
[Generative AI dossier] - ChatGPT : a well-trained smooth talker
ChatGPT, Bard and Ernie - AI-powered chatbots are all over the news, praising their prowess and highlighting challenges they face. Big tech companies behind these creations seem to be racing for media coverage and market share in a market that had not even existed in late 2022. This AI media battle is not the first, of course, with tech companies regularly jousting in areas such as autonomous vehicles, generative content, image analysis and voice assistants.
What are the technical and legal risks associated with these technologies and the new uses they are opening up ? This article, the first in a series on generative AI, on the language processing and learning methods used to operate a chatbot, using ChatGPT as an example.

Contents :
- ChatGPT: a well-trained smooth talker (1/4)
- How to regulate the design of generative AI (2/4)
- From training to practice: generative AI and its uses (3/4)
- [LINC Exploration] - The work of IAsterix: AI systems put to the test (4/4)
While the texts produced by this new generation of robots are disturbingly realistic, the techniques they employ are nothing new: language processing is far from being a new discipline.
In this area, the aim is to understand grammar (subject/verb/complement) but also semantics of sentences (for example, to understand that 'car' and ‘jalopy’ refer to the same object in different registers of language). Other well-known challenges include distinguishing homonyms ("avocat", "sous", "Paris"), dialogue (which requires the ability to retain a memory of the conversation) and detecting irony.
In the 1950s, translation algorithms based on symbolic models (which rely on pre-established rules rather than on learning) were developed, before being gradually replaced by algorithms based on statistical approaches from the 1980s. Thanks to the increased computing capacity of computers and servers, it became possible to manipulate large quantities of text and to derive statistical analyses from them, such as the probability of occurrence of the next word in a sentence. Finally, the arrival of the Web in the 2000s paved the way for unsupervised or semi-supervised approaches by compensating for the difficulty of extracting semantic information from training texts with the vast amount of information now available. A more complete history of automatic language processing techniques can be found, particularly in France in the CNIL white paper on voice assistants.
However, since the 2010s, there have been a number of unsuccessful attempts to achieve satisfactory results when it comes to performing diversified tasks. Data were available and computing capacity seemed sufficient, but the algorithm needed to exploit these resources was still lacking. It was in 2017 that a team from Google Brain introduced Transformers-type models in Vaswani et al, 2017 (the title of which, "Attention is all you need", is significant and to which we will return below). The ability of these models to solve the problem of the vanishing gradient (see below), on the one hand, and the ability to parallel their learning, on the other, make them the benchmark algorithms for automatic language processing today, following on from GRU, LSTM and other RNNs, which seem to have reached their limits[1] .
This article, which will focus on operation and technical issues of ChatGPT, developed by the company OpenAI, is the first in a series of articles aimed at exploring the issues raised by generative AI algorithms such as GPT-3 and GPT-4 (text generator), Stable Diffusion (image generator) and MusicLM (sound generator) and their use. To better understand ChatGPT's capabilities, some of the technical operating mechanisms of this tool will be explained, before listing personal data processing involved during its design and use. Legal and ethical issues surrounding such systems will then be examined in the rest of the report.
ChatGPT: step-by-step recipe
ChatGPT is chatbot that performs several tasks. It handles information entered in the prompt by the user, feeds this data into a language processing algorithm (called a "Transformer") and presents the algorithm's output in a format that the user can understand. Therefore, language processing algorithm is the main ingredient in the tool’s functionality, but we will see that the recipe for a chatbot is more complex.
Do you need to understand a question to answer it ?
From human language to machine language
The text inserted into a chatbot's prompt must first be encoded in a machine-readable format. At this stage, known as "vectorisation", a new representation is associated with each of the words in the training corpus. This takes the form of a vector or, more easily, a list of numerical values. All these representations, which in a way correspond to a new language that can be interpreted by the machine, are called the "latent space". The Embedding Projector offers a visualisation of such a latent space (other resources on the subject can be found on the CNIL website).
