
Incursion dans la caisse à outils de la sécurité des grands modèles de langage (2/2) : la sécurité sur le vif
Rédigé par Alexis Leautier
-
22 octobre 2024Nous poursuivons l’incursion dans la caisse à outil de la sécurité des GML par un tour d’horizon des techniques visant à sécuriser les agents conversationnels sur le vif, c’est-à-dire lors de leur utilisation.

Les mesures vues dans l’article précédent cherchent à déployer un modèle sécurisé dès la conception, mais elles ne sont pas toujours applicables selon les cas et elles peuvent manquer de garanties formelles. D’autres mesures, qui viendront s’appliquer cette fois-ci lors du déploiement du système peuvent également être prévues. Ces techniques apportent parfois des protections complémentaires aux mesures de sécurité en amont, bien qu’elles manquent, ici encore, souvent de garanties formelles.
Quatre catégories de mesures sont présentées dans ce second article :
- Les mesures prises sur les requêtes des utilisateurs afin de les protéger,
- Celles cherchant à identifier les requêtes malveillantes,
- Les techniques de détection des réponses toxiques et des hallucinations, et enfin
- Celles cherchant à identifier la présence de données d’entraînement dans les réponses.
Le tri à l’entrée pour protéger les utilisateurs
Lorsqu’une confiance totale ne peut être donnée au fournisseur d’un GML (par exemple dans le cas de l’encapsulation par un autre acteur d’un outil d’IA générative tiers), ou qu’un risque d’interception des communications existe, des stratégies peuvent être mises en place pour protéger les données des utilisateurs. La sensibilisation des utilisateurs au fonctionnement de ces systèmes et aux conditions d’utilisation attendues n’est pas traitée ici, puisqu’il ne s’agit pas d’une mesure technique, bien que son importance mérite d’être soulignée (voir encadré).
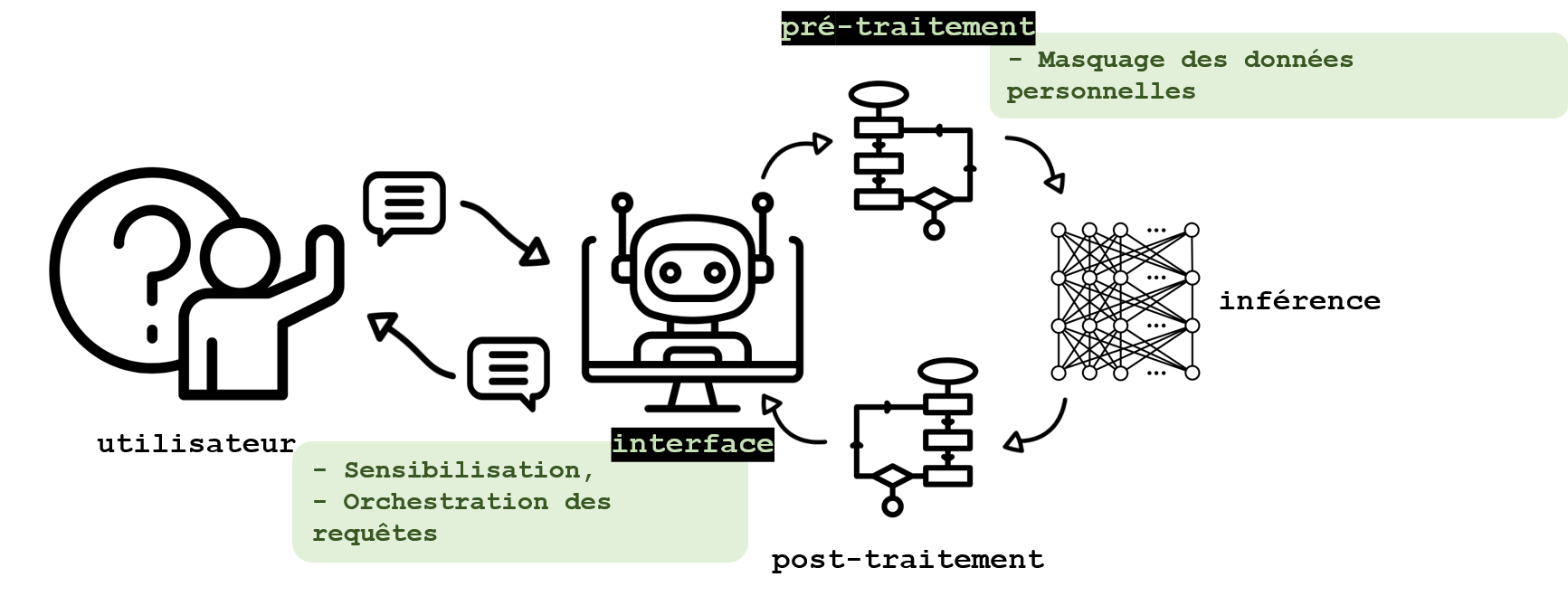
Certains outils permettent d’identifier et de masquer des informations sensibles contenues dans les requêtes. L’identification d’expressions régulières (RegEx) est fréquemment utilisée dans ce but. La reconnaissance d’entités nommées, ou NER pour named entity recognition, dont une description détaillée peut être trouvée dans cet article de blog, est une autre technique de traitement du langage fréquemment utilisée pour identifier les termes correspondant à un nom, une adresse, une date de naissance ou encore un numéro de carte bleue. Elle ne permet toutefois pas d’identifier du texte décrivant une situation personnelle