
Présentation du projet : expérimenter des scénarios d’exercice de droits pour éclairer la position de la CNIL
Rédigé par Anna Charles, Stagiaire IA et Nicolas Berkouk, Expert Scientifique IA
-
12 décembre 2025La CNIL a développé un outil permettant de structurer et de naviguer à travers les liens généalogiques entre modèles d’IA en source ouverte. Cette expérimentation vise à construire la réflexion de la CNIL sur la façon dont les droits des personnes pourraient s’exercer dans l’éventualité où leurs données seraient mémorisées par un modèle.

Exercer ses droits sur des modèles d’IA
Pour les modèles d’IA soumis au RGPD, les personnes concernées par la mémorisation ont des droits sur leurs données, tels que le droit d’opposition, d’accès ou d’effacement. Il faut noter que ces droits ne sont pas absolus, et qu’un responsable de traitement peut y déroger dans plusieurs situations, par exemple lorsque la demande est manifestement infondée ou excessive (article 12), ou bien que celui-ci n’est pas en mesure d’identifier la personne concernée (pour plus de détail, voir fiche sur l’exercice des droits).
Dans un contexte où les instances européennes confirment que le droit à la protection des données s’applique également aux modèles d’IA (voir avis CEPD 28/2024 sur les modèles d’IA), la CNIL souhaite étudier les conditions dans lesquelles ceux-ci pourraient s’appliquer au sein de l’écosystème très dynamique de l’IA open-source.
Généalogie des modèles
Le foisonnement de modèles et de jeux de données échangés librement pose des questions vis-à-vis de la protection des données personnelles, ainsi leur traçabilité devient un enjeu majeur. Par exemple, dans le cas où les données à caractère personnelle d’un individu seraient mémorisées par un modèle, comment est-il possible d’identifier les modèles par lesquels ces données seraient également susceptibles d’être mémorisées ? En effet, dans la figure 1, il est possible de voir un exemple de ruissellement des données à caractère personnel : au fur et à mesure qu’un modèle (entraîné sur un jeu de données 1 contenant des données personnelles) est repris et de nouveau entraîné, les données du jeu 1 peuvent ruisseller dans les modèles descendants. Ainsi, le modèle 3 est lui aussi susceptible de régurgiter des données à caractère personnel.
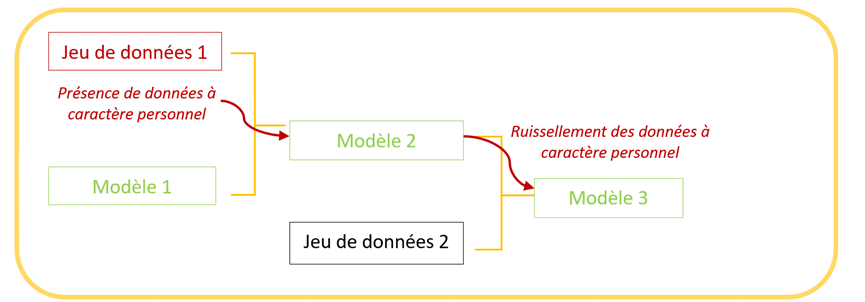
Figure 1 : exemple de généalogie de modèles (auteurs)
De fait, s’il y a un risque de régurgitation des données personnelles par les modèles, il y a aussi un risque de ruissellement de ces données lorsque les modèles sont publiés et réutilisés.
Ainsi, dans le cadre de l’IA open-source, il semble primordial de pouvoir analyser et naviguer dans la généalogie des modèles échangés. Pour un modèle donné publié, il s’agit en premier lieu de pouvoir identifier les modèles ascendants (ceux qui ont permis la création du modèle choisi), mais également, les modèles de la descendance (les modèles créés à partir de celui-ci, c’est-à-dire les enfants, petit-enfants, etc.).
Transformer la base de données
Le point de départ du projet est l’étude de la base de données accessible librement sur HuggingFace, celle-ci est mise à jour quotidiennement et contient la description de tous les modèles et jeux de données publiés sur la plateforme. Elle est actuellement composée d’environ 2 millions de modèles et 500 000 jeux de données (« datasets »). Des informations descriptives sont remplies, la plupart du temps de manière déclarative par l’entité qui téléverse le modèle ou le jeu de données.
En particulier, il est possible, pour un modèle, d’indiquer à partir de quel(s) autres modèle(s) celui-ci a été constitué. Par exemple, la page HuggingFace du modèle, publié par Mistral, intitulé « Mistral-7B-Instruct-v0.1 » nous indique que son modèle d’origine est « Mistral-7B-v0.1 » lui aussi publié par Mistral. Le lien qui relie les deux modèles est un lien d’ajustement car « Mistral-7B-Instruct-v0.1 » est une version « finetuned » du modèle d’origine « Mistral-7B-v0.1 ». Par ailleurs, le modèle « Mistral-7B-Instruct-v0.1 » est lui-même à l’origine de plusieurs autres modèles générés selon l’une des 4 relations de transformation possibles.
