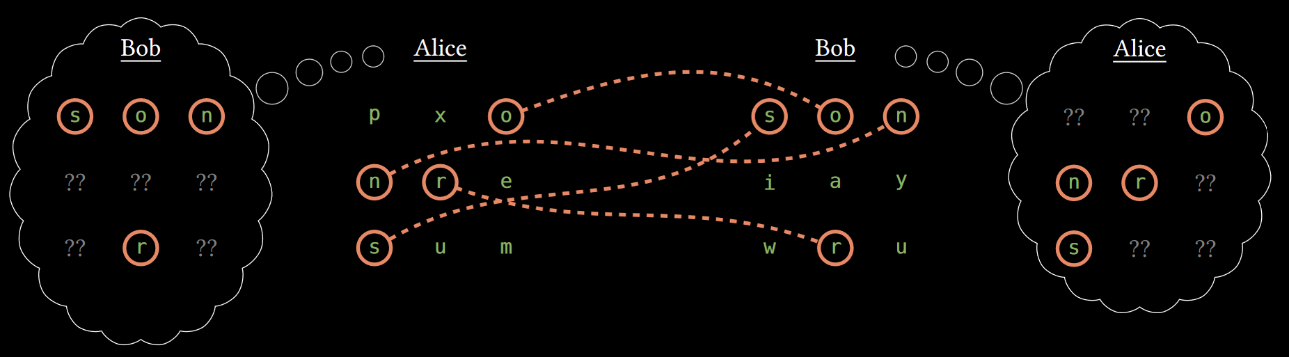
Figure 2 : Private Set Intersection : Alice et Bob ne dévoilent que les données qu'ils ont en commun.
(source)
Les méthodes mentionnées ci-dessus permettent d’améliorer la sécurité des données et la préservation de leur confidentialité. Chacune présente des inconvénients : nécessité d’une puissance de calcul supérieure, lenteur additionnelle lors des calculs, augmentation du coût du matériel, augmentation de la complexité de mise en œuvre, etc. Toutefois, un inconvénient important est partagé par chacune d’entre elles : aucune de ces méthodes n’empêche les attaques par data poisoning, c’est-à-dire la pratique consistant à corrompre les données lors de la phase d’entraînement d’un modèle. Certaines d’entre elles pourraient même les faciliter. En effet, en sécurisant la confidentialité des données de chacune des machines distantes, il devient plus difficile pour le centre orchestrateur de s’assurer de la qualité des données fournies par chacun. Malheureusement, la littérature proposant des moyens de se prémunir contre ces attaques est encore inexistante, tandis qu’un nombre important d’articles démontrant leur plausibilité a déjà été publié.
On retrouve dans le tableau suivant une cartographie des mesures de sécurité rencontrées en apprentissage fédéré (davantage de détails sur ces méthodes pourront être trouvés dans cette publication) :
|
Méthode |
Mécanisme |
Protège contre |
Inconvénients |
|
Chiffrement homomorphe (homomorphic encryption) |
Chiffrement des paramètres lors de l'apprentissage |
L’interception des paramètres de l'apprentissage |
Quantité importante de calculs supplémentaires pendant l'entraînement, plus de difficulté à identifier une attaque par data poisoning, coopération entre les machines distantes nécessaire |
|
Données synthétiques (synthetic data) |
Génération de données synthétiques représentatives des données réelles par un Generative Adversarial Network (GAN) avant l'entraînement |
Les attaques par inversion de modèle (model inversion), ou l’inférence d’appartenance (membership inference) |
Complexité, difficile à généraliser, quantité importante de calculs supplémentaires en amont, application limitée à certains types de données |
|
Confidentialité différentielle (differential privacy) |
Ajout de "bruit" aux données locales avant l'entraînement avec un impact négligeable sur la distribution statistique garanti par un critère théorique |
Les attaques par inversion de modèle (model inversion), ou l’inférence d’appartenance (membership inference) |
Perte en utilité (la qualité du réseau résultat est amoindrie), difficile à généraliser |
|
Agrégation confidentielle (secure aggregation), calcul multipartite sécurisé (secure multi-party computation) |
Coopération entre les machines distantes permettant de masquer les données au centre orchestrateur avant leur agrégation |
Interception des paramètres de l'apprentissage, perte de confidentialité du modèle (model evasion), membership inference |
Complexité, coopération et communication entre les machines distantes, plus de difficulté à identifier une attaque par data poisoning |
|
Environnement d’exécution de confiance (trusted execution environment) |
Utilisation d'une machine sécurisée ou d’une partie sécurisée d’un processeur pour effectuer les calculs |
Piratage des données locales et intervention malveillante dans l'apprentissage |
Coût important, inutile si toutes les machines distantes ont un niveau inférieur de sécurité |
Tableau 1 : Cartographie des mesures de sécurité applicables à l'apprentissage fédéré
Qui dit fédération ne dit pas unanimité
De nombreuses interrogations
Bien qu’aucune réponse ne puisse encore être apportée au vu de l’aspect inédit de cette technologie et à la diversité des utilisations envisageables, certaines problématiques ont déjà été identifiées.
