
[Article 1/3] Crawling, scraping and TDM explained
Rédigé par Romain Darous
-
02 June 2026Before examining the means available to website publishers to block the collection of their data, it is first necessary to define the practices implemented by search engines and companies developing generative artificial intelligence models. Several concepts are used in this context: crawling, scraping, and TDM (Text and Data Mining). Although these terms refer to similar practices, their exact scope varies depending on usage and interpretation. It is therefore essential to clarify the meaning of each of these terms in order to establish a precise framework for the discussion.

Summury of the long read file
- Introductory article: How to prevent data extraction bots from collecting publicly available data
- Article 1: Crawling, scraping and TDM explained
- Article 2: Preventing web data extraction using declarative methods
- Article 3: Prevent web data extraction by blocking access to the website
- Supplementary article: Fingerprinting
Web crawling
Web crawling refers to the automated process of exploring web pages accessible on the Internet. It begins from an initial set of URLs, known as seed URLs. These starting points make it possible to initiate the exploration of the web. At this stage, the remaining pages available online, numbering in the billions, are still unknown. The purpose of crawling is precisely to discover these remaining web pages by following the hyperlinks found on the pages visited. The result of this collection operation is referred to as a crawl.

Image generated by AI (Imagen, Google)
Let us take the example of Common Crawl, a non-profit organization specializing in crawling. Every month, it publishes the results of its explorations as open source data. As starting points, Common Crawl uses URLs provided by third parties, others extracted from “sitemaps” (a protocol enabling website providers to supply machine-readable information about the pages that can be explored), major domain names identified through the web graphs it builds, as well as random samples of URLs originating from previous crawls. These seed URLs amount to several hundred million. The organization then proceeds using a breadth-first search approach, with a maximum depth generally set at around 4 to 5 “hops”, allowing the discovery of new URLs. These methods enable it to explore around 2 billion web pages per month, bringing the total number of unique URLs collected between July 2024 and June 2025, to 20 billion, for instance. Each crawl makes it possible to discover new URLs while inevitably including duplicate URLs already present in previous crawls. These duplicates nevertheless serve to update already known pages, which constitutes one of the major challenges of web crawling.
This exploration is similar to traversing a directed graph. Indeed, websites are interconnected through internal links, which enable navigation between the different pages of the same site, and external links, which point to other websites. For example, a hotel comparison website may aggregate the offers available in a given region and during a specific period of time, then redirect the user to hotel websites to complete the booking. Conversely, Wikipedia pages contain numerous internal links that facilitate navigation from one article to another within the site.
Starting from a given set of URLs, web crawling therefore enables the progressive and recursive discovery of links. This exploration is accompanied by the collection of the visited URLs, the titles of web pages, their descriptions, and their HTML content. The databases built as a result of crawling reach sizes on the order of petabytes (PBs), with one petabyte corresponding to 1,000 terabytes.
