Foray into the security toolbox of large language models (2/2): security on the fly
Rédigé par Alexis Leautier
-
22 October 2024We are continuing the foray into the LLM security tool box with an overview of techniques aimed at securing conversational agents on the fly, i.e. during their use.

The measures seen in the previous article seek to deploy a secure model by design, but they are not always applicable, depending on the case, and may lack formal safeguards. Other measures, which will apply this time during the deployment of the system, may also be provided. These techniques sometimes provide additional protection as a complement to upstream security measures, although here again they often lack formal guarantees.
Four categories of measures are presented in this second article:
- Measures taken on user queries in order to protect them,
- Measures seeking to identify malicious queries,
- Techniques for detecting toxic responses and hallucinations, and finally
- Measures seeking to identify the presence of training data in the responses.
Input sorting to protect users
When the provider of a LLM is not entirely trusted (for example, in the case of another player encapsulating a third-party generative AI tool), or when there is a risk of interception of communications, strategies can be put in place to protect user data. User awareness of the operation of these systems and the expected conditions of use are not addressed here, since it is not a technical measure, although its importance deserves to be highlighted (see box).
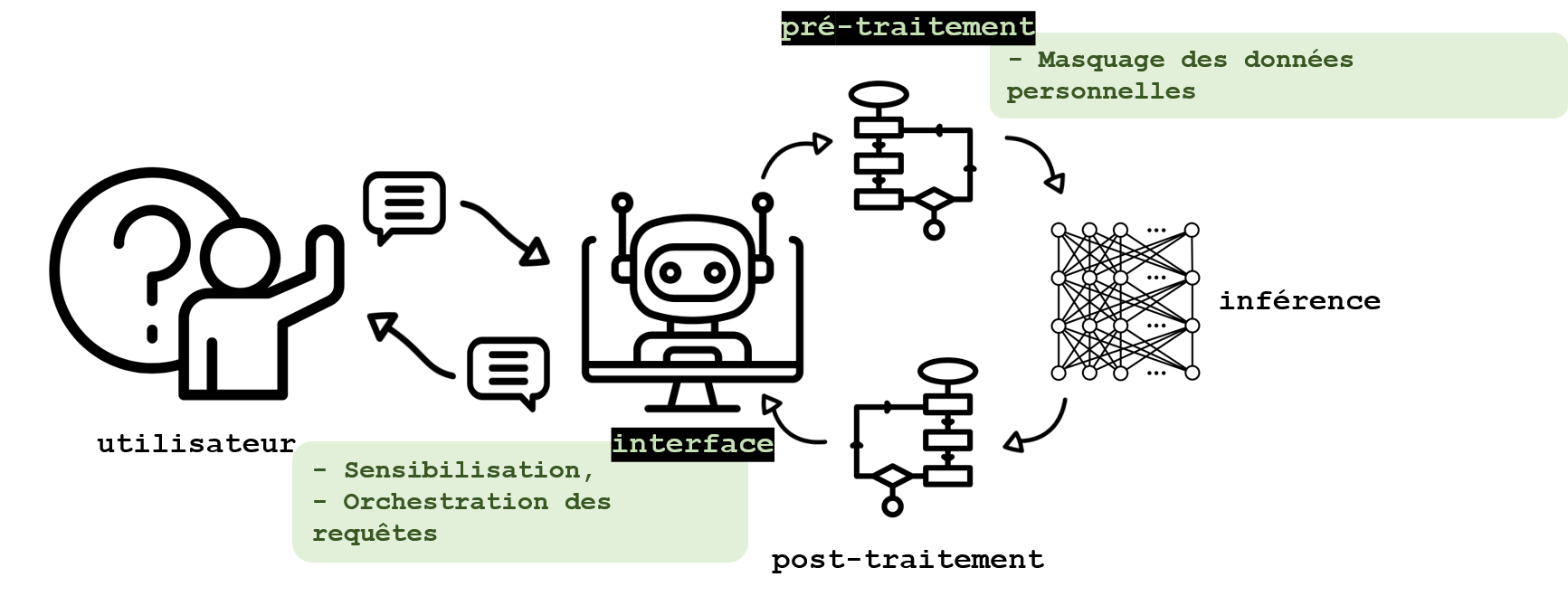
Some tools are used to identify and hide sensitive information contained in queries. Regular expression identification (RegEx) is frequently used for this purpose. Recognition of named entities, or NER (named entity recognition), a detailed description of which can be found in this blog post, is another language processing technique frequently used to identify terms corresponding to a name, address, date of birth or a blue card number. However, it does not make it possible to identify text describing a more complex personal situation. The classification by an LLM applied to the input text can then be a solution to identify these complex situations, although it must be done in the user’s infrastructure to preserve the confidentiality of the information. The most common open tools today are Presidio (Microsoft), NeMo Guardrails (NVidia), or Guardrails (Guardrails AI). Other work still in progress, such as reteLLMe, proposed by Brahem et al., 2024, use LLMs to improve the confidentiality of a text, but also to assess the loss of usefulness and the confidentiality gains of the changes made. These avenues make it possible to protect information that is directly, but also indirectly, identifying.
