
Le tatouage numérique, une mesure de transparence salutaire ? [2/2]
Rédigé par Alexis Léautier
-
27 October 2023Technique bien connue dans la protection des droits d’auteurs, le tatouage numérique appelé filigrane ou watermark en anglais, est proposé comme une solution permettant de résoudre le problème de la détection des contenus artificiels. Brandie par de nombreux acteurs comme la solution la plus robuste le tatouage numérique est pourtant une notion ambigüe dans le domaine de l’IA et peut être le nom de pratiques différentes. Cet article détaille chacune d’entre elles en s’appuyant sur une revue de littérature scientifique.

Sommaire :
- Panorama et perspectives pour les solutions de détection de contenus artificiels [1/2]
- Le tatouage numérique, une mesure de transparence salutaire ? [2/2]
Généralement associée à la transparence des contenus artificiels, le tatouage numérique en IA peut en réalité être utilisé dans divers contextes, et n’est pas une mesure salutaire comme espéré (ou clamé) par certains. En explorant les cas où cette technique peut être utilisée, nous délimitons ici le périmètre de ses fonctionnalités. Nous étudions ensuite les alternatives à cette technique, ainsi que les approches – qu’il s’agisse de règlementations ou de prises de position – des organismes et autorités sur le sujet à l’international. Enfin, nous listons les pistes envisageables pour l’utilisation de cette technique, ainsi que les réserves que les limitations de cette méthode imposent.
De quoi le tatouage numérique est-il le nom ?
Le tatouage numérique est une technique liée au domaine de la stéganographie, un domaine proche mais distinct de celui de la cryptographie. Comme pour cette dernière, l’objectif est de transmettre de façon sécurisée des informations. Cependant, alors que la cryptographie consiste en une écriture indéchiffrable d'un message ou d'une information (ainsi rendue secrète), la stéganographie va plutôt s'attacher à cacher un message dans un contenu pour qu'il soit, non pas indéchiffrable, mais indiscernable. Le tatouage est un cas particulier à cet égard, puisque l’objectif n’est pas toujours d’insérer une marque indiscernable, mais plutôt qu’elle soit inséparable de son support. L’information concernée peut être un marquage sans signification, comme par exemple le filigrane utilisé sur les photographies, ou bien un message plus complexe. Il peut être directement visible à la vue du document, ou invisible. Le document numérique, quant à lui, peut être de tout type. Toutefois, une première analyse suggère qu’il est plus aisé de tatouer une vidéo, une photo à grande résolution ou un grand modèle que de tatouer un court texte. En effet, l’efficacité d’un tatouage et sa capacité à rester attaché à l’information tatouée dépendent d’abord de la quantité d’information (ou « entropie ») du contenu à tatouer : plus la quantité d’informations du contenu est grande, plus il est facile d’y ajouter un tatouage, notamment invisible.
Dans le domaine de l’intelligence artificielle, et en particulier de l’IA générative dont certaines techniques sont détaillées dans « Données synthétiques : Dis papa, comment on fait les données ? » , une distinction en quatre catégories principales peut être opérée :
- Le tatouage de documents particuliers, comme des images, des vidéos, des documents sonores ou encore un programme informatique ;
- Le tatouage de bases de données, comme un jeu d’images, de vidéos, de musiques ou encore de programmes informatiques ;
- Le tatouage de modèles d’intelligence artificielle, comme un réseau de neurones qu’on modifie de manière à pouvoir le réidentifier ;
- Le tatouage des productions (« sorties ») des systèmes d’intelligence artificielle (SIA).
Ces catégories de tatouage visent ainsi quatre pratiques aux objectifs et enjeux différents.
