
Penser les données : les architectes du big data (Le travail des données 2/3)
Rédigé par Camille GIRARD-CHANUDET
-
08 décembre 2020« Data scientists », « Data architects » voire « Data alchemists »… Nombreuses sont les professions qui participent à la conception et à l’analyse des architectures de données. Derrière ces intitulés se trouvent des individus dont les choix contribuent à façonner le visage des services connectés. Prendre en compte la dimension sociale de la fabrique des données permet de se donner les moyens de questionner à la fois leur forme, et les usages qui en sont faits.

Loin d’être le reflet neutre et objectif de la réalité, les données sont le résultat de processus complexes de captation, de cadrage et d’enregistrement d’éléments divers sous des formes standardisées et quantifiables. Ces opérations impliquent toujours des choix (de variables à prendre en compte, d’échelles sur lesquelles les quantifier, de seuils, de hiérarchisation…) qui conditionnent la forme finale des données et, de ce fait, celle des calculs qui pourront être réalisés à partir d’elles – ce dont nous parlions dans le premier billet de cette série.
Ainsi, comme l’explique le sociologue Jérôme Denis dans son ouvrage Le travail invisible des données, « les données ne sont jamais désincarnées et n'existent pas à l'état ‘pur'. Elles sont toujours affaire de mélanges, de bricolages, d'accommodements, d'agencements hybrides. Elles sont l'objet et le résultat d'un travail ». Les choix impliqués par ce travail sont faits - consciemment ou non - par de nombreux acteurs, et en particulier par des professionnels et professionnelles dont le façonnage des données constitue le cœur de métier. Ils et elles conçoivent la forme que prendront les données et les bases dans lesquelles elles seront réunies en fonction des objectifs qui leur sont assignés, avant que des petites mains, beaucoup moins visibles (et dont nous parlons dans le billet suivant de cette série) se chargent de la construction effective des données.
Pouvoir des choix de structuration des données : l’exemple des genres musicaux sur Spotify
La façon dont les données sont construites impacte très largement les utilisations qui peuvent en être faites par les outils (en particulier algorithmiques) qui les traiteront ensuite. Les objets informationnels que sont les données sont des représentations schématiques, qui grossissent l’importance de certaines variables et en laissent de nombreuses autres de côté ; ils contribuent ainsi à la structuration de systèmes de représentation spécifiques.
Le processus de catégorisation des musiques sur Spotify permet d’illustrer cette dynamique. Si l’histoire de la classification musicale par genre est bien sûr ancienne, et en partie reprise par la plateforme qui n’oublie pas complètement le « rock » ou le « jazz », celle-ci se targue également de faire émerger les « genres musicaux de demain ». L’importance du catalogue musical de Spotify (plus de 50 millions de titres) lui permet en effet de conduire des analyses statistiques sur son fond et créer, sur la base de certains partis-pris, des labellisation inédites.
Le choix de variables particulières pour décrire les titres du fond musical de la plateforme oriente ces nouvelles catégorisations. Celui-ci inclut de façon notable diverses caractéristiques liées à des états émotionnels, également appelées « attributs psychoacoustiques », comme l’énergie, la « dançabilité », la « couleur émotionnelle »... Une telle labellisation conduit Spotify à construire un référentiel musical basé davantage sur les effets sensoriels supposés des titres que sur leurs caractéristiques structurelles. La plateforme suit en cela le parti-pris de la start-up d’ « intelligence musicale » EchoNest, dont elle a fait l’acquisition en 2014, qui affirmait à l’époque vouloir développer une catégorisation dynamique des musiques en fonction des mots « couramment utilisés pour les décrire », car « chercher du ‘rock’ [serait] à peine plus efficace que de demander à écouter des ‘chansons qui sont de la musique’ ».
Ainsi, Spotify voit aujourd’hui cohabiter deux types de catégorisation musicale, intrinsèquement liés aux critères employés pour les qualifier : l’un correspond aux genres « traditionnels » de musique et est basé sur leurs caractéristiques structurelles (type de rythme, tempo…), l’autre est orienté vers des états émotionnels ou des activités spécifiques supposément liés à leur écoute. C’est ce qui apparaît sur la capture d’écran suivante de la page « découverte » de l’interface de Spotify, voyant se mélanger d’un côté le hip-hop, le rock et l’électro, et de l’autre la musique « chill », sport ou encore estivale.