Tools facilitating the creation of applications based on LLMs such as LlamaIndex or LangChain generally offer integration of the features mentioned above.
User training and risk education is a good practice whose effects can hardly be compared to technical measures but whose benefits are indisputable. Information on best practices for the use of the agent makes it possible to avoid the generation of certain problematic responses, the generation of hallucinations and the regurgitation of training data generally occurring in particular situations that can be avoided. Training in prompt engineering thus makes it possible to limit to a certain extent situations where a prompt leads to the generation of an unlikely response, which may therefore be false, or too close to the training data. These best practices also include clarity in queries, lack of ambiguity and a prompt length well within the LLM context limit window. Training in interpreting responses, and in particular what to do when the tool generates information about an individual, can also prevent harmful consequences for the data subjects. However, the impact of these best practices remains limited and they do not prevent malicious uses, in particular.
Identify and neutralise malicious queries
A malicious user could use a LLM to obtain information about the training data. In this respect, the attack techniques are as varied as the protective measures found in the literature.

The prompt itself can be designed to limit freedom in queries or be “reprocessed” before being sent to the LLM. For specific uses, the use of pre-designed queries whose parameters can only be modified makes it possible to limit the use of the agent to the intended uses only. This solution generally eliminates the risk of malicious use (provided that the fields left free are protected, especially when injecting malicious queries), but it is only applicable in certain very specific situations. Other approaches, such as the one proposed by Chen et al., 2024, manage to limit the success of jailbreak attacks by separating instructions and information within a query. This separation, similar to the separation in programming between a function and its arguments, is enabled by a specific interface. The inference is then performed by a LLM specifically designed for this purpose.
Once the query has been sent, if it contains a jailbreak attempt, several authors have shown that it is possible to render it inoperative by certain operations. Jain et al., 2023 study two methodologies involving the paraphrase of queries by a LLM, and their redistribution into tokens of smaller size (which would have the effect of neutralising jailbreak attempts based on specific token combinations). Another approach proposed by the authors is to exploit the perplexity of a language model (which measures the probability of generating a token given the tokens previously provided) in the face of the query to identify when it is malicious. These analyses seem promising but their robustness still needs to be assessed.
Classifying queries using a LLM can also help identify malicious use attempts such as jailbreaking. Yao et al., 2023 list several approaches including classification based on the relevance of the terms in the context of the query, or on the relevance of the query compared to the history. Xu et al., 2024 also identify approaches based on analysis of LLM activations during query processing. These approaches detect malicious queries, for example by balancing the activations corresponding to the generation of a response to the user’s query, and those corresponding to the alignment of the model (and instead leading it to refuse to respond). Here too, further analysis seems necessary to assess the robustness of these solutions. In addition, approaches based on the analysis of the behaviour of the LLM would require further preliminary work when it is updated or after a model change.
Avoiding hallucinations and toxic responses
Without protection, the operation of a LLM can lead to the generation of toxic responses reproducing certain training data, or hallucinations due to the operation inherent in these tools. As these responses may concern an individual depending on the context of use, it may be necessary to prevent their generation, in particular through the following methods.