Le tatouage de documents
Le tatouage de document est un concept bien connu pour la protection de la propriété intellectuelle de contenus multimédias. L’exemple des images auxquelles est apposée la marque de l’auteur ou du diffuseur afin d’assurer la traçabilité du document est particulièrement représentatif. Dans un domaine différent du tatouage numérique, la gestion des droits numériques (ou Digital Rights Management, DRM) est également fréquemment utilisée pour la protection des droits d’auteur et repose sur la restriction d’accès à un contenu (logiciel, image, DVD, système d’exploitation ou encore livre numérique) à la possession d’une clé (entrée par l’utilisateur ou fournie avec le contenu). Dans le cas de la commercialisation d’un modèle d’IA, ce principe semble applicable, toutefois il ne le serait pas pour les productions des IA génératives puisque le DRM nécessite un dispositif particulier pour la lecture du contenu protégé. De plus, ces protections sont réputées faillibles (comme dans le cas des livres numériques). En pratique, le tatouage numérique peut ainsi prendre différentes formes et viser plusieurs objectifs.
Lorsque le tatouage est visible, l’objectif est d’empêcher ou de dissuader les utilisations imprévues des documents. Le tatouage peut également permettre de prouver a posteriori qu’une personne ne pouvait ignorer que l’utilisation d’un document était illégale. Dans le cas de l’intelligence artificielle, l’entraînement sur des documents tatoués est généralement plus difficile : dans le cas d’une image, le tatouage détériore généralement la qualité de l’image et donc la performance du modèle entraîné. Toutefois, des techniques (d’IA notamment) permettent de retirer ces tatouages.
Il existe également des tatouages imperceptibles pour l’œil humain, qui peuvent être utilisés dans des objectifs similaires (pour identifier la provenance d’un document notamment, bien qu’un traitement doive être appliqué au document pour révéler le tatouage), mais également dans des contextes bien différents. C’est notamment le cas de Glaze, dont le fonctionnement est décrit dans Shan et al., 2023. Cette technique, qui diffère d’un tatouage en ce que la marque apposée n’a pas pour objectif d’être détectée par la suite, permet de dissimuler un masque – une modification subtile des pixels constituant l’image à la manière d’un voile (les auteurs utilisent le terme de « cape ») – sur des œuvres permettant de rendre impossible l’apprentissage du style artistique de l’auteur pour un SIA. L’utilisation d’une telle mesure permettrait ainsi d’empêcher la génération de contenus tentant de reproduire le style artistique d’un auteur particulier. Cette technique s’apparente ainsi davantage à de l’empoisonnement des données, sujet ayant fait l’objet de nombreuses publications et qui vise à détériorer les performances d’un modèle entraîné sur des données « empoisonnées ». Le laboratoire de l’Université de Chicago ayant publié Glaze travaille justement sur un outil, Nightshade, à visée plus généraliste et détaillé dans Shan et al., 2023, qui permettra de détériorer les performances des modèles dans tous les domaines et plus seulement dans la reproduction d’œuvres artistiques.

Résultats de tentatives de reproduction du style de l'auteur d'œuvres avec (colonne « Mimicked art when Glaze is used ») et sans (colonne « Mimicked art when Glaze is not used ») le tatouage de Glaze, source : Shan et al., 2023
Théoriquement, le tatouage de documents particuliers pourrait permettre que leur reproduction par un système d’IA génératif contienne également le tatouage, ce qui présente un intérêt en termes de protection de la propriété intellectuelle. Toutefois, la robustesse du tatouage au processus de génération ne peut être garantie.
Le tatouage de bases de données
Si l’objectif du tatouage d’un document particulier est de protéger la propriété intellectuelle qui lui est liée, le tatouage de bases de données vise, quant à lui, à maîtriser les réutilisations qui sont faites d’une base de données dans son ensemble.
Techniquement, plusieurs méthodes de tatouage existent, bien que la procédure utilisée reste toujours la même. Elle est constituée de 3 étapes :
- le tatouage de la base de données, qui peut consister en l’ajout d’un masque invisible pour l’œil humain sur des images, les rendant « radioactives » dans les termes de Sablayrolles et al., 2020, ou encore par le remplacement dans un texte de certains mots par des synonymes ou l’insertion de mots (tels que des adjectifs ou adverbes) sans modification substantielle du sens, comme proposé par Tang et al., 2023.
- l’entraînement sur la base de données tatouées, qui peuvent subir toutes sortes de modifications comme un tri, une augmentation, une dilution dans une base plus large, etc.