plus complexe. La classification par un GML appliquée au texte en entrée peut alors être une solution pour identifier ces situations complexes, bien qu’elle doive être effectuée dans les infrastructures de l’utilisateur pour préserver la confidentialité des informations. Les outils ouverts les plus fréquents aujourd’hui sont Presidio (Microsoft), NeMo Guardrails (NVidia), ou encore Guardrails (Guardrails AI). D’autres travaux encore en cours, tel que reteLLMe, proposé par Brahem et al., 2024, utilisent les GML pour améliorer la confidentialité d’un texte, mais aussi pour évaluer la perte en utilité et les gains en confidentialité des modifications apportées. Ces pistes permettent de protéger les informations directement, mais également indirectement identifiantes.
Les outils facilitant la création d’applications fondées sur les GML tels que LlamaIndex ou LangChain, offrent généralement une intégration des fonctionnalités évoquées ci-dessus.
La formation des utilisateurs et l’éducation aux risques est une bonne pratique dont les effets peuvent difficilement être comparés aux mesures techniques mais dont les bénéfices sont incontestables. L’information sur les meilleures pratiques d’utilisation de l’agent permet notamment d’éviter la génération de certaines réponses problématiques, la génération d’hallucinations et la régurgitation de données d’entraînement intervenant généralement dans des situations particulières qui peuvent être évitées. La formation aux méthodes d’ingénierie des requêtes, ou prompt engineering, permet ainsi dans une certaine mesure de limiter qu’une requête conduise à la génération d’une réponse peu probable, pouvant donc être fausse, ou trop proche des données d’entraînement. Ces bonnes pratiques incluent aussi la clarté dans les requêtes, l’absence d’ambigüité et une longueur de requête n’approchant pas la fenêtre limite de contexte du GML. La formation à l’interprétation des réponses, et en particulier à la conduite à tenir lorsque l’outil génère des informations sur un individu peut également prévenir des conséquences nuisibles aux personnes concernées. L’impact de ces bonnes pratiques reste néanmoins limité et elles n’empêchent notamment pas les utilisations malveillantes.
Identifier et neutraliser les requêtes malveillantes
Un utilisateur malveillant pourrait utiliser un GML afin d’obtenir des informations sur les données d’entraînement. A cet égard, les techniques d’attaque sont aussi variées que les mesures protectrices trouvées dans la littérature.