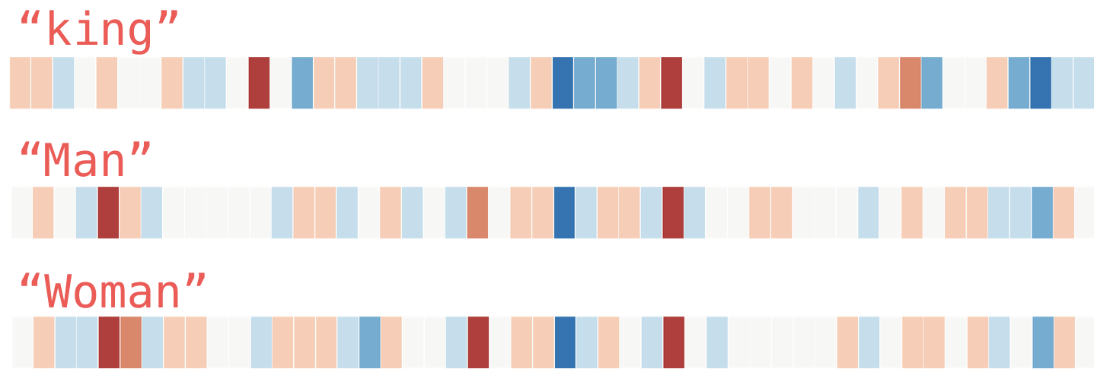
Figure 1: Vector representation of the words "king", "Man" and "Woman", where each box corresponds to an entry in the vector. A warm colour represents a high value, and a cold colour a low value (source: Jay Alammar, Illustrated Word2Vec).
Instinctively, these vectors represent the meaning of a word divided into different axes of analysis corresponding to the different numerical values of the vector. However, these analysis axes are never defined, i.e. words such as "man" and "woman" can have values close to each other in the 5th position of their representation, as is the case in the example in figure 1. However, it was never indicated that the 5th position corresponded to a notion such as "human", "person", "gender" or "individual": this was induced by the vectorisation algorithm thanks to the context in which the words are found in the training corpus.
In order to understand the representation of a word, we need to compare it with other words, according to the idea that two words that are semantically close will have similar numerical values for specific components of the lists that correspond to them. This is where the first problem arises: any association of words in the training corpus will be interpreted as semantic proximity during vectorisation. Figure 2 compares the representations of the words "man", "woman", "king" and "queen". In particular, it draws an analogy between the representation of the calculation "king - man + woman" and "queen" (since mathematical operations can be performed on the vectors). While the vectors obtained are very similar overall, there are still some differences. Could these be due to a bias, or could they be the cause if we used this representation ?
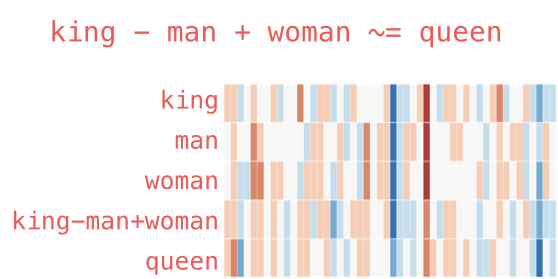
Figure 2: illustration of the vector representation of the words king, man, woman, queen and the "king-man+woman" operation. Similar colours represent similar values in the representation (source: Jay Alammar, Illustrated Word2Vec).
Bias in AI: the looming shadow
Artificial intelligence applied to language processing presents the risk, like any AI system, of presenting biases. These biases, of all kinds, can lead to discrimination, as pointed out in the report on the ethical challenges of algorithms and AI published by the CNIL, and in the report "Algorithms: preventing automated discrimination" published with the Défenseur des Droits. If these biases cannot be completely avoided in practice, the challenge is to reduce their consequences for individuals, by making AI systems understandable, which is what mathematics professor Philippe Besse pleads for in his interview with LINC.
In the case of word processing, the issue of bias is particularly important because language has certain specific characteristics: -
It has complex ambiguities (the use of the word "nigger", for example, is still common to designate a pen-pusher);
- It is impregnated with biases of the society (certain words are used more in feminine than in masculine, for example);
- It can be very different from one community to another, or from one social environment to another;
- It evolves over time.
This guarantees that a language model will be biased, since it will reproduce what it has been taught, even if precautions can be taken (see the settings described below).
Find out more about the useful resources on AI on the CNIL website.