- dans certains cas, la détection du tatouage sur le modèle entraîné, auquel l’accès est possible selon différentes modalités (boîte blanche, ou white box quand l’auditeur dispose de l’intégralité des informations sur le système, ou boîte noire, ou black box quand il dispose d’autant d’informations qu’un attaquant externe), grâce à un test statistique. Cette détection n’existe pas dans certains cas, comme lorsque l’objectif est d’empêcher l’apprentissage sur la base de données.

Exemples de tatouages numériques appliqués à des images, permettant d'empêcher leur modification (cas de LaS-GSA), ou leur reproduction (cas de UnGAN et IAP). L’image « Adversarial » est créée par superposition d’un filtre à l’image « Original », modifiant la sortie d’un modèle de « Expected » à « Output » source : Wang et al., 2023
Le tatouage ainsi inséré, pour être efficace, devra être imperceptible pour l’œil humain ou par des tests automatisés sur les données, robuste aux modifications de la base (dilution, augmentation, etc.) et des données (compression, découpe, etc.), et causer une modification suffisante dans le comportement d’un modèle d’IA, sans diminuer la qualité des données de façon trop importante. Le test de détection du tatouage quant à lui sera limité par l’accès donné au modèle, et par la robustesse du tatouage. En effet, le test de détection reposant sur un procédé probabiliste, le résultat obtenu dans certains cas pourrait ne pas permettre de lever le doute sur l’utilisation de la base tatouée. Dans le contexte d’un contrôle, ce test devra ainsi être complété d’une enquête complémentaire. De plus, même si l’accès au modèle n’est pas toujours nécessaire pour vérifier la présence du tatouage, il faut noter que le test de détection ne sera pas toujours possible selon le contexte, puisqu’il demande a minima de pouvoir effectuer un grand nombre de requêtes sur le modèle. Enfin, les techniques recensées ne semblent pas pouvoir s’adapter à tous types de modèles. S’il est possible qu’un tatouage ait l’effet escompté sur un modèle de classification, les méthodes observées ne pourront pas être généralisées à tous types de modèles, et en particulier aux modèles génératifs, assez peu présents à ce jour dans la littérature.
Malgré ses limitations, ce modèle de tatouage pourrait permettre une plus grande traçabilité des utilisations pour l’apprentissage. En particulier, il pourrait permettre d’identifier qu’un modèle a été entraîné sur un jeu de données ouvert dont il ne respecte pas la licence d’utilisation, ou encore sur un jeu de données ayant été divulgué involontairement. Par ailleurs, le tatouage de la base de données peut également permettre d’assurer la traçabilité d’un modèle d’IA afin par exemple d’en protéger la propriété intellectuelle puisque le tatouage de la base de données peut entraîner une modification précise dans le modèle, comme décrit dans la section qui suit.
Le tatouage de modèles d’IA
Le tatouage d’une base de données est une technique qui permet notamment d’implanter une porte dérobée dans un modèle d’IA afin de l’identifier ultérieurement. Cette porte dérobée n’a ici pas un objectif malveillant, ce qui est souvent sous-entendu par ce terme et précisé dans l’article du LINC « Petite taxonomie des attaques des systèmes d’IA ». Toutefois, cette méthode aura généralement pour effet de modifier ses performances et ses fonctionnalités. Le tatouage du modèle est une solution qui permet parfois de pallier cette difficulté. Plusieurs techniques ressortent d’une analyse de la littérature : Regazzoni et al., 2021, ou encore Li et al., 2021, effectuent une classification des méthodes recensées. Le tatouage d’un modèle d’IA peut être effectué de différentes manières :
- Par l’injection d’une porte dérobée dans le modèle (tatouage dynamique). Le modèle est entraîné sur des données sélectionnées afin de lui apprendre une tâche particulière. La porte dérobée ainsi implantée dans le modèle permettra de l’identifier en effectuant des requêtes spécifiques, comme par exemple en lui soumettant des données candidates dont on sait qu’elles ont été marquées. Cette technique s’approche du tatouage de la base de données, bien qu’ici l’objet protégé soit le modèle.