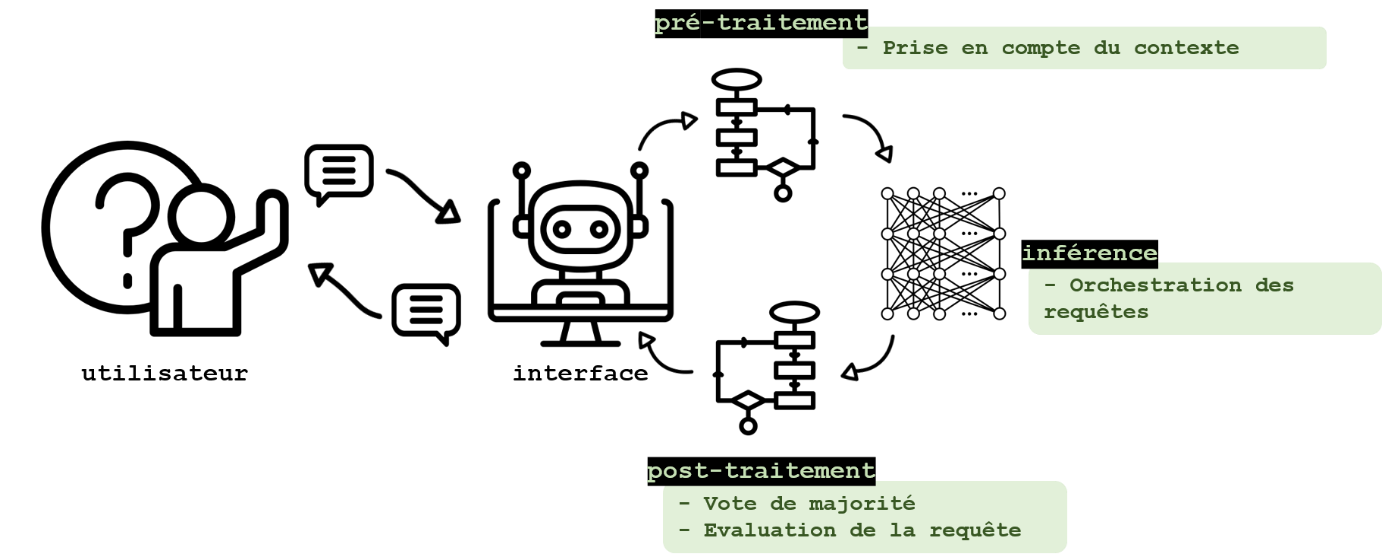
L’invite elle-même peut être conçue de telle sorte à limiter la liberté dans les requêtes ou faire l’objet d’un « retraitement » avant envoi au GML. Pour des utilisations spécifiques, l’utilisation de requêtes préconçues et dont seuls certains paramètres peuvent être modifiés permet de limiter l’utilisation de l’agent aux seuls usages prévus. Cette solution élimine généralement les risques d’utilisation malicieuse (à condition de protéger les champs laissés libres, notamment à l’injection de requêtes malveillantes), mais elle n’est applicable que dans certaines situations bien spécifiques. D’autres approches, comme celle proposée par Chen et al., 2024, parviennent à limiter le succès des attaques par débridage en séparant les instructions et les informations au sein d’une requête. Cette séparation, similaire à celle existant dans la programmation entre une fonction et ses arguments, est permise par une interface spécifique. L’inférence est ensuite réalisée par un GML conçu spécifiquement à cette fin.
Une fois la requête envoyée, si celle-ci contient une tentative de débridage, plusieurs auteurs ont montré qu’il est possible de rendre celle-ci inopérante par certaines opérations. Jain et al., 2023 étudient deux méthodologies impliquant la paraphrase des requêtes par un GML, et leur redécoupage en jetons, ou tokens, de plus petite taille (ce qui aurait pour effet de neutraliser les tentatives de débridage fondées sur des combinaisons de jetons spécifiques). Une autre approche proposée par les auteurs consiste à exploiter la perplexité d’un modèle de langage (qui mesure la probabilité de générer un jeton étant donné les jetons fournis précédemment) face à la requête afin d’identifier lorsque celle-ci est malicieuse. Ces analyses semblent prometteuses mais la robustesse nécessite encore d’être évaluée.
La classification des requêtes à l’aide d’un GML peut également permettre d’identifier les tentatives d’utilisations malveillantes comme le débridage. Yao et al., 2023 listent plusieurs approches incluant une classification sur la base de la pertinence des termes dans le contexte de la requête, ou encore sur la pertinence de la requête comparée à l’historique. Xu et al., 2024 identifient également des approches fondées sur l’analyse des activations du GML au cours du traitement de la requête. Ces approches détectent les requêtes malveillantes par exemple en réalisant une balance entre les activations correspondant à la génération d’une réponse à la demande de l’utilisateur, et celles correspondant à l’alignement du modèle (et le conduisant plutôt à refuser de répondre). Ici également, une analyse plus poussée semble nécessaire pour évaluer la robustesse de ces solutions. De plus, les approches reposant sur l’analyse du comportement du GML nécessiteraient un nouveau travail préliminaire lors de sa mise à jour, ou d’un changement de modèle.
Eviter les hallucinations et réponses toxiques
Sans protection, le fonctionnement d’un GML peut conduire à la générations de réponses toxiques reproduisant certaines données d’entraînement, ou d’hallucinations à cause du fonctionnement inhérent à ces outils. Ces réponses pouvant concerner un individu selon le contexte d’utilisation, il peut être nécessaire de prévenir leur génération, notamment grâce aux méthodes qui suivent.
