
Des annonceurs aux utilisateurs : un cheminement algorithmique [2/3]
Rédigé par Alexis Leautier
-
17 juillet 2024Les systèmes de recommandations développés et utilisés par les réseaux sociaux et les moteurs de recherche visent en premier lieu à fournir du contenu et des publicités adaptés à l’utilisateur tout en servant les intérêts économiques des fournisseurs de service et des annonceurs publicitaires. Comme décrit dans la suite, le système de recommandation de contenu (ce qui alimente un flux sur un réseau social ou les réponses sur un moteur de recherche) constitue un premier composant technique, dont la compréhension permet de mieux cerner les risques liés aux systèmes de ciblage publicitaire.

Des systèmes de recommandation toujours plus intelligents
L’objectif sous-jacent à la recommandation de contenu est l’optimisation de « l’engagement » des utilisateurs, qu’il s’agisse du temps passé sur la plateforme, ou du nombre de mentions, de commentaires, de partage d’un contenu ou du nombre d’’achats effectués pour les plateformes de vente. Bien que leurs concepteurs soient rarement transparents sur la transposition technique de cet objectif dans le fonctionnement de ces systèmes, certains recensements, comme Campana & Delmastro, 2023, en proposent une classification également étudiée dans le cahier IP « Les données, muses et frontières de la création » :
- le filtrage collaboratif, où les interactions des utilisateurs avec les contenus sont utilisées pour leur recommander de nouveaux contenus. Ces algorithmes peuvent être :
- basés sur la mémoire : c’est-à-dire que l’historique des utilisateurs ayant interagi positivement avec un contenu sera utilisé pour effectuer une recommandation à un utilisateur dont l’historique est similaire,
- basés sur un modèle : c’est-à-dire qu’une phase de modélisation a lieu sur la base des interactions des utilisateurs, permettant de recommander de nouveaux contenus. Ce type d’algorithmes repose généralement sur la création d’une représentation mathématique des contenus (via un espace latent),
- le filtrage basé sur le contenu, où une description explicite du contenu est utilisée afin de le recommander à un utilisateur ayant indiqué son intérêt pour cette catégorie (explicitement, via un profil d’utilisateur, ou implicitement, via son historique).
A ces deux grandes catégories doivent être ajoutées certaines techniques pouvant exploiter le contexte (comme l’heure du jour, la géolocalisation, etc.), les choix de l’utilisateur (sur Facebook par exemple, c’est le rôle des boutons « show more » et « show less » associés aux publications), ou encore l’apprentissage actif (par renforcement par exemple, comme étudié par des chercheurs de Google). Clustering, réseaux de neurones, réseaux en graphes, etc. les algorithmes utilisés varient et peuvent se composer afin d’utiliser plusieurs des approches précédentes de manière hybride.
Ces algorithmes sont encore très utilisés aujourd’hui pour se connecter avec d’autres personnes et pour accéder à l’information en particulier devant la quasi infinité de contenus disponibles et dont la qualité est grandement variable. Le EU Internet Forum (un consortium supervisé par des députés européens et regroupant des membres privés, publics et de la société civile) s’est attaché à évaluer l’impact de l’amplification algorithmique des contenus Terroristes, Violents et Extrémistes (TVE) ainsi que des contenus limites (borderline en anglais). Les conclusions de cette étude ont été publiées fin 2023. Les contenus limites sont caractérisés par leur capacité à conduire à la radicalisation sans pour autant être illégaux (via la désinformation, les thèses conspirationnistes, ou en cherchant à manipuler les utilisateurs). L’étude conclue que l’interaction avec des contenus TVE ou limites contribue à leur amplification via les algorithmes de recommandation. Elle observe notamment :
- une amplification de 18% en un jour des contenus TVE
- une amplification de 65% en un jour pour les contenus limites,
- que 90% des contenus signalés aux plateformes étaient encore en ligne 8 semaines après le signalement.
Ces résultats peuvent varier selon les langues, les plateformes, et les catégories de contenus (terroristes, violent d’extrême droite ou gauche, etc.). Les contenus limites en français en particulier seraient particulièrement amplifiés, 8 fois plus de contenus étant recommandé 24h après des recherches visant spécifiquement ces contenus. De plus, lorsque les contenus limites sont effectivement retirés des plateforme (ce qui ne concerne qu’environ 10% des cas), cela peut avoir lieu plusieurs semaines après le signalement, comme le montre le schéma ci-dessous tiré de l’étude.