- Par l’injection d’un tatouage dans les poids du modèle (tatouage statique). Un protocole d’apprentissage particulier permettra par exemple d’implanter un tatouage dans les poids du modèle lors de son apprentissage. Cette implantation peut se faire au moyen d’une fonction de coût (c’est-à-dire la fonction qui mesure la performance du modèle au cours de l’apprentissage et en donne ainsi la direction générale) spécifiquement conçue pour cela : on parle alors de mesure de régularisation. Cette technique peut également être utilisée afin de tracer une instance particulière d’un modèle lorsque le tatouage comporte un identifiant unique. Le test de détection reposera alors sur une étude des poids du modèle dans un accès en boîte blanche, ou sur l’étude de requêtes effectuées en grand nombre, permettant de reconstituer une partie du modèle (boîte grise ou noire).
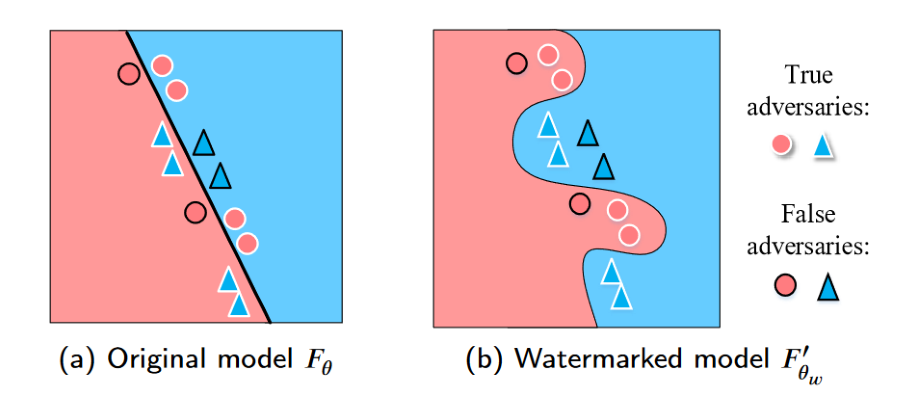
Tatouage d'un modèle de classification par modification de son comportement sur des exemples adverses ("True adversaries"), source : Li et al., 2021
Les méthodes observées sont généralement imperceptibles à l'utilisation, mais elles sont confrontées à un nombre important de difficultés. Premièrement, l’insertion du tatouage ne doit pas diminuer les performances du modèle, ce qui peut poser une difficulté dès lors que ses fonctionnalités (tatouage dynamique) ou ses poids (tatouage statique) sont altérés. Deuxièmement, le tatouage devra être robuste aux modifications apportées au modèle, que celles-ci soient des opérations courantes dans un processus opérationnel et parfois conseillée dans un objectif de protection des données, comme détaillé dans l’article « Sécurité des systèmes d’IA, les gestes qui sauvent » (comme le pruning, qui consiste à supprimer certains des neurones d’un réseau pour rendre son fonctionnement plus rapide, sans en détériorer les performances, le fine-tuning qui consiste en un réentraînement d’un modèle sur une base de données réduite mais plus spécifique à la tâche visée, ou encore la compression du modèle, c’est-à-dire l’application de techniques de compressions habituelles en traitement du signal à un modèle d’IA, ce qui permet de réduire la mémoire qu’il occupe ), ou liées à une attaque. Lorsque le modèle est ouvert (en source ouverte par exemple), les attaques visant à supprimer le tatouage pourraient être particulièrement faciles à mettre en œuvre. Enfin, il semble que seul le tatouage statique associé avec un accès en boîte blanche au modèle permette de vérifier la présence du tatouage sans équivoque. Les autres techniques ne fourniront ainsi qu’un résultat probabiliste qu’il sera nécessaire de vérifier par la suite.
Il est à noter que ces méthodes ne permettent pas nécessairement d’identifier que la sortie d’un modèle a été générée artificiellement, bien que des méthodes particulières le permettent comme décrit ci-dessous.