Le cas des requêtes trop longues
Tout d’abord, une perte en précision peut avoir lieu lorsque la longueur de la requête approche celle de la fenêtre de contexte du GML comme démontré par Liu et al., 2023, pouvant ainsi causer des hallucinations et la génération d’informations fausses sur une personne. Les auteurs constatent qu’une information peut être mieux prise en compte dans la réponse générée si elle est placée au début (ou à la fin) d’une requête. La longueur de la fenêtre de contexte de la plupart des GML étant aujourd’hui assez longue, cet inconvénient sera plus fréquemment observé lorsque la requête contient un document par exemple. Cette limitation peut être contournée au stade du prétraitement de la requête, par des techniques de compression des requêtes telle que celle proposée par Jiang et al., 2024, ou encore en découpant la requête en sous-parties (éventuellement triées selon leur importance) et fournies au modèle indépendamment comme décrit dans cet article du site LangChain.
Séquencer la réponse
D’autres solutions incluent les méthodologies d’orchestration des requêtes, comme les approches décrites ci-dessous appelées Tree-of-thoughts (introduit par Long, 2023) et Chain-of-thoughts (introduit par Wang et al., 2022), dont certaines sources comme Mo et Xin, 2023, indiquent un apport pour la qualité et l’interprétabilité des réponses.
- Chain-of-thoughts : cette approche consiste à inciter un GML à fournir les étapes l’ayant conduit à fournir une réponse. De la même manière qu’une personne expliquerait son raisonnement, le GML peut être contraint par différentes méthodes à produire une réponse fournissant des explications cohérentes avec la réponse fournie.
- Tree-of-thoughts : contrairement à l’approche précédente, il ne s’agit pas ici d’obtenir un raisonnement de manière linéaire, mais plutôt de conduire le GML à explorer plusieurs raisonnements possibles de manière itérative. Chacune des pistes explorées est évaluée par une métrique de telle sorte à ce que seule celle obtenant le meilleur score soit suivie pour fournir une réponse.
Ces méthodes peuvent être couplées avec d’autres, comme le proposent Wang et al., 2023, qui utilisent l’approche Chain-of-thoughts couplée à un vote de majorité pour générer de multiples réponses et sélectionner la plus cohérente. Les outils d’intégration offrent également la possibilité d’apporter du contexte pour la génération de réponses (via la génération augmentée d’informations, ou RAG pour retrieval augmented generation), permettant ici aussi d’améliorer la précision des réponses. Un article d’OpenAI explique comment les trois approches (ingénierie des requêtes, exploitation du contexte, et ajustement du GML) peuvent s’articuler pour améliorer la précision des réponses. Les apports de ces techniques demandent encore à être démontrés, notamment en ce qui concerne la limitation des divulgations de données personnelles mémorisées ou hallucinées.
Des pistes existent afin de déterminer a posteriori si une réponse est toxique. Phute et al., 2024 proposent par exemple d’évaluer la nocivité des réponses en les évaluant avec un autre modèle de langage pris depuis l’étagère (Llama 2 et GPT 3.5 dans le cas de cette étude). La réponse générée est présentée au GML « juge » dans une requête préconçue, qui l’interroge sur la nocivité du texte avec une question binaire. Le GML juge se comporte ainsi comme un classifieur de nocivité (LLM as a judge).
Modérer les sorties pour protéger les données d’entraînement
Malgré la neutralisation des requêtes malveillantes et les protections contre les hallucinations et réponses toxiques, la génération de réponses contenant des données personnelles reste possible en raison du phénomène de mémorisation des données pouvant avois lieu lors de l’apprentissage. Les mesures spécifiques suivantes sont explorées pour prévenir ce risque.

Des requêtes préliminaires, ou prepromt en anglais, peuvent être utilisées afin d’orienter les réponses d’un GML et éviter qu'elles ne contiennent des données personnelles. Ces requêtes sont fusionnées aux requêtes de l’utilisateur, et agissent comme une règle pour le GML. Il est ainsi possible d’inscrire le respect du HIPAA (Health Insurance Portability and Accountability Act), loi américaine relative à la protection des dossiers médicaux, comme une règle explicite pour le modèle comme étudié par Priyanshu et al., 2023. Ces techniques sont courantes et permettent d’améliorer la qualité des requêtes d’une manière générale, toutefois leur robustesse est limitée. Tout comme l’alignement des modèles (l’ensemble des techniques consistant à faire adopter au modèle le comportement voulu vis-à-vis des utilisateurs), les requêtes préliminaires peuvent être détournées par des techniques de débridage.