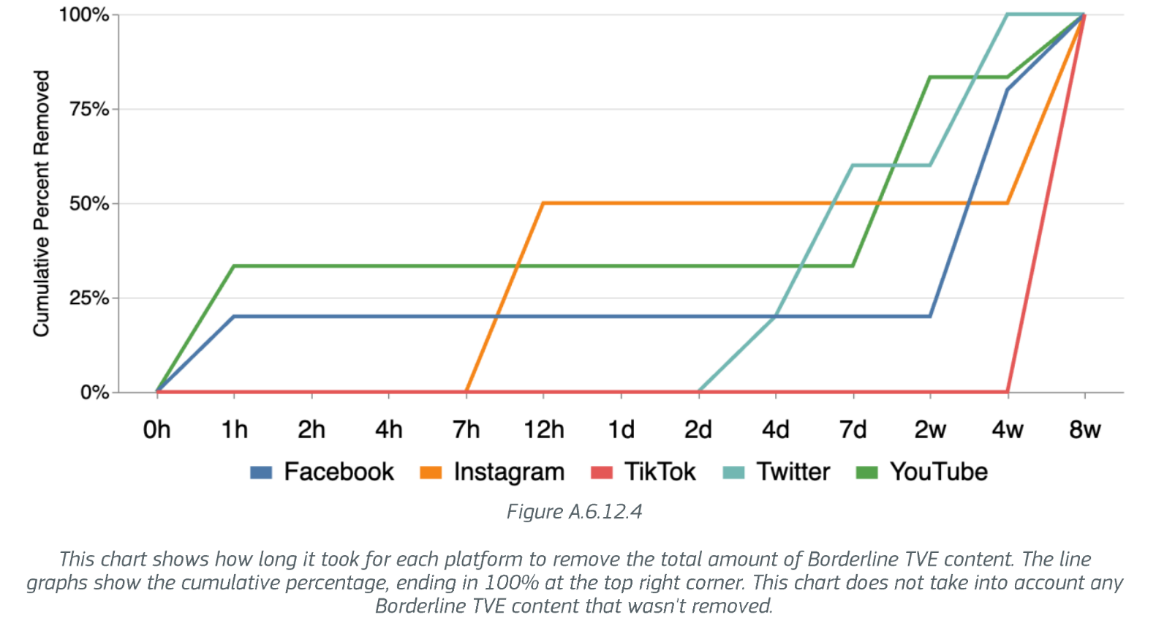
Même si cette étude possède ses limites (notamment dues à la difficulté d’accéder à des données à grande échelle tel que souligné dans le document), elle démontre assez clairement que les réseaux sociaux permettent l’amplification de contenus pouvant influencer un vote, que ce soit par la désinformation, en conduisant les utilisateurs à la radicalisation ou en les enfermant dans des bulles de filtre. Les constats précédent
s semblent pointer l’insuffisance des mesures prises par les plateformes pour contrer les effets de l’amplification algorithmique des contenus préjudiciables, comme le signalement des contenus par les utilisateurs. D’autres pistes, reposant parfois elle-même sur l’intelligence artificielle, sont explorées comme nous le verrons dans le troisième article de cette série. Le droit pourrait également ouvrir la porte à davantage de transparence et de contrôle par les utilisateurs sur les contenus qui leur sont recommandés.
Quelles recommandations pour les systèmes de recommandation ?
Les lignes directrices pour les très grandes plateformes et moteurs de recherche prévoient des mesures d’atténuation des risques incluant :
- La possibilité, via une option à la main de l’utilisateur de choisir et de maîtriser son flux d’information,
- La réduction de la désinformation, par la limitation de l’amplification de ces contenus,
- La modification des algorithmes lorsqu’ils font peser des risques sur les processus électoraux,
- La transparence sur la conception et le fonctionnement des systèmes de recommandation, et la coopération pour leur audit.
