
[Cabanon] Quels usages pour les données anonymisées ?
Rédigé par Estelle HARY
-
09 novembre 2017Une base de données anonymisée n’a-t-elle vraiment plus aucune valeur ? Au travers des data visualisations produites, nous présentons des scénarios d’usages pour lesquels l’anonymisation n’altère pas la qualité du résultat final.

CabAnon : la visualisation
Deux visualisations distinctes, concernant des trajets de taxis, ont été réalisées comme décrites dans notre précédent article. L’une d’entre elles correspond au jeu de données initialement publié par la ville de New York, tandis que l’autre rend compte des deux jeux de données anonymisés.
Représentation précise des coordonnées des taxis
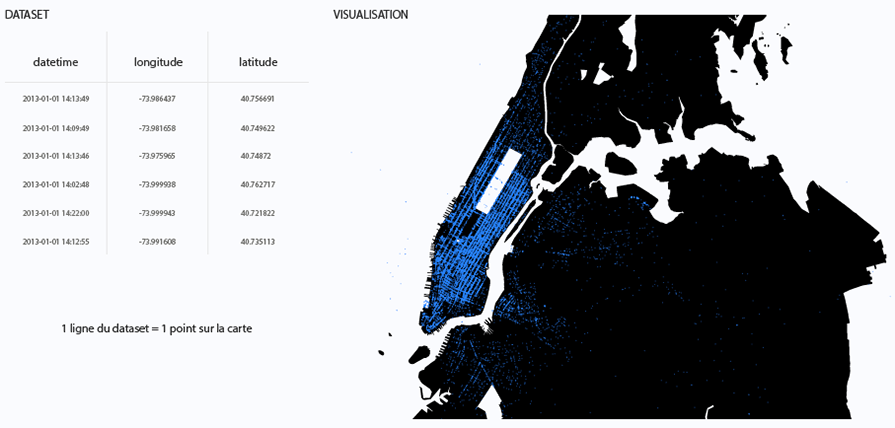
Dans le cas des données initialement publiées par la ville de New York, nous disposons des coordonnées exactes (longitude, latitude) horodatées des emplacements de chaque taxi. Nous avons pris le parti de représenter chacun de ces points sur la carte de la ville. De cette manière, il est possible d’identifier les différentes zones de densité de trafic selon la superposition de points représentant chaque taxi.
Représentation sous forme de carte choroplèthe des taxis
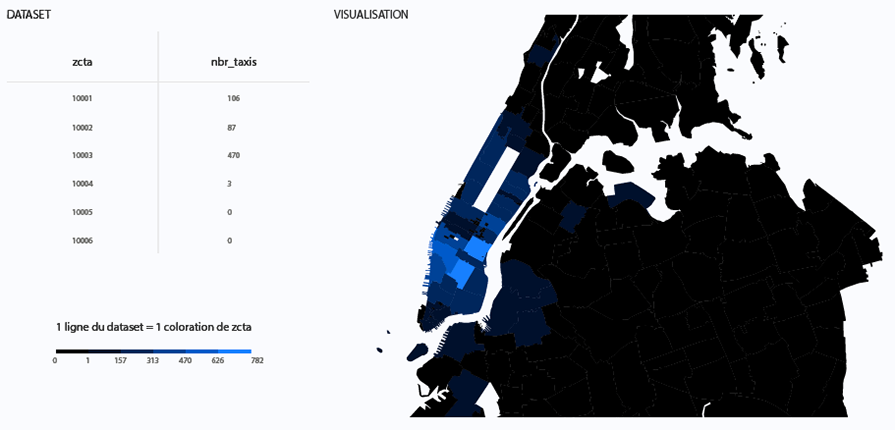
Dans le cas des données anonymisées (G29 ou Uber), les positions des taxis sont identifiées uniquement au niveau des codes postaux (Zip Code Tabulation Area (ZCTA)) de la ville. Dans chaque ZCTA à un moment donné, un nombre de taxis est calculé. Ce nombre est corrélé à une échelle de couleurs mise à jour à chaque changement d’horaire. La densité du trafic se visualise de manière plus globale, permettant des comparaisons entre chaque ZCTA.
Matrice des usages possibles des données
Nous avons imaginé plusieurs usages possibles afin d’évaluer les utilisations possibles de ces jeux de données, l’un d’entre eux étant développé plus bas, pour confronter les données anonymisées et leur utilité relative.