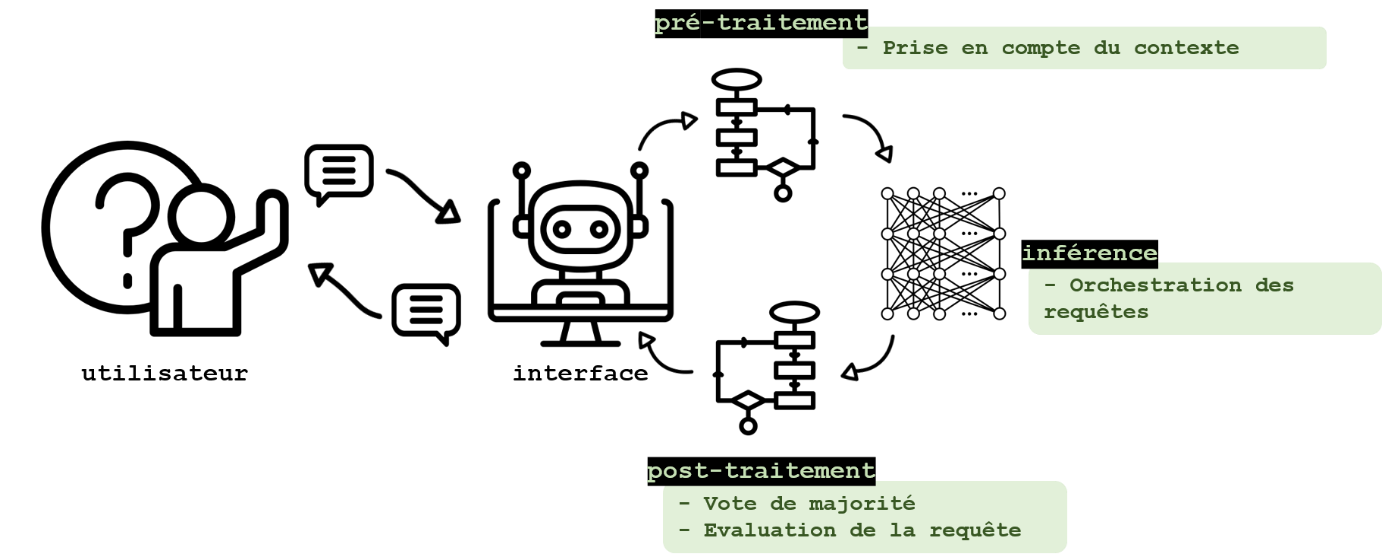
The case of queries that are too long
First, a loss of accuracy can occur when the length of the query approaches that of the LLM context window as demonstrated by Liu et al., 2023. This can cause hallucinations and the generation of false information about an individual. The authors note that information can be better considered in the response generated if it is placed at the beginning (or end) of a query. As the length of the context window of most LLMs is now quite long, this disadvantage will be more frequently observed when the query contains a document, for example. This limitation can be circumvented at the query pre-processing stage by query compression techniques such as that proposed by Jiang et al., 2024, or by splitting the query into sub-parts (possibly sorted according to their importance) and supplied to the template independently as described in this article from the LangChain website.
Sequencing the response
Other solutions include query orchestration methodologies, such as the approaches described below called “Tree-of-thoughts” (introduced by Long, 2023) and “Chain-of-thoughts” (introduced by Wang et al., 2022), with which some sources such as Mo and Xin, 2023 indicate a contribution to the quality and interpretability of the responses.
- Chain-of-thoughts: this approach consists of encouraging a LLM to provide the steps that led it to provide a response. In the same way that an individual would explain their reasoning, the LLM may be forced by different methods to produce a response that provides explanations consistent with the response provided.
- Tree-of-thoughts: contrary to the previous approach, this is not a question of obtaining reasoning in a linear manner, but rather of leading the LLM to explore several possible reasonings iteratively. Each of the tracks explored is evaluated by a metric so that only the one with the best score is followed to provide a response.
These methods can be combined with others, as proposed Wang et al., 2023, who use the approach Chain-of-thoughts coupled with a majority vote to generate multiple responses and select the response that is the most consistent. Integration tools also offer the possibility of providing context for the generation of responses (via retrieval augmented generation, or RAG), which also makes it possible to improve the accuracy of responses. An OpenAI article explains how the three approaches (prompt engineering, context exploitation, and LLM adjustment) can be articulated to improve the accuracy of responses. The contributions of these techniques still need to be demonstrated, particularly with regard to the limitation of disclosures of stored or hallucinated personal data.