Ces recommandations rejoignent des obligations prévues par le Règlement sur les services numériques (RSN) qui impose aux fournisseurs de service d’indiquer les principaux paramètres utilisés dans les systèmes de recommandation dans les conditions d’utilisation, ainsi que les options dont disposent les utilisateurs pour les modifier ou les influencer. Ce texte prévoit également qu’au moins une option qui ne reposerait pas sur du profilage leur soit proposée. Enfin, le système de gestion des risques (dont l’impact sur les processus électoraux) à mettre en place par les plateformes doit inclure une évaluation de l’influence des systèmes de recommandation.
Comme évoqué dans l’article précédent, le règlement sur l’IA (RIA) prévoit des obligations pour les systèmes selon leur niveau de risque. Néanmoins, les algorithmes de recommandation ne semblent pas entrer dans les catégories à haut risque. Des clarifications à ce sujet pourraient être apportées par la Commission Européenne.
Enfin, le RGPD prévoit que les risques de discrimination soient pris en compte dans l’analyse d’impact sur la protection des données (AIPD) liée au traitement de données personnelles mis en œuvre par un système de recommandation. Ces risques doivent ensuite être réduits à un niveau acceptable, sans quoi l’AIPD doit être envoyée à l’autorité de protection des données. Puisque l’opinion politique est l’un des critères sur lesquels une discrimination peut être caractérisée selon le Défenseur des Droits, faire entrer une personne dans une bulle de filtre sur la base de ses interactions passée avec des contenus à caractère politique pourrait être considéré comme une discrimination.. De plus, le RGPD prévoit des dispositions spécifiques au profilage prévues à son article 22, lorsque celui-ci possède un impact significatif sur les personnes. Cet article impose des conditions pour qu’une prise de décision puisse être fondée exclusivement sur le résultat donné par un système automatisé, comme une IA. Toutefois, les notions correspondantes à la prise de décision purement automatisée, ou à ce qui constitue un impact significatif restent à interpréter puisque la jurisprudence portant sur cet article est encore mince : à la connaissance de l’auteur, aucun jugement n’a considéré qu’un algorithme de recommandation remplissait ce critère jusqu’à aujourd’hui. Le G29 (le groupe qui réunissait les autorités de protection des données européennes jusqu’en 2018, aujourd’hui devenu l’EDPB) ne l’exclue pas en théorie dans ses lignes directrices sur le sujet, selon les caractéristiques particulières de la situation, y compris en ce qui concerne :
- le caractère intrusif du processus de profilage, notamment le suivi des personnes sur différents sites web, appareils et services ;
- les attentes et les souhaits des personnes concernées ;
- la façon dont l’annonce est diffusée ; ou
- le recours aux vulnérabilités connues des personnes concernées visées.
Les dispositions prises en amont visent ainsi principalement trois objectifs : la reprise de contrôle par les utilisateurs, la transparence, ainsi que l’analyse de risque. Les techniques permettant de répondre à ces enjeux sont de divers ordres :
- l’inclusion des choix de l’utilisateur dans le système de recommandation, en tenant compte de ses retours sur les contenus proposés (pour tenir compte de leurs goûts, et des signalements de contenus inappropriés), de certains intérêts qu’il indiquerait, ou encore en lui proposant de choisir entre plusieurs algorithmes de recommandations,
- la prise en compte de critères supplémentaires dans l’algorithme tels que la diversité des contenus, ou leur sérendipité (c’est-à-dire à quel point un nouveau contenu pourrait surprendre positivement l’utilisateur),
- l’identification des contenus illégaux, préjudiciables ou limites, ainsi que des tentatives d’influence (voir l’article suivant concernant ces techniques et leurs limitations),
- la transparence, notamment sur le fonctionnement des algorithmes, ainsi que sur les contenus recommandés afin de permettre l’évaluation par des tiers.
Ces nouvelles mesures ne peuvent conduire que dans la bonne direction, mais les premières évaluations du système de gestion des risques prévu par le RSN incitent à la prudence. Dans une publication étudiant l’application de ce système aux campagnes de désinformation russes sur les plateformes, la Commission Européenne dresse un bilan très négatif des mesures prises. En effet, malgré le blocage des comptes de représentants politiques russes et la modération des contenus partagés sur les réseaux, la désinformation russe liée à la guerre en Ukraine semble toujours atteindre un public en Europe en partie à cause des systèmes de recommandation. Grâce à un indicateur appelé « Non-Follower Engagement », il a pu être montré que si la portée des publications des influenceurs et médias russes bloqués sur les réseaux sociaux avait diminué, celle des publication des employés du Kremlin et des représentants officiels (comme les ambassades) quant à elle, avait augmenté de manière à compenser la première baisse.