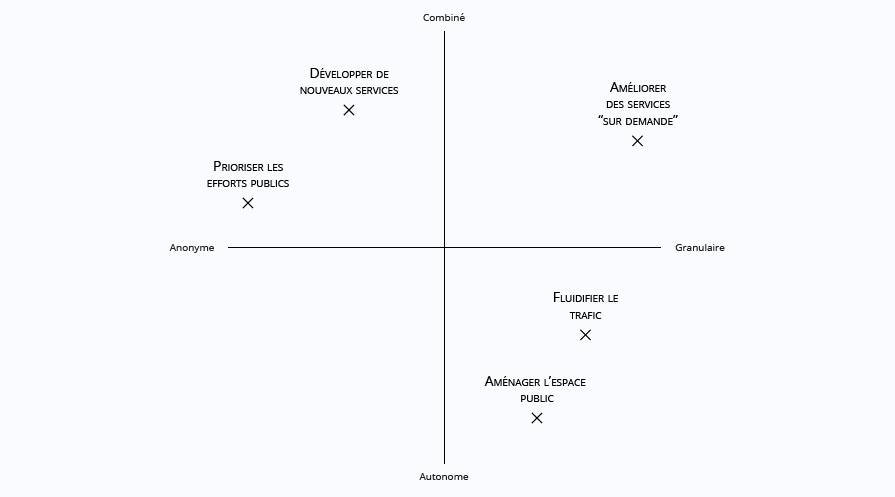
Ces usages sont répartis sur deux axes en fonction des caractéristiques des données nécessaires. L’axe horizontal (anonyme / granulaire) correspond au niveau de précision et de détail présents dans les données. Plus les données sont granulaires, plus elles fournissent des informations précises sur les déplacements et peuvent donc porter atteinte à la vie privée des individus. L’axe vertical (combiné / autonome) correspond au niveau d’indépendance du jeu de donnée des taxis de New York, c’est-à-dire si seul il peut répondre à l’usage ou s’il est nécessaire de le combiner avec d’autres jeux de données pour en tirer quelque chose.
Parmi ces usages on peut penser à :
- Prioriser les efforts publics, en déclenchant par exemple des enquêtes de terrain afin de mieux comprendre les dynamiques des flux urbains. Le but étant d’identifier les zones à étudier, les données anonymisées sont amplement suffisantes.
- Aménager l’espace public, avec entre autres le réaménageant de la voirie publique en fonction de la présence observée de véhicules. Comme il y est fait référence dans le cahier IP consacré à la smart city (p30), l’aménagement de l’espace public, notamment dans le cas de modifications faites au niveau des voiries, demande à disposer de données de géolocalisation assez précises (au moins au niveau de la rue).
- Fluidifier le trafic, en identifiant les zones à forte densité de véhicules. La fluidification du trafic demande dans certains cas à disposer de données de géolocalisation et temporelles assez précises (au moins au niveau de la rue et de quelques minutes).
- Développer de nouveaux services, en aidant l’établissement d’offres de transport alternatives ou complémentaires à celles existantes (navettes, covoiturage...). L’objectif est ici de comprendre l’environnement existant afin d’y implémenter son service. Il n’y a donc pas besoin d’avoir des données très fines. Compléter le jeu de données des taxis avec d’autres peut cependant avoir un intérêt en fonction du type de service que l’on cherche à créer ;
- Améliorer des services « à la demande », en cherchant à diminuer les temps d’attente de ses utilisateurs sur des services de véhicules sur demande. Il pourrait dans un certain nombre de cas être nécessaire d’avoir des données ayant une précision temporelle très fine.
Une exploration de l’usage possible des données publiques des taxis de la ville de New York
Créer un nouveau service de transports
Contexte
Imaginons créer un nouveau service de transport dans la ville de New York. Conscient que la concurrence est rude, il faut réussir à trouver une niche dans laquelle établir son service. Dans cette optique, il est possible d’opter pour un service se plaçant en périphérie des services de transports publics existants afin de compléter un réseau robuste et bien établi. On peut considérer créer un service de navettes proposant des micros-trajets d’une station de transport public vers le domicile d’une personne (à noter qu’Uber propose un service similaire en Floride). Pour savoir où implémenter un tel service il est nécessaire:
- d’identifier et qualifier (localisation, temps, quantité...) l’utilisation de transports alternatifs aux transports publics, comme par exemple celui des taxis ;
- de comprendre l’usage des transports publics (activité des stations, flux...) ;
- de comparer l’usage de ces différentes formes de transport et comprendre leurs superpositions et distinctions.
Comprendre la répartition des taxis
La carte choroplèthe peut nous permettre de répondre au premier point sur des plages horaires de trente minutes. Pour les deux autres, il serait nécessaire d’ajouter les données des métros de la ville de New York à la visualisation afin de facilement comparer les deux. Cela n’étant pas implémenté dans notre visualisation, nous avons fait la comparaison en utilisant les cartes du réseau des transports publics de New York distribuées par la MTA.

La visualisation permet tout d’abord d’identifier les horaires peu intéressants pour la proposition du service. Typiquement, entre 5h30 et 9h30 le nombre de taxis en circulation est faible avec moins de 150 taxis pour les zones présentant les densités de taxis les plus élevées.
L’une des plages horaires les plus chargées est celle de 02h. On remarque aussi que la majorité des taxis prenant des passagers dans Manhattan restent sur l’île. Cependant, au niveau de deux des zones les plus denses de Manhattan, Union Square (ZCTA 10003) et Lexington Avenue (ZCTA 20022), certains taxis vont vers Brooklyn et Queens, des zones moins bien desservies en termes de transports en commun que Manhattan. Qui plus est, les transports en commun circulent sur des périodes de trente minutes sur cet horaire, il est donc facile de déterminer à quelle heure les usagers des transports publics sortiront de telle ou telle station.