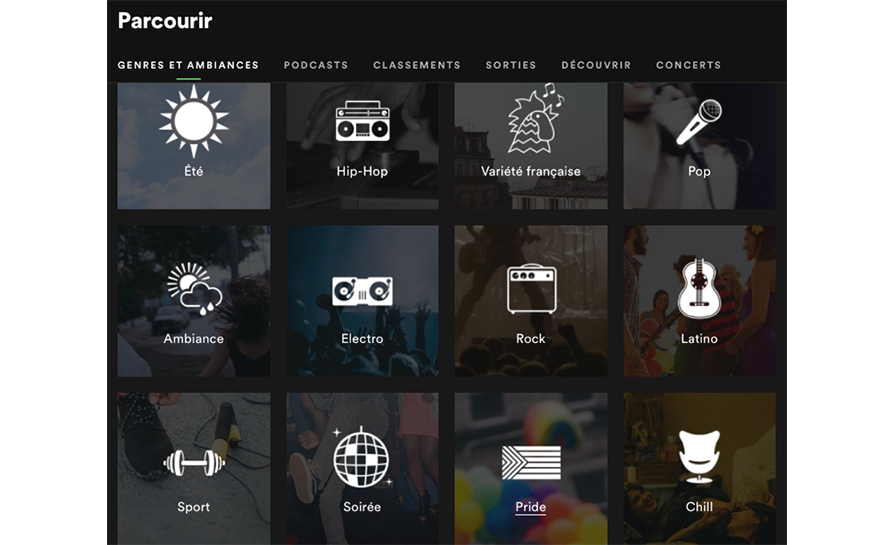
Ce glissement vers une typologisation émotionnelle de la musique peut être compris, suivant l’analyse des auteurs et autrices de Spotify Teardown (première étude de grande ampleur menée sur le fonctionnement de la plateforme), comme s’inscrivant dans « un mouvement de grande ampleur vers une approche utilitariste de la musique, dans laquelle la musique est de plus en plus consommée en lien avec un contexte particulier ou en appui de certaines activités (plutôt que dans le cadre d’une expérience esthétique ou d’un travail de construction identitaire, par exemple) ».
Il est en tout cas révélateur de l’importance des choix réalisés par les « architectes des données » de la plateforme dans la construction de la réalité qui prend forme sur son interface. La décision, contraire aux standards classiques de musicologie, d’inclure des variables émotionnelles dans la catégorisation musicale, s’accompagne d’une bascule dans la façon dont l’écoute musicale est envisagée. Si on choisissait certainement déjà au temps des cassettes audio d’écouter des titres différents en fonction du moment de la journée et de ses occupations, la généralisation par Spotify des playlists orientées vers des contextes et des humeurs particulières (« à écouter à la maison », « motivation pour le sport », « matin »…) normalise ces catégories, et oriente de ce fait à grande échelle les pratiques d’écoute des utilisateurs et utilisatrices. La forme des données, pensée par leurs concepteurs et conceptrices, conditionne leurs usages.
Catégorisation musicale et modèle économique sur Spotify
Cette catégorisation émotionnelle et contextuelle des titres musicaux proposés par Spotify est également étroitement liée au modèle économique développé par la plateforme.
En effet, croisées avec les données individuelles d’écoute sur l’interface, les caractéristiques émotionnelles des titres permettent la construction de profils personnels d’utilisation, qui alimentent les techniques marketing ciblé émotionnellement et contextuellement mises en œuvre sur l’interface. Le « Spotify Ad Studio » propose ainsi à ses annonceurs de cibler leurs clients et clientes potentiels en fonction des activités que celles et ceux-ci sont supposés être train d’effectuer, au vu des titres et playlists écoutées : en écoutant une playlist associée au voyage, on se verra ainsi plus probablement proposer des publicités de « vols et hôtels peu chers » qu’en choisissant des titres calmes liés par la plateforme à des activités de relaxation ou de lecture.
Le ciblage contextuel et émotionnel des utilisations de la plateforme impacte positivement les revenus que Spotify tire de ses activités publicitaires : en effet plus la granularité des ciblages est grande, plus le prix dont les annonceurs doivent s’acquitter est élevé (la différence entre une publicité générale et un ciblage spécifique en termes de profil et de contexte d’écoute varie du simple au double, selon certains observateurs).
