
BigScience : « Il faut promouvoir l’innovation ouverte et bienveillante pour mettre le respect de la vie privée au cœur de la recherche en IA »
Rédigé par Alexis Léautier
-
02 November 2022Les modèles de langage de grandes tailles (en anglais LLM pour large langage models) sont des constructions statistiques modélisant la distribution de séquences de mots dans de nombreuses langues. Ces dernières années ont vu leur importance grandir considérablement au point que de nouveaux modèles sont de plus en plus fréquemment édités, en particulier par les grands acteurs du numérique (GPT-3, BERT, Gopher, Megatron-Turing NLG, Chinchilla, PaLM, LaMDA, etc.). Toutefois de tels objets ne sont pas sans poser de questions, en particulier pour la protection des données. Le projet d’envergure internationale BigScience, vise à produire un modèle de langage géant librement accessible à la communauté scientifique et à s’attaquer à ces enjeux. Echanges avec l’équipe en charge de l’aspect éthique du projet : Yacine Jernite, Giada Pistilli, Mathilde Bras et Carlos Muñoz Ferrandis nous répondent collectivement.

[LINC] Il y a un peu plus d’un an était lancé le projet BigScience. Pouvez-vous rappeler succinctement son ambition, qui il rassemble et son état d’avancement ?
[BigScience] Le projet BigScience a développé le premier modèle de langage de grande taille ouvert et multilingue avec ses jeux de données d'entraînement respectifs. Avec la communauté BigScience, qui s'est créée en mai 2021 sous l'impulsion de la société Hugging Face, nous avons choisi une approche ouverte et collaborative. Nous rendons accessibles le processus de développement, l’utilisation du modèle, ses versions intermédiaires (les checkpoints), ainsi que tous les éléments complémentaires qui entourent le projet (e.g., logiciels open source, documentation, évaluation, articles académiques, licence, charte éthique, etc.).
C’est principalement grâce à la confiance des institutions françaises de recherche et technologie de pointe (IDRIS/CNRS et GENCI), qui nous ont donné l'accès à des ressources de calcul - le supercalculateur Jean Zay - que ce projet a été rendu possible. Le projet est le résultat d’un an de collaboration, réunions, expérimentations et discussions menés avec la participation de plus de 1000 chercheurs pluridisciplinaires à travers le monde (plus de 60 pays). Ce projet mène ainsi à la finalisation d’un modèle transformé de 176 milliards de paramètres (1B plus que GPT3 et le récent OPT de Meta). Le modèle, appelé BLOOM, a été mis à disposition de la communauté des chercheurs le 12 juillet 2022, et peut être essayé à cette adresse.
[LINC] En quoi ce modèle géant de 176 milliards de paramètres se différencie-t-il des nombreux modèles de langage constitués par ailleurs (GPT-3, BERT, Gopher, etc.) ?
[BigScience] Le modèle BLOOM (BigScience Large Open-science Open-access Multilingual) est le produit d’une entreprise de recherche exceptionnelle : la seule dans ce domaine à ce jour à profiter de contributions et de domaines d’expertise aussi divers et variés.
Cela a eu des conséquences à tous les niveaux du projet. Les données d'entraînement sont multilingues, choisies par des participants en fonction de leur connaissance propre des langues d'entraînement du modèle et de la diversité des sources et des variations géographiques de ces langues. La structure choisie pour le modèle correspond au produit de longues discussions entre plusieurs utilisateurs prospectifs et de très nombreuses expérimentations menées a priori par les nombreux participants des Groupes de Travail sur l’architecture. Le choix et la mise en œuvre des évaluations des performances et comportements du modèle (dont ses biais) reflètent aussi la grande diversité des participants, qui ont remis en question la prépondérance de l’Anglais et du contexte culturel nord-américain dans ces évaluations et développé leurs propres approches.
Du point de vue de la gouvernance de l’IA (aspect social, éthique et légal), BLOOM se différencie de ces autres modèles par plusieurs aspects : (i) le modèle est le résultat d’un processus de développement collaboratif ouvert à toutes les parties intéressées et favorisant l’interaction de disciplines scientifiques complémentaires ; (ii) les fondements éthiques du projets décrits dans notre charte éthique qui ont donné un sens à sa communauté et en particulier la valeur d’inclusion qui nous a poussés à développer nos artefacts par le prisme du multiculturalisme, multilinguisme et de la diversité ; (iii) l’investissement dans l’étude de la gouvernance par des Groupes de Travail dédiés, tant au sein du développement du projet que pour l'accès et utilisation du modèle ; (iv) la rédaction d’une licence ouverte et responsable qui cherche à motiver une utilisation à la fois ouverte et responsable du modèle, une pratique qui manque de nos jours et qui doit être développée davantage au sein de l’industrie, mais aussi des institutions publiques.
[LINC] Mener à bien un tel chantier pose de nombreuses questions scientifiques, d’ingénierie mais également relatives à la gouvernance des données puisque l’accès à d’énormes quantités de ressources textuelles est nécessaire, dont certaines peuvent être personnelles. Concernant les enjeux de vie privée, quels choix ont été fait dans le projet BigScience ?