In addition, the choice of vector length to represent words will also be important. The word "king", for instance, refers to a male leader of a society that recognises kingship, which was common in the Middle Ages, particularly in France. We can imagine that its representation would incorporate all these semantic proximities if the algorithm were trained on Western history textbooks. On the other hand, if we train the same algorithm on Asian history textbooks, where the history of the Kings and Queens of France will certainly be presented differently, we will probably obtain different nuances, such as "foreign" or "western", to be integrated into the vector representation. In another case, where the history of the Kings and Queens of France is simply absent from the training corpus, the word "king" could be linked to notions that are random for the model. Asking the model about the subject could result in inaccurate information, frequently referred to as 'hallucinations', which would be difficult to correct downstream (following the example of Cobus Greyling who tried to make ChatGPT "polite" by telling it to reply "Sorry, I don't know" rather than "hallucinate"). In the case of Transformers, like the one used by ChatGPT, the length of the vectors is 512 values. While a longer vector might be able to contain more information, it also requires increasing number of model parameter, and hence increases the cost of learning. A second problem emerges: how can we find a vector size that achieves the best compromise between achieving the desired level of semantic nuance and increasing computing time?
Finally, before using vector representations of words to process a text, a last operation is performed to take into account the position of the word in the sentence. Thus, the final vector representation of the word takes into account not only the meaning of the word, but also its position.
Be aware of the context
Vectoring is a first stage enabling machine to interpret isolated words, with a certain level of subjectivity, as we have seen. The second stage consists of interpreting the context of each word: this is known as the attention mechanism.
To establish a link between words in the same text, and so build a context that provides a general understanding, vector representations of each of the words in the text are compared with each other. Using a classic vector operation (a scalar product), each pair of words in the text is assigned a number representing their proximity in vector space. Intuitively, this should amount to a semantic proximity comparison between each of the words in the text, making it possible to establish links between them. This calculation is performed for the same word with all the words surrounding it: we obtain a new representation of the word integrating its link with the context[2].

Figure 3: Proximity between the word "it" and its context for the sentence "The animal did not cross the road because it was too tired". An intense colour represents a high proximity between two words (source: Uszkoreit, 2017)
In the example in Figure 3, the values indicating semantic proximity to the word 'it' are represented by more intense colours when the proximity is greater (note: not all the values are represented, some being too weak to be relevant).
In practice, this step of using the context is repeated several times, linking the words one by one through cross connections. These iterations make it possible to distinguish between similar sentences which do not, however, have the same meaning, as shown in the example in Figure 4. In these two examples, only the link between "animal" and "tired" in the first case, and between "street" and "wide" in the second, can tell whether "it" refers to "animal" or "street". The meanings of 'animal' and 'street' must therefore first be determined from the context before the meaning of 'it' can be determined.
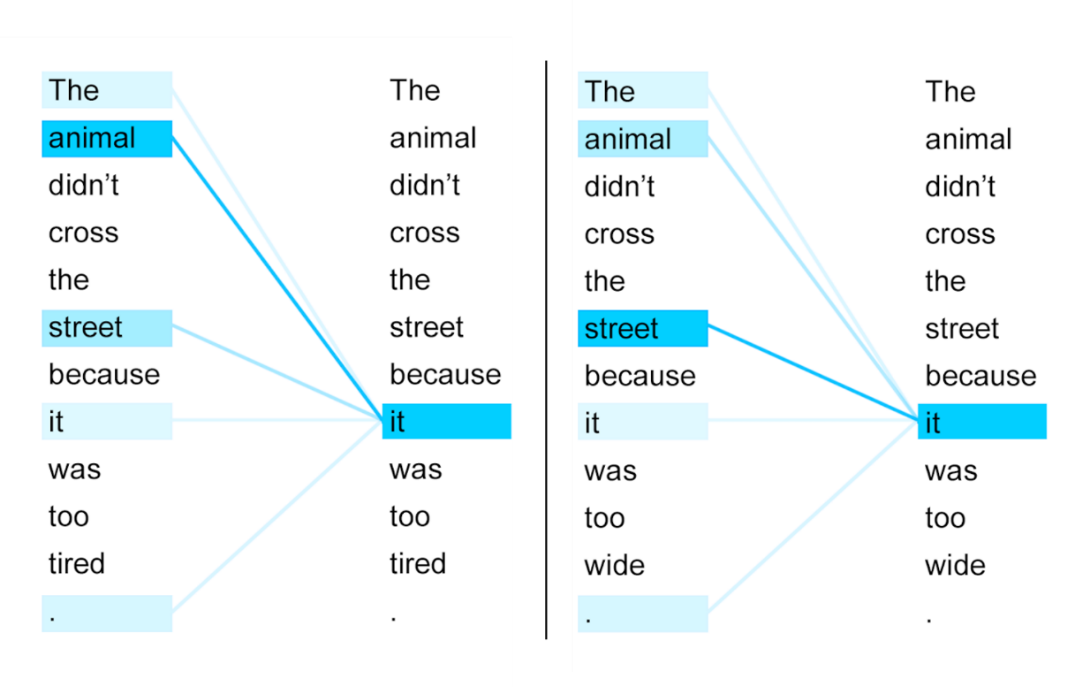
Figure 4: Proximity between the word 'it' and its context for two similar sentences. Intense colour represents high proximity between two words (source: Uszkoreit, 2017)
Transformers’ ability to use the whole context to determine the meaning of a word is one of the major advantages of this Network classes. Other types of deep learning networks, such as recurrent neural networks (RNNs), are generally less effective at this task because of a problem known as gradient fading.