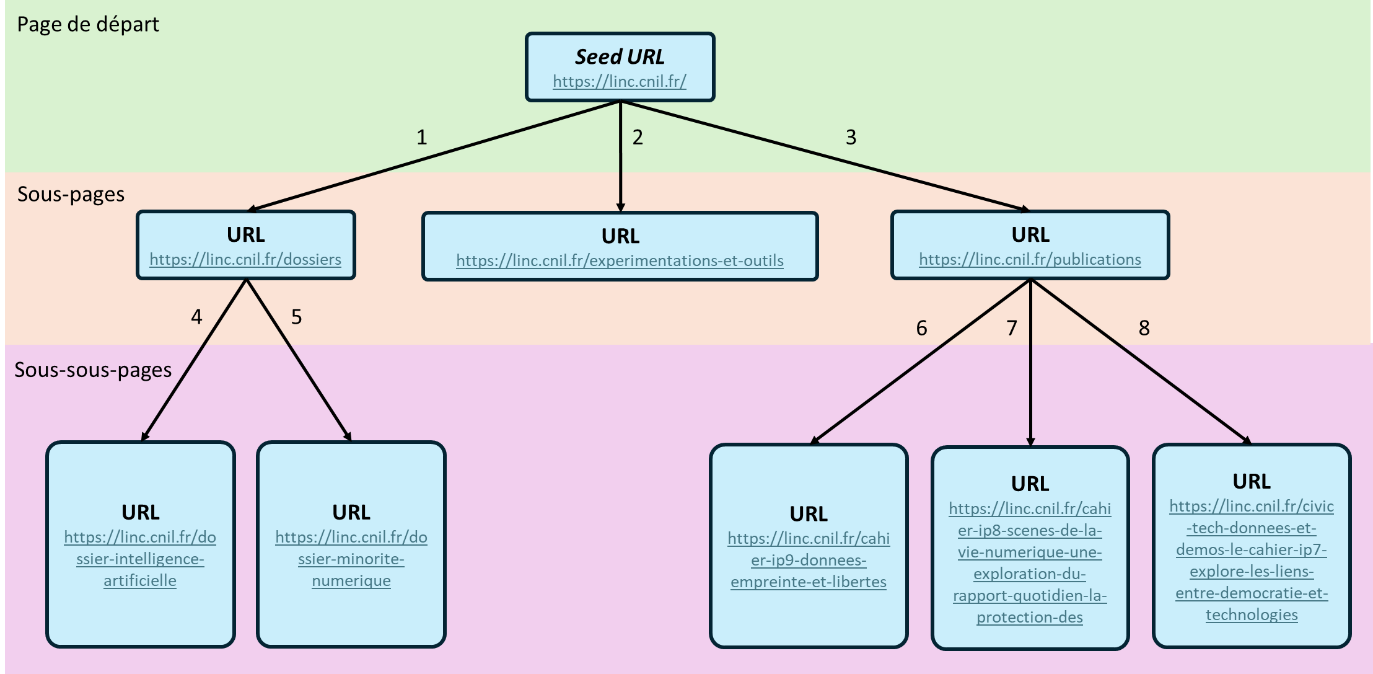
Example of link discovery using the LINC website homepage as the seed URL. The numbering indicates the order in which pages are discovered according to the BFS traversal algorithm.
Originally, web crawling was one of the key stages in the development of search engines. Once URLs have been crawled and the content of the associated pages collected, an indexing phase is carried out to reference and rank web pages by analysing their HTML content, in order to provide relevant and personalized search results to the user of the search engine. For example, 50 billion web pages were indexed by the Google search engine in January 2025.
Web scraping
Web scraping refers to the extraction of information contained in already known web pages. This is the main distinction from web crawling. Starting from identified URLs, web scraping consists of analysing the HTML content of each page in order to extract relevant data, and then structuring that data so that it can be used.
Web scraping offers a wide range of uses, including price monitoring, which consists in automatically comparing a company’s prices with those of its competitors. This makes it possible to conduct competitive intelligence or analyse pricing trends within a given market. This technique also facilitates the automated aggregation of data, which is useful in many contexts: financial analysis, the creation of journalistic corpora, or academic research. In these latter cases, scraping makes it possible to gather large volumes of information in order to conduct investigations, support analyses, or establish as comprehensive a state of the art as possible.

Image generated par AI (Imagen, Google)
The principles of web crawling and web scraping can therefore be summarized as follows: the former consists in collecting the URLs of web pages accessible online, while the latter aims to extract and structure the relevant information contained within those pages.
Scraping and crawling bots
Crawling and scraping are two complementary practices that enable large-scale automated data collection. This automation relies on the use of bots (referred to respectively as crawlers and scrapers, or more generally as spiders, and sometimes wanderers), i.e., software programs designed to systematically explore web pages and extract relevant information. When deployed at scale, these bots are typically run across multiple machines in order to distribute the load and speed up the collection process. They are hosted in geographical regions close to the servers of the targeted websites, in order to reduce latency and optimize collection efficiency.
Their deployment at Internet scale therefore raises numerous technical, algorithmic, and infrastructural challenges, due to the billions of pages to be explored, the need for exhaustiveness, and the massive volume of data generated. Among the key issues, the following can be highlighted:
- Intelligent distribution of bots across websites in order to avoid the risk of server overload;
- Regular updating of collected pages, with questions of frequency and prioritization to ensure data integrity and accuracy;
- Deduplication of collected information, including the detection of near-duplicates using algorithms such as SimHash, which make it possible to identify pages that are highly similar but not identical (for example, variations containing different advertisements);
- Finally, data cleaning, an essential step to make the collected information usable for downstream analysis or applications.