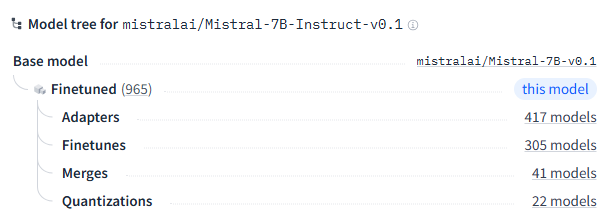
Figure 2 : Extrait de mistralai/Mistral-7B-Instruct-v0.1 · Hugging Face
En structurant ces liens de proche en proche, cela permet de construire un graphe de connaissance des modèles de la plateforme. Pour ce faire, il faut définir les types de sommets du graphe possible, ainsi que les types de liens possibles entre ces sommets, c’est-à-dire une ontologie. Ainsi, à partir de la base de données de HuggingFace, nous nous sommes arrêtés sur l’ontologie suivante.

Figure 3 : Ontologie du graphe de connaissance
Outil de mise à disposition et d’exploration du graphe
À partir du graphe établi, nous avons développé un outil de mise à disposition de cette base de données à des utilisateurs finaux. La conception de cet outil accompagne les réflexions de la CNIL afin de déterminer comment le RGPD devrait s’appliquer au sein de l’écosystème très dynamique de l’IA open-source.
Pour cela, nous avons choisi un cas d’usage type : Alice Dupont fait une requête à un agent conversationnel basé sur le modèle fictif que nous appellerons « modèle A », en lui demandant ce que le modèle sait sur elle. En réponse, il renvoie son adresse postale et sa date de naissance. Elle veut exercer ses droits et connaître les modèles qui auraient mémorisé ses données. Elle se rend sur la page internet de l’outil et cherche le modèle « modèle A ».
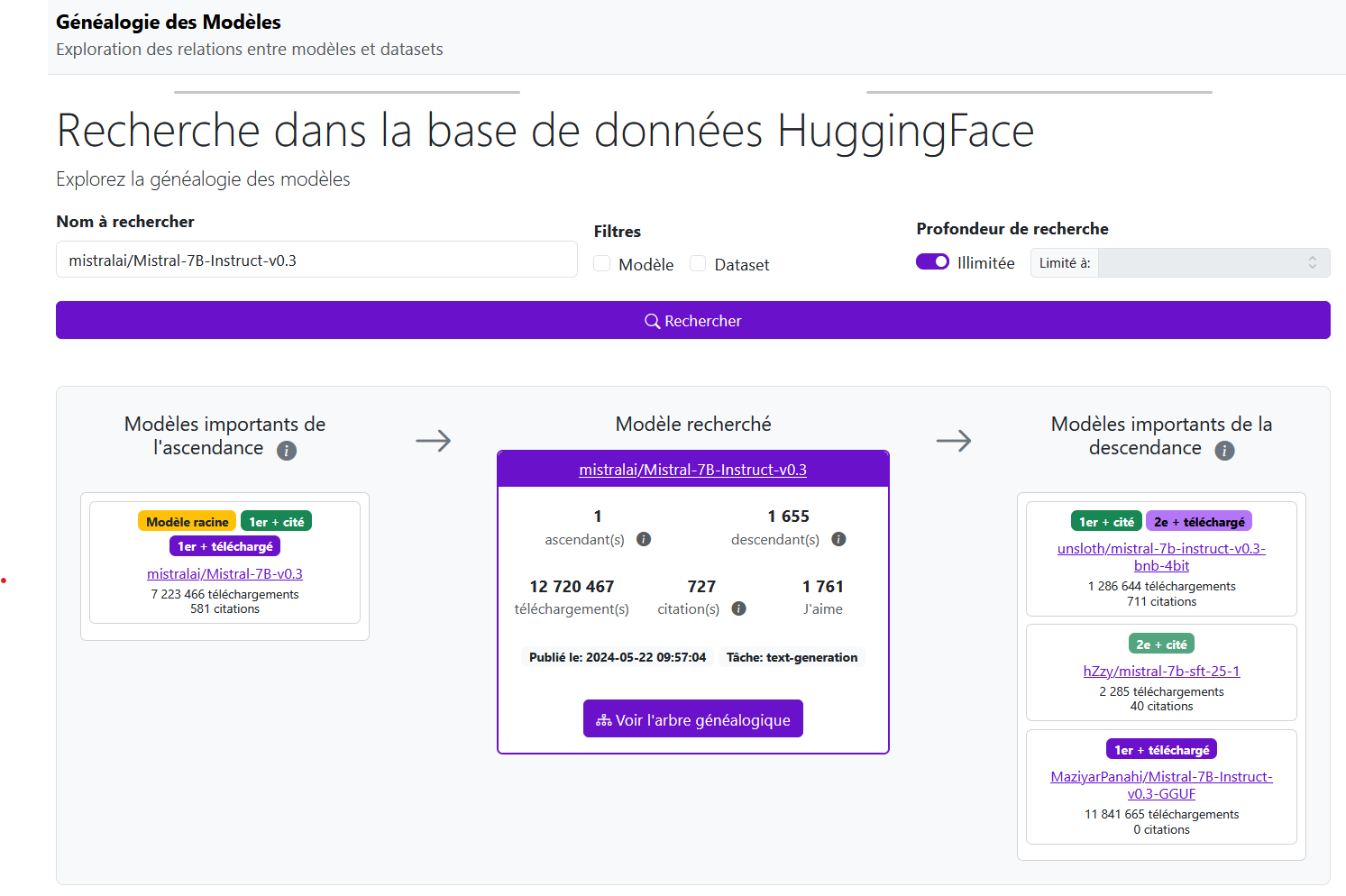
Figure 4 : Outil de visualisation de généalogie de modèles
Après avoir exploré les résultats, Alice veut s’avoir ce qu’elle peut faire pour demander aux responsables l’accès à ses données, ou bien même la suppression ou la rectification de ses données. Pour cela, nous avons imaginé une fonctionnalité d’envoi automatisé d’une requête à tous les modèles suspectés.