Le choix d’« émotionalisation » et de contextualisation des données musicales par Spotify pose ainsi question en termes de profilage émotionnel des utilisateurs et utilisatrices de la plateforme. Ce mécanisme soulève en particulier la question du consentement des streamers et streameuses à de telles pratiques publicitaires, condition nécessaire à leur légalité posée par le RGPD. Les membres de la plateforme doivent en effet d’une part être informés de recueil d’informations de ce type les concernant, et d’autre part pouvoir refuser un tel ciblage personnalisé. Bien que l’information concernant ces pratiques soit affichée sur l’interface de la plateforme, le fait que la publicité puisse se confondre avec le produit (dans le cas de musiques ou de playlists sponsorisées et émotionnellement personnalisées par exemple) peut amener à questionner la possibilité même d’un tel refus.
Le travail de structuration des données : une activité ancienne
La structuration des données musicales effectuée par Spotify n’est pas une activité nouvelle : la classification des musiques par type existait déjà depuis longtemps au moment de la naissance de la plateforme (au moins depuis le XIXème siècle, date de naissance de la musicologie). La constitution de ce qui s’apparente à bases de données musicales structurées et organisées était au fondement de nombreuses pratiques musicales bien avant l’arrivée du streaming en ligne (répertoires des orchestres, bibliothèques musicales, programmes des bals ou encore, plus tard, compilations enregistrées sur des cassettes et organisation de playlists personnelles sur les premières versions d’Itunes…). De la même façon, et plus généralement, le travail de façonnage des architectures de données n’est pas apparu avec le numérique. Si la vague du « Big Data » de la première moitié des années 2010 a entrainé une forte visibilisation des professionnels de la donnée (« data scientists », « architectes de big data », « data scientists »…) qui apparaissent comme des spécificités du monde contemporain numérique, la standardisation d’informations est une activité ancienne.
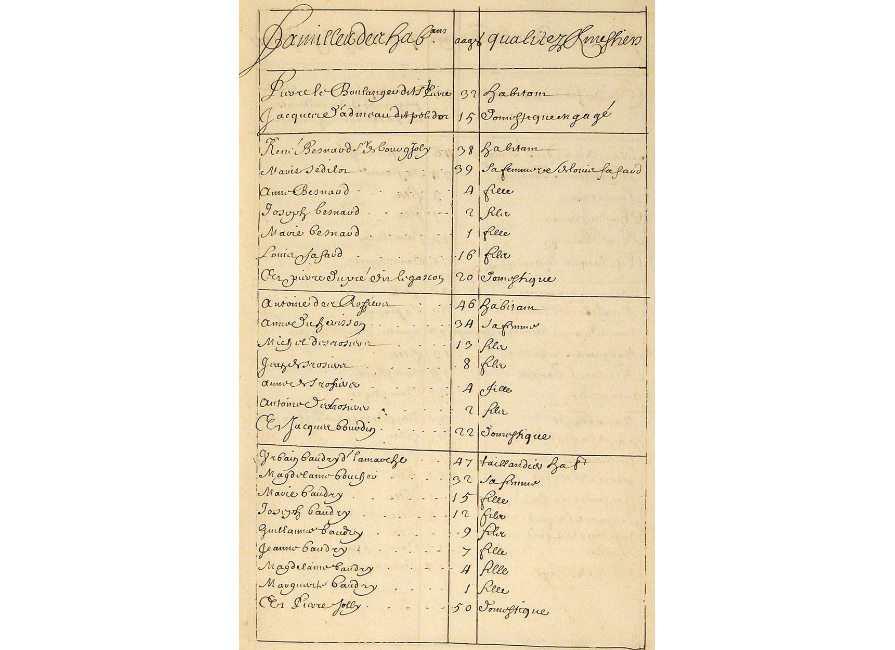
Comme l’explique le sociologue Alain Desrosières dans son Histoire de la Statistique, le travail de construction d’architectures de données s’est développé de façon importante avec l’essor des structures administratives étatiques, à partir du XVIème siècle. Il s’agissait alors pour les gouvernements de développer une meilleure connaissance de leurs populations, en décrivant leurs caractéristiques suivant des variables spécifiques (âge des individus, profession, situation géographique…). Les éléments ainsi réunis transformaient la population en données, reflets schématiques de l’existence des individus orientés par les usages administratifs qui présidaient à leur construction. Nul besoin d’ordinateurs, d’algorithmes et de data centers pour stocker et traiter les larges bases de données issues des premiers recensements, qui étaient construites entièrement à la main et conservées sur papier.