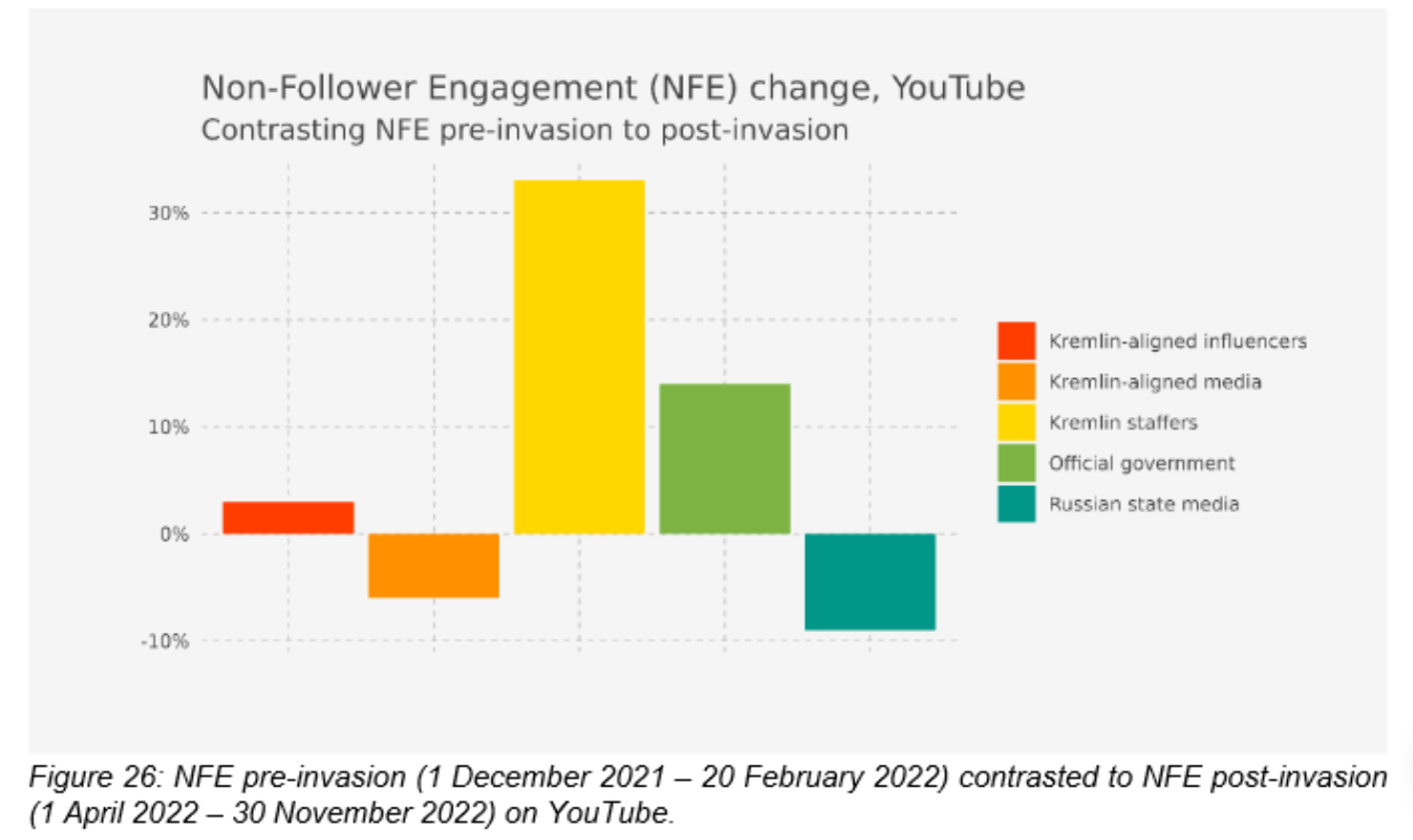
Source : Commission Européenne, Application of the risk management framework to Russian disinformation campaigns
D’après l’étude, ceci pourrait être expliqué d’une part par un déport des utilisateurs vers les comptes toujours autorisés sur les plateformes, leur donnant davantage de visibilité dans les recommandations. D’autre part, les utilisateurs pourraient être conduits vers ces comptes par d’autres biais, par exemple par les moteurs de recherche, ou par des boucles de diffusion plus restreintes comme des groupes de discussion ou forums. Il apparaît ainsi que des mécanismes sous-jacents, tels que ces boucles de rétroaction, existent et échappent encore à la modération mise en œuvre par les plateformes, en partie à cause d’un manque de contrôle sur les algorithmes de recommandation. Ce constat semble d’autant plus préoccupant en raison de la maîtrise de ces mécanismes acquise par certains acteurs. En effet, une étude récente du chercheur David Chavalarias réunit une liste d’indices conduisant à penser que les acteurs russes en particulier utilisent des techniques comme l’astroturfing (amplification artificielle d’une idée par la création d’une foule factice la propageant) ou les publicités ciblées dans le cadre d’une stratégie d’ingérence élaborée sur le long terme.