Pour placer de manière stratégique les navettes courtes distances du service, il serait donc préférable qu’entre 02h et 03h, elles soient placées au niveau des stations suivantes :
- 46 Street Station (11103) : lignes E, M et R
- Bedford Avenue (11211) : ligne L

Dans ce cas d’usage, nous voyons qu’il est possible d’utiliser des données anonymisées afin de comprendre un environnement spécifique. Le même exercice peut sans doute être fait avec les données originales, mais la granularité plus fine qu’elles apporteraient ne permettrait pas nécessairement d’améliorer les choix des stations. En effet ces dernières étant des endroits fixes, il est plus important de connaitre la densité moyenne au niveau d’une zone ainsi que les déplacements d’une zone à l’autre plutôt que la position et le déplacement précis de chaque taxi.
L’anonymisation d’un jeu de données, notamment via les méthodes présentées dans cet article, ne signifie donc pas une perte d’intérêt quant à son utilisation. Des solutions innovantes sont en train de voir le jour afin d’améliorer encore le ratio confidentialité/utilisabilité : la confidentialité différentielle (differential privacy), le co-clustering, etc. seront présentées dans de prochains articles.
Privacy, une question d’usage ?
Comme démontré ci-dessus, les données anonymisées peuvent être utilisées et pertinentes pour répondre à des objectifs définis dans le cadre de la mise en place d’un service ou produit. Ceci dit, certains usages demandent à avoir un niveau de granularité de données important pouvant porter préjudice à la vie privée des individus. Si la finalité d’un service ou produit est un facteur déterminant du niveau d’anonymisation nécessaire des données, ne serait-il donc pas possible de déployer de nouvelles modalités de distribution des données (publiques) de façon à encourager l’innovation et la création de services et produits numériques tout en protégeant un maximum la vie privée des usagers ? C’est ce que nous proposons dans le cahier IP5 La Plateforme d’une ville, où nous explorons quatre scénarios et autant de modalités qui pourraient permettre à l’acteur public d’avoir accès à des données de qualité.
Dans le cas des données publiques des taxis de la ville de New York, la polémique venait du fait que ces données étaient mal anonymisées et que par ailleurs, étant publiées en open data, elles étaient accessibles à n’importe quelle personne, même celles pouvant avoir des motivations questionnables. En publiant un jeu de données, il faut donc se poser la question de la technique d’anonymisation adéquate, de la facilité de l’accès au jeu de données en question et des règles et contrôles qui peuvent être mis en œuvre. Ainsi l’accès aux données pourrait être associé au respect de certaines règles en termes de réutilisation comme par exemple la compatibilité des finalités ou des demandes de protection du traitement spécifiques.
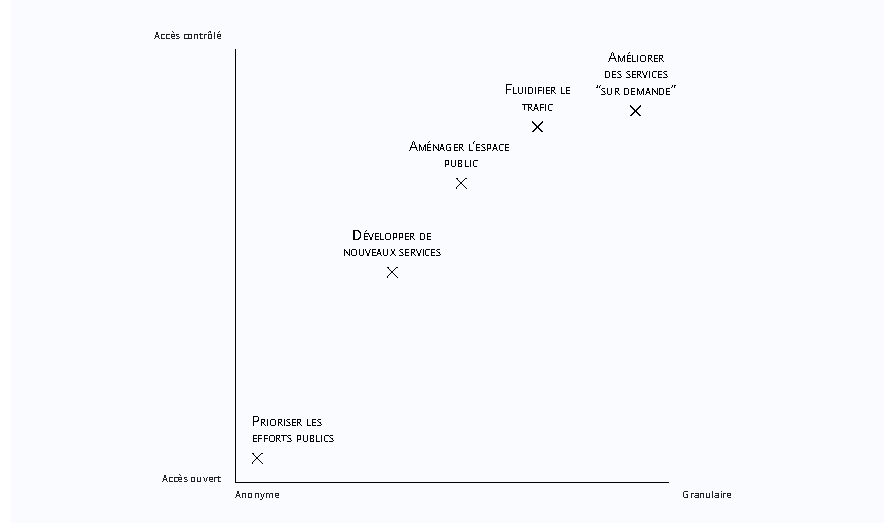
En reprenant nos exemples précédents, un service « sur demande » reposant sur des données horodatées précises pourrait très bien avoir accès à des jeux de données pseudonymisés, à condition notamment de mettre en place des mesures de protection des données importantes. Dans le cas où les données seraient anonymisées en répondant aux critères du G29, elles pourraient être publiées avec un accès libre et sans condition d’usage ou de protection spécifique.
CabAnon est ouvert sur GitHub
Cabanon est en code source ouvert ! Vous pouvez y contribuer sur notre github Linc, ainsi que jeter un œil sur nos autres projets (Cookieviz, Déréférencement...).