Des architectures par la structure aux architectures par les traces : l’effet Big Data
Le développement du numérique a fait connaître un changement d’échelle majeur au travail de construction des données. L’augmentation des capacités de stockage, et la mise en place d’outils de traitement automatique des informations, permet la constitution de bases de données de tailles inégalées. Celles-ci, originellement cantonnées aux domaines limités de l’administration étatique – seule instance disposant alors des moyens de collecter des informations à grande échelle –, couvrent aujourd’hui un immense spectre de domaines. Internet, en particulier, permet tant à des organisations publiques qu’à des structures privées de classifier les individus, leurs comportements et les objets avec lesquels ils interagissent sur la base des activités observées sur les interfaces en ligne.
Ce changement d’échelle dans la production de données a induit des glissements importants dans les modalités d’organisation du travail de construction des données. A ses origines, la statistique (en particulier étatique) reposait sur des catégorisations précisément définies au terme de longues controverses politiques et scientifiques (qu’est-ce qui constitue une « population », une « région », une « profession »…). Les données étaient ainsi construites « par le haut », dans une démarche déductive classant les éléments particuliers dans des cases conceptuelles établies en amont.
Si le développement de l’internet collaboratif a permis, avec la folksonomie (un « système de classification collaborative décentralisée spontanée, basé sur une indexation effectuée par des non-spécialistes » popularisé au début des années 2000 par des services comme Delic.io.us), d’infléchir cette méthode descendante de classification, la prolifération des données permise par le numérique a introduit la possibilité d’un renversement de ce processus. S’appuyant sur la multitude informationnelle, les architectes des données peuvent voir apparaître les récurrences structurant d’immenses jeux de données catégorisés de façon très vague, en limitant largement le travail de conceptualisation réalisé en amont. Cette méthode inductive permet de faire émerger automatiquement de la masse de données des connexions particulières (par exemple une fraction d’utilisateurs et utilisatrices de Spotify écoutant régulièrement de la musique italienne autour de l’heure du repas) aboutissant à la construction de nouvelles catégories (les utilisateurs et utilisatrices aimant la cuisine italienne) – pour un exemple très imagé, voir Dataclysm, le livre du fondateur du site de rencontres OkCupid sur l’analyse statistique inductive des données de ses membres.
Loin de se substituer entièrement à la méthode inductive, cette méthode de catégorisation des données par les traces se combine avec la conceptualisation en amont pour permettre le traitement de grands ensembles informationnels. Elle ne rend pas moins important le travail humain de conception des architectures de données. En effet, si certaines catégories émergent au fil du traitement, c’est parce que d’autres, entre lesquelles des liens sont tissés, ont été établies en amont. Toutes ne sont par ailleurs pas retenues dans la construction des données : la forme des données est toujours le résultat d’un choix.
La construction des bases de données et la définition des éléments qui ont vocation à y prendre place sont ainsi le fruit d’un important travail de cadrage humain. Résultant de choix techniques, stratégiques et conceptuels, autant que d’automatismes et de prédispositions sociales et professionnelles, les orientations données aux architectures de données conditionnent en grande partie les usages qui peuvent en être faits – notamment en termes de service rendu dans le cas des plateformes numériques.
Prendre conscience de ces processus est essentiel afin de se donner les moyens, en tant qu’internaute, de questionner et de comprendre la façon dont nos données personnelles sont construites et la forme que prennent les services souvent personnalisés qui nous sont proposés. Il est également essentiel pour les acteurs contribuant à la construction des bases de données – qu’il s’agisse de structures privées ou publiques – de développer une expertise et un regard critique sur les façons dont ces structures informationnelles se conçoivent et s’utilisent (c’est notamment dans cette perspective qu’Etalab a mis en place un accompagnement des administrations publiques désireuses de travailler à partir des données qu’elles construisent ou obtiennent dans le cadre de leurs activités).
[série] Le travail des données
Illustration : pisauikan sur Pixabay