There are avenues to determine a posteriori whether a response is toxic. Phute et al., 2024 propose, for example, assessing the harmfulness of the responses by evaluating them with another language model taken from the shelf (Llama 2 and GPT 3.5 in the case of this study). The generated response is presented to the “judge” LLM in a predesigned query, which asks it about the harmfulness of the text with a binary question. The LLM judge thus behaves like a classifier of harm (LLM-as-a-judge).
Moderating outputs to protect training data
Despite the neutralisation of malicious queries and protections against hallucinations and toxic responses, the generation of responses containing personal data remains possible due to the phenomenon of data storage that may occur during learning. The following specific measures are being explored to prevent this risk.

Preprompts can be used to guide responses from a LLM and prevent them from containing personal data. These queries are merged with user queries and act as a rule for the LLM. It is thus possible to enter compliance with HIPAA (Health Insurance Portability and Accountability Act), the U.S. medical records protection act, as an explicit rule for the model as reviewed by Priyanshu et al., 2023. These techniques are common and make it possible to improve the quality of queries in general; however, their robustness is limited. Just like model alignment (the set of techniques consisting of having the model adopt the desired behaviour towards users), preprompts can be diverted by jailbreaking techniques.
During generation, Majmudar et al., 2022 propose a differential privacy approach to protect certain attributes that may have been memorised by the model. By permutation of the tokens generated by the LLM with other tokens whose generation remains probable, the response is modified so as to eliminate tokens whose probability of generation is abnormally high for the model in question. Thus, outputs that are too specific (and therefore potentially memorised during learning) are penalised and information memorised during training is less likely to be regurgitated. This approach, still rarely encountered in the literature, provides formal guarantees of confidentiality, at the cost of a certain loss of usefulness.
Generations may also be constrained to limit the risk of regurgitation or the chances of success for an attack. These constraints depend on the context, and may take the form of regular expressions, as proposed by the tool ReLLM. They can also be integrated into the query using certain tools such as LMQL, proposed by a team from ETH Zurich, thus bringing the prompt engineering closer to the programming. In this context, the LLM response may be constrained in such a way as to force the LLM to generate a date, a number, an object name, or to explain its reasoning. Here again, these constraints are not imperatives, but directions for the LLM, which can therefore deviate from them, but their integration into a programming language facilitates their implementation. It can also be accompanied by limitations on the syntax or on the number of generations, thus allowing the developer of an LLM-based application to prevent users from making queries that are likely to lead to hallucination (by limiting the number of generations after unsuccessful queries, for example).
Once the response has been generated, several approaches exist to identify the presence of personal data. Since these approaches are very similar to those implemented to detect the presence of personal data in queries, they can be implemented by the same tools: LLamaGuard 3 (Meta) Guardrails (Guardrails AI) NeMo Guardrails (NVidia), Scrap (Protect AI), LangKit (WhyLabs), or OpenAI Evals (an open tool, but designed to evaluate the outputs of OpenAI proprietary LLMs, which can however be adapted to other LLMs as indicated in this blog post). These tools generally offer a syntactic analysis based on the NER or RegEx, but also a semantic analysis (often thanks to a “LLM judge”).
Finally, as well as for query analysis, integration tools such as LangChain or LlamaIndex make it possible to automate the analysis of responses by adding dedicated components to the operational processes.
More generally
The measures proposed so far have certain limitations related to the impact on the accuracy of the LLM, the induced latency, a lack of generalisation (particularly in cases of unexpected uses) or robustness (in other models for example), etc. Thus, assessing the effectiveness of the tools and their impact on the operational processes before deployment and during the use of an application seems inevitable. To this end, the evaluation frameworks for LLMs are numerous, although they sometimes seem to lack theoretical foundations and struggle to provide formal guarantees. The CNIL is currently working on LLM assessment tools, which it will publish shortly.
In addition, new flaws and vulnerabilities are constantly being discovered. Keeping up to date with the latest developments on this subject can allow a temporary security patch to be implemented quickly. Initiatives, such as the LVE directory, identify these vulnerabilities.
Finally, some complementary approaches that have not been listed here may make it possible to protect against the risks mentioned. Among these, approaches that incorporate users through information on the use of tools or education in how they work are areas that still need to be explored.