Example of scraping
Scraping is performed by identifying relevant HTML tags by their type (paragraphs <p>, sections <div>, etc.) or by associated CSS classes and identifiers (the “id” and “class” attributes). In Python, for example, one can use the requests library to download the HTML content of a web page, and then the bs4 library to extract the relevant content.
The figure below shows on a very simple example how it is possible to automate data collection on a web page, using either HTML tags or CSS identifier names:
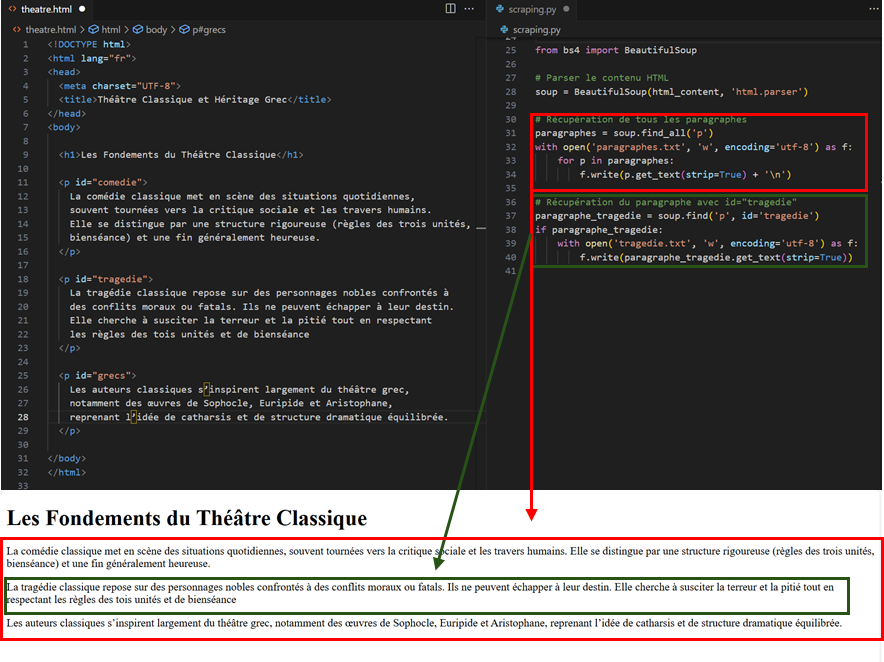
In this example, the text contained in all the paragraphs on the web page is collected first, followed by only the paragraph whose CSS identifier is id="tragedie".
TDM (Text and Data mining)
Finally, the term TDM (Text and Data Mining) refers to the set of practices that enable the analysis of large volumes of data in all its forms: text, images, video, audio, and so on. The concept of TDM therefore broadly covers all the steps involved in extracting information from datasets that are too large to be processed using traditional methods. TDM practices include the collection and processing of such data (cleaning, feature extraction and mathematical representation, etc.), as well as the application of analytical algorithms and methods to extract information (clustering, decision trees, SVMs, neural networks, language models, etc.) or to structure the data. In this sense, scraping could be considered a step within TDM in the context of training a foundation model. However, the term TDM is sometimes also used to refer to the initial data collection phase, and can therefore be confused with web scraping and/or web crawling. For example, the TDMRep protocol discussed later refers to a means of controlling the collection of publicly available web data by bots on websites.
Application to the creation of large databases for training LLMs
Mastering crawling and scraping is particularly important for building large, high-quality datasets used to train foundation models, and it has a major impact on the final performance of the resulting model.
These combined techniques make it possible to carry out large-scale data collection that is as exhaustive, diverse, and high-quality as possible. Crawling enables the discovery of web pages, which are then scraped to extract valuable content and use it to train AI models.
Because they are often used together, the two practices are generally referred to using a single umbrella term. In the following sections, when the distinction is not necessary, the term “web data extraction” will be used to refer to both scraping and crawling, and the term “bot” will be used to refer to any algorithm used to collect publicly available online information.
Dowload the long file read in PDF
Illustration : Nano Banana 2