Recommandation et ciblage publicitaire : du pareil au même ?
D’après une analyse conduite sur le cas particulier de Facebook par Chouaki et al., 2022 , les annonceurs ont le choix entre deux stratégies pour cibler leur audience :
- le ciblage à la main de l’annonceur : où il choisit lui-même les caractéristiques des groupes de personnes qu’il souhaite toucher. Ces caractéristiques peuvent reposer sur des informations démographiques déclarées par l’utilisateur (comme son âge, son sexe, son lieu de résidence, etc.), sur des « segments » inférés par la plateforme à partir des interactions des utilisateurs sur ses produits et cherchant à décrire ses intérêts (comme un intérêt pour le cinéma, pour un sport ou un genre de musique – les segments liés à un compte Facebook peuvent être trouvés dans la rubrique « ad topics »),
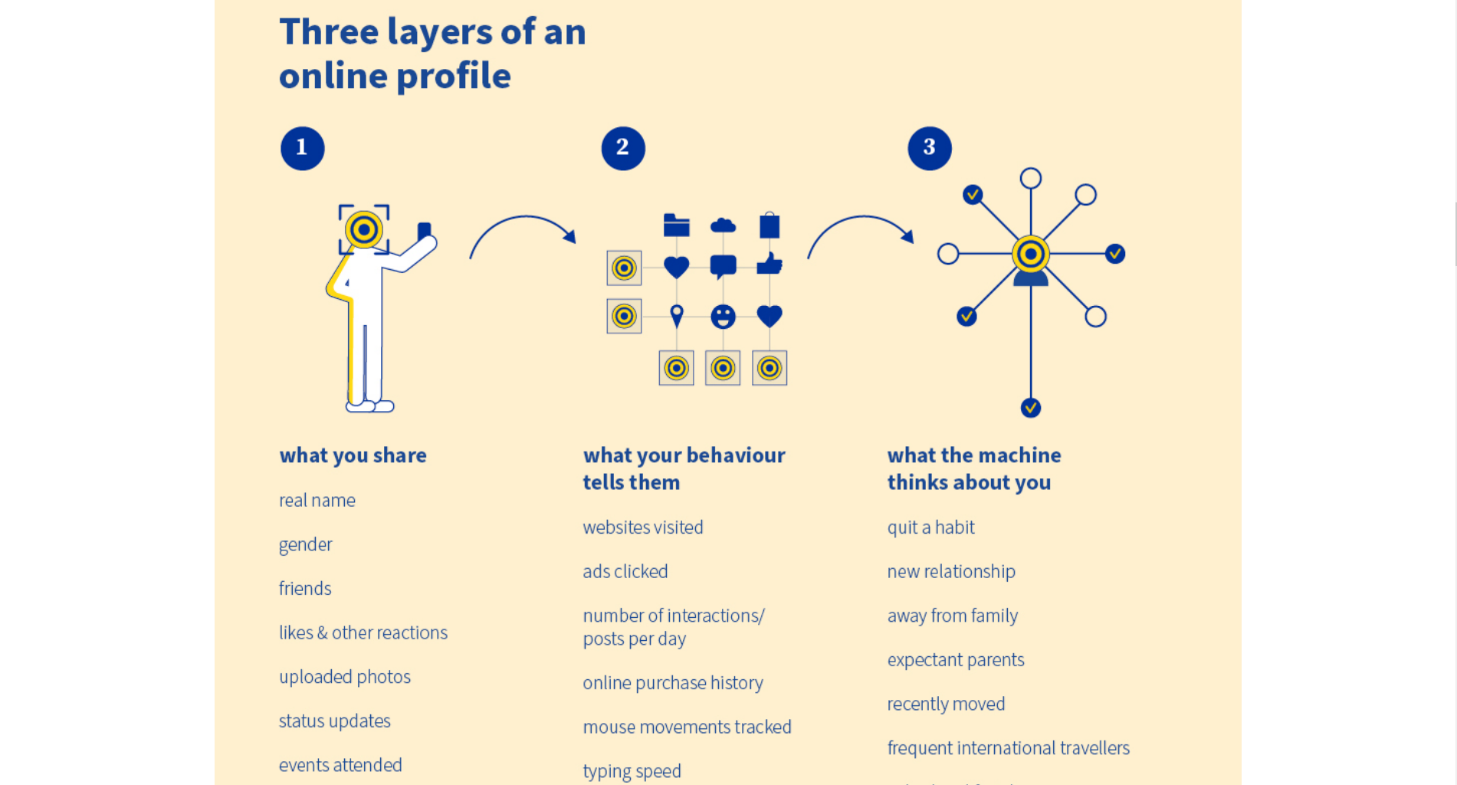
Infographie décrivant le fonctionnement du profilage en ligne (source : Conseil de l’UE)
Ces deux stratégies de ciblage semblent assez différentes, la première laissant une marge de manœuvre importante aux choix de l’annonceur, et la seconde reposant sur un algorithme (avec des limitations similaires à celles des systèmes de recommandation). Cependant, comme indiqué sur une page d’aide de Meta dédiée aux annonceurs, lorsqu’un ciblage « manuel » est choisi, le ciblage peut toujours avoir lieu sur la base du résultat algorithmique