Disappearance of the gradient
During training, parameters of a neural network are corrected according to the prediction error on the training data; this error is quantified by the gradient. This error is quantified by the gradient. The term gradient descent is used when an attempt is made to reduce the value of the gradient, i.e. to reduce the error.
In the case of a recurrent neural network, the gradient takes into account the contribution of a sequence of data, such as an entire sentence. However, not all the words in the sentence have the same weight in the calculation of the gradient: the further back they go in the sentence, the more their weight decreases (exponentially). As this decrease is exponential, the first words of a sentence generally no longer have any impact on the calculation of the gradient, so they are hardly ever used to correct the model parameters. This is what is known as the disappearance of the gradient: as you move up a sequence, the contribution of the elements decreases exponentially and their contribution to learning "disappears".
From language learning to chatbots
Encode, decode
The process described in the previous section is used to represent each of the words in latent space. This first stage, which corresponds to the part of the algorithm known as the "encoder", does not generate any text. This is where the second part, called "decoder", comes in.
Depending on the functionality planned for the tool, the decoder is used to implement it. Using the representation of the words in a sentence that you want to translate or complete, for example, the decoder generates words according to the probability of their occurrence. The calculation of this probability is based on the methods described above, and takes into account the semantic proximity of the word to its context, as well as its position in the sentence.
In the case of ChatGPT, what the user enters in the prompt is used as input data and encoded to create an initial context. On this basis, the Transformer algorithm on which the chatbot is based manages to generate text by selecting one by one the most likely words to construct an answer. This "encoder-decoder" set constitutes an algorithmic model, called GPT[3] in the case of ChatGPT, on which the chatbot is based. However, generate text word by word would be difficult to achieve the performance observed in ChatGPT. The model needs to be adapted to produce clear, orderly responses that comply with the user's instructions. This is where the parameter setting, or alignment, of the model comes into play.
Woupidou, when ChatGPT wants to talk like you
Designers of ChatGPT decided to focus on user expectations rather than theoretical performance during a fine-tuning phase of the model using partially supervised learning.
According to the authors of Ouyang et al, 2022 OpenAI publication in which this stage is detailed, the aim of this approach was to better match explicit expectations (following given instructions, for example) and implicit expectations (absence of bias or toxic content, plausibility of responses, etc.). Two techniques were used to achieve this:
- Supervised learning settings: standard responses are written by annotators to serve as training data for the language model. Parameters are first set according to a helpfulness metric during training, then according to truthfulness and harmlessness metrics during validation, since these metrics can conflict (if a user asks to generate toxic content, for example, harmlessness is preferable to helpfulness).
- Reinforcement learning settings: in this phase, a reward model is trained in a supervised way to recognise what is a 'good' response. This model is then used to guide the chat’s configuration: the chat generates a response, the reward model determines whether it conforms to expectations and provides a high score if it does, which is ultimately used to guide the configuration of the language model.
The authors felt that specific data collection for this parameter settings phase was necessary because public datasets poorly reflect users' actual preferences. In particular, it was noted that around 46% of the API proposed by OpenAI is used for "generating" requests (i.e. requests such as "tell me a story..."), whereas the majority of public datasets contain examples of classification, answers to specific questions, translation or text summarisation.
Lyrics (annotated), lyrics (unannotated), lyrics (partially annotated)...
As seen above, the development and improvement of ChatGPT is based on several learning phases, some of which are supervised (i.e. on annotated data), some unsupervised (i.e. on unannotated data), and some partially supervised (where an attempt is made to use some unannotated or partially annotated data for learning). For these stages, different categories and volumes of data are processed.
Unannotated data: the whole lot
Firstly, unsupervised learning is used to train the language model on which ChatGPT is based.