Le tatouage des productions d’IA génératives
Plusieurs techniques peuvent être utilisées afin de tatouer les productions d’IA génératives, comme celles insérant un tatouage a posteriori dans chacune des productions. Toutefois, ces techniques sont généralement peu robustes, peuvent détériorer la qualité des productions et ne peuvent se généraliser à des modèles ouverts. Des techniques similaires au tatouage de bases de données ou de modèles, et recensées par Wang et al., 2023, permettent de modifier un modèle d’IA de telle sorte que ses productions soient systématiquement tatouées. Les techniques observées peuvent être classées en deux catégories :
- L’apprentissage sur des données contenant le tatouage à reproduire : les données d’entraînement sont alors elles-mêmes tatouées, et le protocole d’apprentissage peut être modifié de sorte à intégrer la reproduction du tatouage comme un objectif parallèle à l’apprentissage ;
- L’apprentissage de la tâche de tatouage, par modification du protocole d’apprentissage ou par un paramétrage spécifique du modèle pendant lequel celui-ci apprend à reproduire le tatouage dans les données générées.
Ces méthodes sont soumises aux mêmes difficultés que celles observées pour le tatouage de bases de données et de modèles : la tâche de tatouage devra être suffisamment robuste et imperceptible dans le modèle. Cependant, cette méthode présente l’avantage de faciliter la diffusion des modèles d’IA puisqu’il est relativement complexe de modifier le modèle pour retirer le tatouage.
Les méthodes recensées semblent concerner principalement les modèles de génération d’images. Les méthodes de tatouage du texte quant à elles semblent encore manquer de maturité. L’une d’entre elle, testée sur ChatGPT par OpenAI, est décrite par Kirchenbauer et al., 2023. Elle repose sur l’insertion privilégiée de mots appartenant à une « liste verte » qu’il est par la suite possible de détecter dans le texte généré. Toutefois, cette méthode repose sur un test statistique dont les résultats peuvent être moins probants sur un texte court, dans un registre lexical différent, ou encore si des modifications sont apportées au texte généré. En particulier, ce texte deviendrait obsolète si un attaquant parvenait à reproduire la liste verte (celle-ci étant mise à jour à chaque nouvelle génération de mot, ou de token, ce risque est assez peu vraisemblable en pratique).
Le tatouage des productions d’IA génératives permet ainsi d’en assurer la traçabilité, et en particulier de vérifier qu’un contenu est artificiel et d’en connaître la provenance. Ces mesures semblent particulièrement utiles alors que les contenus artificiels commencent à apparaître dans des contextes de désinformation, comme dans le cas de l’utilisation de fausses images lors de la campagne pour la présidence de Ron DeSantis ou d’un faux enregistrement sonore ayant eu un impact sur des élections législatives en Slovaquie. Peu de chemin reste à parcourir avant la création d’une personne entièrement fictive, comme cela avait été exploré dans l’article « IArnaques, Crimes et Botanique », tant le réalisme de ces outils tend à s’accroître.
En conclusion
Les méthodes présentées dans cette revue de littérature possèdent certains inconvénients, mais elles permettent d’atteindre certains objectifs comme la traçabilité de documents particuliers, de bases de données, des modèles, ou encore de certaines catégories de productions comme les images, le texte, le code ou encore les documents sonores. Les approches observées manquent toutefois d’unité, un problème lié à l’absence de standards dans le domaine. Par ailleurs, une zone d’ombre semble persister sur le tatouage de contenu textuel, qui reste a priori le plus difficile à tatouer de manière robuste du fait de la faible quantité d’information contenue dans un texte.
De plus, l’ensemble des techniques proposées demande une action positive du concepteur de l’objet (document, base de données, modèle ou production du modèle) à protéger. Ce schéma peut être envisageable dans un objectif de protection de la propriété intellectuelle, mais il semble inadéquat lorsqu’il s’agit de protéger des données personnelles, ou de détecter du contenu artificiel, en particulier lorsque le concepteur ou l’utilisateur d’une IA générative est malveillant.



{kind=link}