lorsque cela peut « améliorer les performances ». Ce ciblage est mis en œuvre via un système d’enchères tenant compte de trois critères : le montant de l’enchère, le taux d’interactions estimé et la qualité de la publicité.
Une étude conduite en 2019 (donc sur la base d’un dispositif de ciblage publicitaire qui a pu évoluer depuis) par Ali et al., 2019 a démontré qu’en ce qui concerne le ciblage automatique des publicités politiques aux Etats-Unis, le système utilisé par Facebook avait pour effet :
- de délivrer préférentiellement les publicités politiques aux utilisateurs dont les opinions sont proches de celles portées par la publicité,
- de limiter la possibilité (ou d’augmenter le coût) pour les annonceurs d’atteindre une audience qui ne partagerait pas ses opinions politiques.
Ces constats auraient pour effet d’amplifier les bulles de filtre dans lesquelles les utilisateurs se retrouvent bloqués, et ainsi d’amplifier la polarisation politique. Par ailleurs, le coût lié au ciblage publicitaire d’une part, et le surcoût lié à l’acquisition d’une audience d’un autre bord politique d’autre part, pourraient avoir pour double effet de diminuer la visibilité des partis les moins bien financés, et d’augmenter la capacité des plus gros partis à convertir des électeurs. Ces effets ont sans aucun doute des effets sur les opinions politiques majoritaires, qu’il reste à évaluer.