This technique frees us from the need to annotate data, the most cumbersome and costly stage in training a model, but requires a very large volume of data in return. According to Brown et al, 2020, several text datasets have been used, including CommonCrawl (also used by BigScience for the Bloom project, which was the subject of an interview with the LINC), the WebTextgame, Wikipedia content and literary works in the public domain. CommonCrawl and WebText are both based on Web scraping, and contain data sources for the general public such as Reddit and BlogSpot, as well as institutional sites (Europarl.eu, nasa.gov), academic sites (mit.edu, cornell.edu, berkeley.edu, cnrs.fr, etc.) and press sources (euronews.fr, lefigaro.fr, ouest-france.fr, etc.).
Figure 5: Representation of the provenance of urls harvested by CommonCrawl (source: WebDataCommons in KDNuggets in 2015)
As we can see, the representativeness of the domains targeted by CommonCrawl - which represents the majority of data for unsupervised training and whose documentation details the "Top-500" domains visited during the project - raises questions. While a large number of English-speaking universities were found in this dataset (79 websites belonging to the ".edu" domain reserved for accredited educational establishments in the United States), there was only one French university (ens-lyon.fr). Thus, disparities seem to exist between countries, not only in terms of volume of data, but also in terms of types of sources.
In addition, for the same category of data source (such as press sources), harvested domains may not be representative. In France, for instance, the only domains in the Top-500 mentioned above that correspond to press sources are ouest-france.fr and lefigaro.fr. With only two domains, if the model were to reproduce a point of view after learning it, there would be a strong risk that it would not be representative of society as a whole.
Finally, with a collection of this size, it seems difficult to judge the reliability of the sources used without specific analysis for each language. Sometimes, arbitrary criteria can be used, such as rating (WebText corpus, for example, excludes publications on Reddit that have received less than 3 "karmas"[4] , the rating used on the site). However, it remains to be proved that this rating is a guarantee of quality information, since it could be repeated by the chat.
Annotated data: the new black gold
Once the language model has been trained, it is parameterised by a supervised learning on annotated data.
As described in Ouyang et al. 2022a team of 40 annotators has been recruited to write responses that will be used as templates when the language model is parameterized. OpenAI highlights that particular attention was paid to hiring these people. The selected annotators would have demonstrated sensitivity "to the preferences of various demographic groups" and a great ability to identify "potentially harmful responses".Around 11,000 examples were used during this phase.
Partially annotated data: the best of both worlds ?
After the first parameterization by supervised learning, a second parameterization takes place by reinforcement learning. This phase requires the (supervised) training of a reward model which will be used as a guide to direct (unsupervised) learning of the model used by the chat.
To annotate the data used to train the reward model, OpenAI API was modified to allow users to select the model's best response to a question from a number of choices. Around 30,000 rated responses were obtained in this way, and are used to train a reward model capable of comparing the chat's generations with the best-rated responses and 'rewarding' it or not during training.
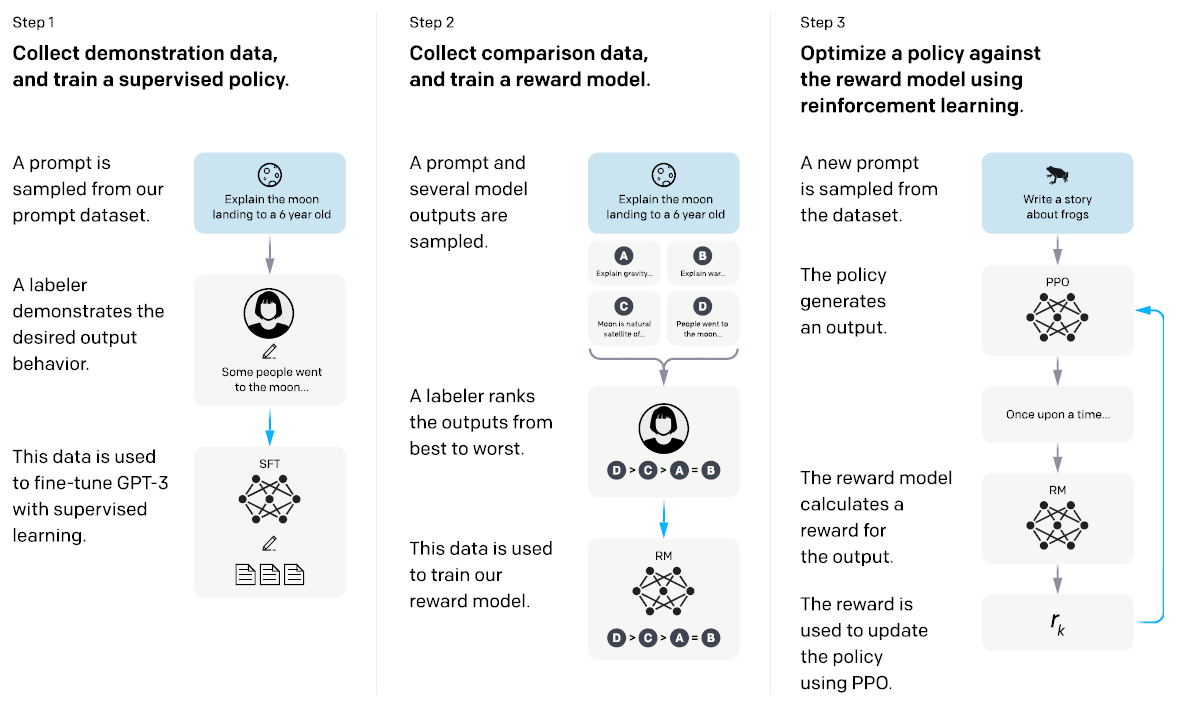
Figure 5: description of the three phases of setting up ChatGPT. This diagram does not describe the first phase of the design, i.e. the training of the language model (source: Ouyang et al., 2022)