Lors de la génération, Majmudar et al., 2022 proposent une approche de confidentialité différentielle pour protéger certains attributs ayant pu être mémorisés par le modèle. Par une permutation des jetons générés par le GML avec d’autres jetons dont la génération reste probable, la réponse est modifiée de telle sorte à éliminer les jetons dont la probabilité de génération est anormalement haute pour le modèle en question. Ainsi, les sorties trop spécifiques (et donc potentiellement mémorisées lors de l’apprentissage) sont pénalisées et les informations mémorisées lors de l’entraînement ont moins de chances d’être régurgitées. Cette approche encore peu rencontrée dans la littérature fournit des garanties formelles de confidentialité, au prix d’une certaine perte en utilité.
Les générations peuvent également être contraintes afin de limiter les risques de régurgitation ou les chances de succès pour une attaque. Ces contraintes dépendent du contexte, et peuvent prendre la forme d’expressions régulières, comme proposé par l’outil ReLLM. Elles peuvent également être intégrées à la requête grâce à certains outils tel que LMQL, proposé par une équipe de l’ETH Zurich, rapprochant ainsi l’ingénierie de la requête de la programmation. Dans ce cadre, la réponse du GML peut être contrainte de telle sorte à forcer le GML à générer une date, un nombre, un nom d’objet, ou encore à expliquer son raisonnement. Ici encore, ces contraintes ne constituent pas des impératifs, mais des directions pour le GML, qui peut donc y déroger, mais leur intégration dans un langage de programmation facilite leur implémentation. Elle peut également s’accompagner de limitations sur la syntaxe ou sur le nombre de générations, permettant ainsi au développeur d’une application fondée sur un GML d’éviter aux utilisateurs d’effectuer des requêtes ayant de fortes chances de conduire à une hallucination (en limitant le nombre de générations après des requêtes infructueuses par exemple).
Une fois la réponse générée, plusieurs approches existent pour identifier la présence de données personnelles. Ces approches étant très similaires à celles mises en œuvre pour détecter la présence de données personnelles dans les requêtes, elles peuvent être mises en œuvre par les mêmes outils : LLamaGuard 3 (Meta), Guardrails (Guardrails AI), NeMo Guardrails (NVidia), Rebuff (Protect AI), LangKit (WhyLabs), ou OpenAI Evals (un outil ouvert, mais conçu pour évaluer les sorties des GML propriétaires d’OpenAI pouvant toutefois être adapté à d’autres GML comme indiqué dans cet article de blog). Ces outils proposent généralement une analyse syntaxique fondées sur le NER ou les RegEx, mais également sémantique (souvent grâce à un « GML juge »).
Enfin, de même que pour l’analyse des requêtes, les outils d’intégration comme LangChain ou LlamaIndex, permettent d’automatiser l’analyse des réponses par l’ajout de composants dédiés dans les processus opérationnels.
Plus généralement
Les mesures proposées jusqu’ici possèdent certaines limitations liées à l’impact sur la précision du GML, à la latence induite, à un manque de généralisation (à des cas d’usages inattendus notamment) ou de robustesse (à d’autres modèles par exemple), etc. Ainsi, évaluer l’efficacité des outils et leur impact sur les processus opérationnels avant le déploiement et au cours de l’utilisation d’une application semble inévitable. A cette fin, les cadres d’évaluation des GML sont nombreux, bien qu’ils semblent parfois manquer de fondements théoriques et peinent à fournir des garanties formelles. La CNIL tient actuellement des travaux sur les outils d’évaluation des GML qu’elle publiera prochainement.
De plus, de nouvelles failles et vulnérabilités sont constamment découvertes. Se maintenir à jour des dernières avancées à ce sujet peut permettre d’implémenter un correctif de sécurité temporaire rapidement. Des initiatives, comme le répertoire LVE, recensent ces vulnérabilités.
Enfin, certaines approches complémentaires qui n’ont pas été listées ici peuvent permettre de se prémunir contre les risques évoqués. Parmi celles-ci, les approches intégrant les utilisateurs, par l’information sur l’utilisation des outils, ou l’éducation à leur fonctionnement sont des pistes qu’il reste à explorer.