Une infographie du Conseil de l’UE indique que 43 millions d’euros avaient été dépensés pour la publicité politique en ligne au cours des 20 semaines précédant l’élection européenne de 2019. Ce montant est toutefois très faible en comparaison des dépenses annuelles au niveau mondial : 522.5 milliards de dollars en 2021, et il devrait encore augmenter pour atteindre 836 milliards de dollars en 2026. En Europe, la France est l’un des marchés les moins importants en dépenses – 321k€ entre mars 2019 et janvier 2022 – en comparaison d’autres pays comme l’Allemagne ou la Hongrie – respectivement 5,35M€ et 2.96M€ sur la même période. Cela peut s’expliquer d’une part par l’interdiction prévue par le code électoral d’utiliser tout procédé de publicité commerciale à des fins de propagande électorale 6 mois avant un scrutin. Bien que la présence ou non d’échéances électorales sur la période dans les pays comparés, ainsi que la crise du Covid aient nécessairement influencé ces montants, la différence d’ordre de grandeur est tout de même parlante. Puisque les réseaux sociaux sont principalement financés par les espaces de publicité (politique ou non) qu’ils monétisent, ces sommes sont représentatives d’importants enjeux pour les fournisseurs. Elles démontrent également l’importance de l’espace numérique pour la communication politique des partis.
Réglementer les publicités politiques : un enjeu de transparence
Etant ainsi admis que ce vecteur est un moyen d’information important pour les citoyens, les textes portant sur la publicité politique ne visent pas à l’interdire, mais à lui fixer un cadre.
Le règlement sur la publicité à caractère politique, tout d’abord, introduit des critères permettant de déterminer les contenus relevant de la publicité politique (tenant compte du contenu, du parraineur, du langage, ou encore du contexte de publication). Ce texte interdit le traitement de données personnelles et le ciblage lorsque les données n’ont pas été collectées auprès de la personne concernée (notamment par le moissonnage sur le Web), lorsque la personne n’a pas donné son consentement, lorsque le profilage est basé sur des données sensibles (visées à l’article 9 du RGPD), ou encore lorsque la personne concernée ne sera pas en âge de voter avant encore un an. Il prévoit également plusieurs mesures de transparence :
- sur les publicités politiques, que les éditeurs devront obligatoirement marquer, et indiquer aux utilisateurs notamment l’identité du parraineur, et l’utilisation éventuelle de techniques de ciblage ;
- la tenue par la Commission d’un répertoire des publicités politiques accessible au public ;
- sur les techniques de ciblage et de diffusion des publicités politiques, les éditeurs devront adopter et publier des règles internes sur leur utilisation, transmettre des informations sur leur logique et leurs principaux paramètres. Il devrait notamment être précisé si un système d'intelligence artificielle est utilisé, les groupes de destinataires ciblés, ou encore les paramètres utilisés pour le ciblage (dont les catégories de données personnelles utilisées).
De plus, les éditeurs devront préparer une évaluation interne annuelle des risques que l'utilisation des techniques de ciblage ou de diffusion représentent pour les libertés et les droits fondamentaux, et en publier les résultats.
Ces dispositions seront applicables à partir de l’automne 2025 dans leur majorité. Elles viendront ainsi compléter les mesures prévues par le RSN. Ces dernières portent plus généralement sur tous types de publicités et prévoient que les fournisseurs de très grands moteurs de recherche et plateformes en ligne tiennent et publient un registre des publicités. Il devrait notamment y être indiqué l’identité des personnes ayant financé et demandé la diffusion (lorsqu’elles sont distinctes), si certains groupes de destinataires étaient ciblés lors de la diffusion, et les principaux paramètres utilisés à cette fin (comme les paramètres utilisés pour exclure certains groupes particuliers). Le texte prévoit également des mesures d’audit par les Etats membres (via des coordinateurs nationaux : l’Arcom en France) et par des chercheurs agréés par un accès aux données nécessaires. Les coordinateurs nationaux pourront également demander la fourniture d’informations sur le fonctionnement et les tests effectués sur les systèmes algorithmiques.
Toutefois, en dépit de ces avancées règlementaires importantes sur l’encadrement des publicités politiques, une difficulté importante persiste comme souligné par Oana Goga dans une interview donnée au Linc en 2021 : un nombre important de publicités politiques circuleraient sur Facebook sans être identifiées comme telles. Ainsi, la présence de ces contenus sur les réseaux et plateformes pourrait entraîner les conséquences discutées plus haut en termes de discriminations, de bulles de filtre et de désinformation, sans que les mesures sur la transparence, le ciblage et la qualité de l’information ne soient applicables. Des techniques et mesures existent pourtant pour identifier ces contenus comme décrit dans l’article suivant.
Illustration source : Pexels