Sur la nature des données transmises lors de l’apprentissage
Les paramètres résultant de chaque itération de l’apprentissage sont communiqués des machines distantes au centre orchestrateur, avant que celui-ci ne transmette à son tour des informations permettant à chaque machine de mettre à jour ses paramètres locaux. Lorsque l’apprentissage est réalisé sur des données à caractère personnel, un risque de perte de confidentialité des données existe. Ainsi, les informations transmises entre les machines distantes et le centre orchestrateur doivent-elles être considérées comme des données à caractère personnel ? Les trois critères du G29 sur l’anonymisation s’appliquent-ils pour déterminer si ces données sont anonymes ou non ? Comment mesurer les risques de réidentification ou d’inférence ? Les techniques de chiffrement mentionnées au 2.2 permettent-elles de réduire ce risque à un niveau résiduel acceptable ? Des éléments de réponse à ces questions peuvent être trouvés dans la proposition de lignes directrices sur les techniques d’anonymisation et de pseudonymisation actuellement en cours de rédaction au CEPD. L’ébauche de texte propose plusieurs recommandations succinctes spécifiques aux modèles d’apprentissage machine ainsi qu’une méthodologie plus détaillée que celle de l’avis du G29 afin de mesurer le risque de réidentification.
Sur la responsabilité des acteurs
Chaque acteur de la fédération sera en charge de la collecte d’informations, mais il recevra également des informations résultant de l’apprentissage fédéré. En cas d’atteinte à la protection des données à caractère personnel, il convient de pouvoir identifier les organismes responsables de l’information des personnes et ceux pouvant faire l’objet de poursuites. Ces questions sont d’intérêt pour les acteurs du domaine pour des raisons de sécurité juridique, mais y répondre permettrait par ailleurs de résoudre des enjeux de propriété intellectuelle. Pour ces raisons, des acteurs académiques commencent à se saisir de ces sujets, comme en témoigne le travail de Nicolas Papernot. Il convient de plus de prendre en compte les éventuelles pressions pouvant exister entre les acteurs : dans le cas d’un apprentissage sur ordiphone, les personnes peuvent-elles s’opposer à prendre part à la fédération ? Partagent-elles la responsabilité du traitement ? Dans le cas d’un apprentissage sur des centres de calcul, chaque machine est-elle responsable du comportement et des mesures de sécurité prises par les autres machines distantes ? Selon la nature des agrégats issus de l’apprentissage et selon l’algorithme utilisé, quelle sera la responsabilité de chacun des acteurs mettant une machine et des données à disposition de la fédération ? Quelle sera celle du centre orchestrateur ?
Sur les mesures de sécurité applicables
Comme nous l’avons vu au 2.2, un compromis existe en ce qui concerne les mesures de sécurité entre la transparence sur le comportement des machines distantes et la confidentialité des données. Si certaines mesures permettent de renforcer la robustesse du système face à une attaque extérieure ou provenant d’un centre orchestrateur malveillant, elles obscurcissent le procédé d’apprentissage et peuvent faciliter une attaque interne. De plus, selon la nature des agrégats issus de l’apprentissage, ces derniers peuvent être soumis aux mesures de sécurité habituelles. Ainsi, quelles mesures de sécurité appliquer aux données transmises lors de l’apprentissage et au modèle qui en est issu ?
Sur l’auditabilité des systèmes d’IA
Dans le cadre de l’application du règlement IA actuellement en projet à la Commission Européenne, autant que dans les prérogatives actuelles de la CNIL, celle-ci pourrait être amenée à contrôler les risques pour les personnes liés à l’utilisation d’un système d’IA utilisant de l’apprentissage fédéré. L’explicabilité d’un tel système, et en particulier la recherche de biais dans la base de données d’entraînement, constitue ainsi un enjeu critique pour la CNIL. Il conviendra de savoir quelle documentation à propos du système d’IA et des données d’entraînement exiger lors d’un audit ? Quelles méthodes utiliser pour mesurer les biais et la représentativité dans un ensemble de données distribué ? Les modèles obtenus localement peuvent-ils licitement contenir des biais propres à la machine distante et comment alors distinguer ceux-ci de biais discriminatoires systématisés ?
Sur l’exercice des droits
Si le droit à la portabilité ne s’applique a priori pas aux modèles entraînés en ce qu’ils constituent des informations inférées, l’exercice par l’individu des droits d’accès, à la rectification ou à l’effacement peut poser certains problèmes. En particulier, lorsque ces deux entités sont distinctes, l’individu doit-il s’adresser à l’entité jouant le rôle de centre orchestrateur ou à celle ayant collecté ses données afin d’exercer ses droits ? Les paramètres du modèle entraîné lors de l’apprentissage fédéré peuvent-il faire l’objet de demandes de rectification, d’accès ou d’effacement ?
Tour d’horizon chez les homologues de la CNIL
Un tour d’horizon des autorités de protection des données permet de constater la rareté des prises de position sur ce sujet. L’ICO préconise l’utilisation de l’apprentissage fédéré en tant que mesure de protection de la vie privée par conception mais incite tout de même les responsables de traitement à mesurer les risques de réidentification dans les agrégats de l’apprentissage, et indique qu’un dispositif de co-responsables de traitement est à envisager. L’autorité norvégienne, Datatilsynet, quant à elle, classe l’apprentissage fédéré en tant que bonne pratique pour réduire la quantité de données collectée. Un article avait par ailleurs été publié sur le site du LINC à l’occasion de la sortie du rapport de l’autorité norvégienne. Au-delà des frontières européennes, l’autorité canadienne présente l’apprentissage fédéré comme une méthode de protection de la vie privée par défaut en soulevant le coût important des communications liées.
Illustration : Pixabay - cc-by Quimuns