Cela permettrait d’envoyer automatiquement une requête rédigée par Alice à plusieurs modèles soupçonnés de contenir ses données, afin d’observer leurs réponses. Grâce à cela, l’utilisatrice pourrait trier les réponses pour identifier les modèles qui régurgitent ses données personnelles.
Dans la continuité de la démarche d’Alice pour exercer ses droits, un formulaire pourrait lui permettre de contacter automatiquement les auteurs de modèles identifiés comme potentiellement problématiques.
Cette fonctionnalité, comme la précédente, reste purement exploratoire et hypothétique, car la plateforme ne fournit pas obligatoirement de point de contact publique pour les auteurs de modèles. Il faudrait donc, pour que cette fonctionnalité devienne opérationnelle, qu’une évolution de la plateforme, permette une meilleure identification des responsables de publication des modèles.
L’outil propose aussi un mode « expert » qui s’adresse aux chercheurs voulant analyser les graphes de la composante connexe de certains modèles, par exemple. Cela leur permettrait d’extraire les graphes sous format HTML.
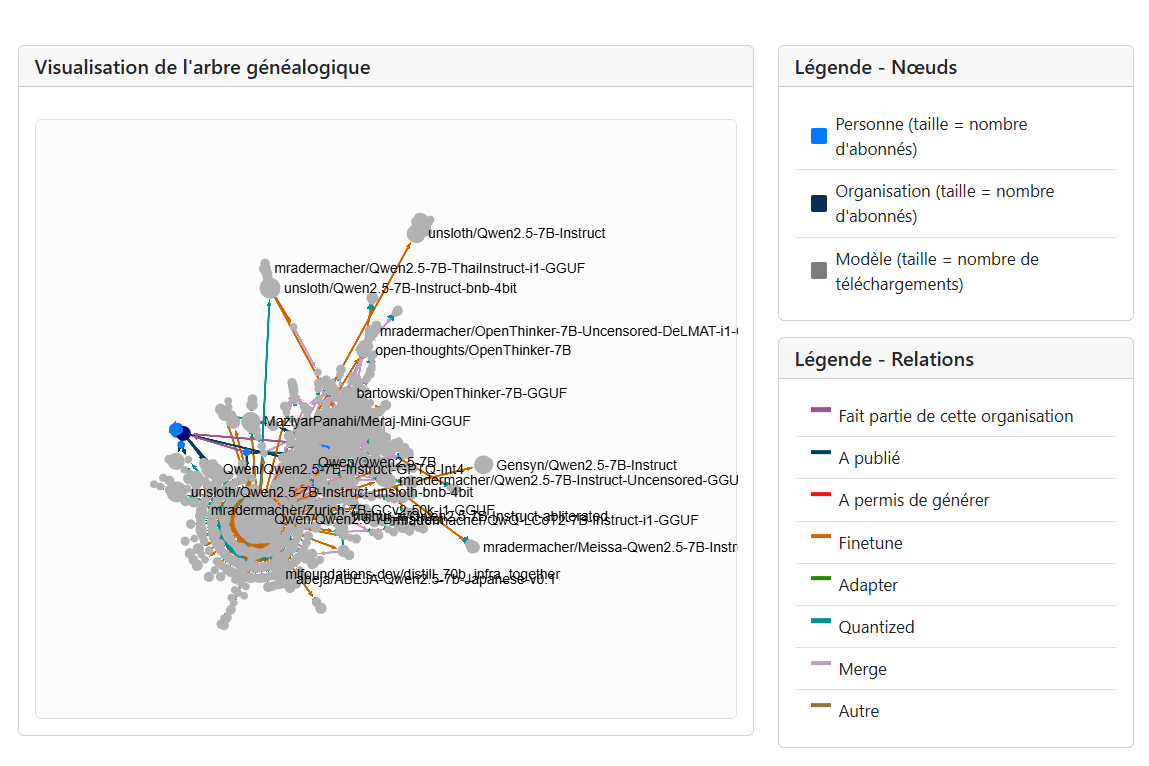
Figure 5 : Graphe de la composante connexe de Qwen2.5-7B-Instruct
Illustration générée par Gemini