Finally, as indicated in ChatGPT’s online help, users' conversations are reused to improve the tool's performance, without any further details, the only directly visible element being the possibility of giving a negative or positive 'thumbs up' to each response (yes no ). The site's FAQ indicates that conversations can be reviewed by annotators, so it seems likely that this data will be reused to parameterize the tool (whether for supervised or reinforcement learning).
It should be noted that there is a right to object to this re-use.
ChatGPT2.0 ?
In a blog post on 16 February 2023, OpenAI looks back at the most common criticisms of chat performance and the shortcomings observed. The company also details an action plan to take account of this feedback and improve its systems. Some of these changes have been incorporated into GPT4, according to a publication on 5 April 2023.
First of all, in order to correct the chat's biases, which reflect in particular the potential bias of annotators on some of political or controversial subjects, OpenAI has indicated that the first step will be to improve the review procedures for responses generated by examiners. To achieve this, the company wants to develop the guidelines followed by reviewers, as well as improving the demographic representativeness of reviewers. To ensure transparency, the company is also planning to publish more information about their demographic distribution. In addition, the company is looking into technical ways to make model parameterisation stage more controllable and transparent. On this subject, Glaese et al, 2022 and Bai et al. 2022 propose two different approaches. The first one aims to provide annotators with a more detailed analysis grid to enable them to detail why a response does not meet expectations. The second approach is based more on technique: a model is trained to improve text generated by the chat according to a set of rules, called "constitution". In this second approach, a second model corrects the output of the first, which learns from these errors in a reinforcement learning logic. Improved responses are then used in the reinforcement learning phase.
Finally, OpenAI provides some guidelines for the development of chat. First, the company indicates that user feedback will be used to correct bias, 'hallucinations' and the algorithm's ability to identify toxic queries. Tools enabling users to set ChatGPT to their specific use cases will also be developed. Finally, OpenAI has indicated that it would like to involve users more in the development of the tool in order to correct any shortcomings caused by too much "concentration of power".
These forthcoming developments indicate that the product is entering a market launch phase in which the aim is not only to develop a high-performance tool, but also one that meets expectations of potential customers. However, the uses to which the tool will be put, which are still emerging, raise questions of a legal and ethical nature, an analysis of which can be found in the next article in the dossier.
[1] Recurrent neural networks (RNNs) are a category of machine learning models, of which the Gated Recurrent Unit (GRU) and Long Short-Term Memory (LSTM) networks are the most common examples, capable of using the context of information such as the sentence in which a word is contained.
[2] In practice, operation of calculating attention with the context is carried out several times in parallel, since there may be several ways of interpreting the same context: this is known as multi-head attention. Parameters are trained for each of the 'heads', enabling different information to be extracted from the context. The sum of the heads thus gives a more complete interpretation of the context. According to Brown et al., 2020, the various versions of GPT3 have between 12 and 96 of these heads.
[3] Generative Pretrained Transformer.
[4] Karmas are rewards awarded by Reddit users to each other. More information on the Reddit website.