[BigScience] L’un des avantages principaux de BigScience a été sa capacité à approcher chaque problème de plusieurs directions à la fois. En ce qui concerne le respect de la vie privée par exemple, si nous n’avons pas trouvé de solution unique et parfaite pour garantir l’absence totale de risque, nous avons cependant eu l’opportunité de prendre des décisions qui réduisent ces risques à plusieurs niveaux et dans plusieurs aspects du projet et qui bénéficient les unes des autres. Ces efforts comprennent par exemple (i) une analyse a priori des risques liés à diverses catégories de données personnelles, (ii) l’annotation manuelle de ces risques pour chaque source de donnée d'entraînement proposée par les participants , (iii) un modèle de gouvernance et de partage des données qui évite la dissémination excessive, (iv) un traitement des données avant l'entraînement du modèle qui enlève automatiquement certaines catégories de données personnelles, et (v) un modèle de partage de BLOOM comprenant des clauses d’utilisation qui interdisent de manière explicite les usages portant atteinte à la vie privée.
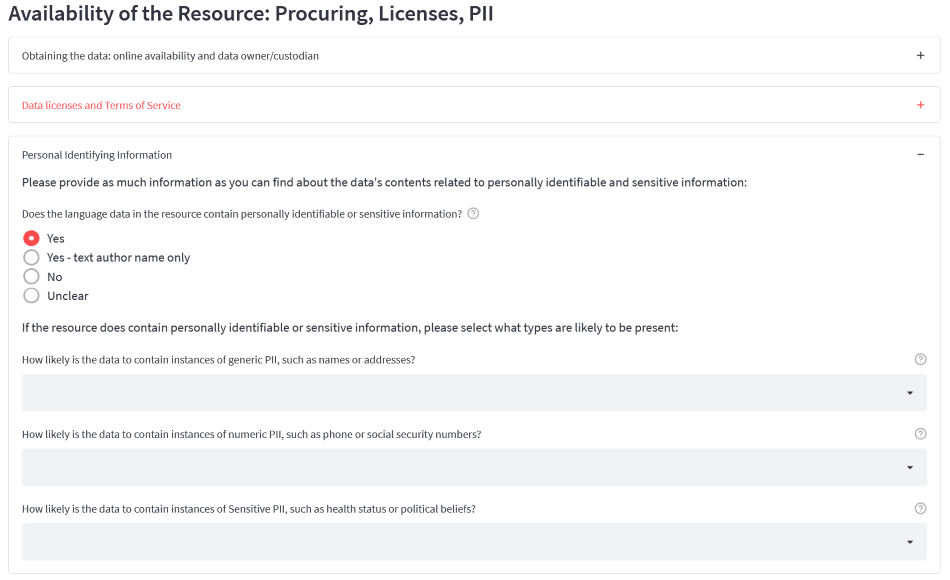
Figure 1 : Capture d'écran de l'outil proposé par BigScience pour l'annotation des sources de données par les contributeurs. Les contributeurs étaient également questionnés sur les types de données sensibles concernés (origine ethnique, opinion politique, orientation sexuelle, etc.).
Pour chaque source de données potentielles, nous avons demandé à nos participants d'évaluer les types de risques liés à plusieurs catégories de données personnelles [NDLR : la capture d’écran de ce procédé en figure 1 montre les informations demandées aux contributeurs]. En pratique, il était cependant trop difficile pour les participants de donner des informations utiles à ce niveau de granularité. Ainsi, bien que l’inclusion de données de langage issues de réseaux sociaux tels que Twitter, auraient pu exposer notre modèle à des variétés et des mécanismes de discours absent de nos autres jeux de données, les risques liés à la vie privée étaient trop importants pour les ajouter à notre corpus. Par ailleurs, concernant- l'accès et le traitement de données incluses dans le corpus, nous avons développé un Data Partnership Agreement au sein duquel nous proposons d’intégrer des clauses spécifiques pour le traitement et l’identification de données personnelles. Ces clauses visent à réguler les interaction entre les parties du contrat au sujet des données personnelles, en vue de créer des processus les plus diligents possibles.
[LINC] Ces dernières années, de nombreuses publications tel que (Wallace, et al., 2020) ont illustré les risques que les modèles de langage géants pouvaient faire peser sur la vie privée des personnes. Comment le projet BigScience se positionne-t-il par rapport à ces types d’attaques ?
[BigScience] En plus des risques liés à la dissémination des données que nous avons regroupées pour entraîner le modèle, nous nous devions en effet aussi considérer les risques liés à l’utilisation du modèle lui-même et à sa capacité à « fuiter » les données personnelles présentes dans son corpus d'entraînement. Pour cela, nous avons pris plusieurs mesures concrètes.
Tout d’abord, des travaux plus récents ont montré que le risque de mémorisation de données particulières est assez limité quand le modèle ne les voit qu’un nombre limité de fois durant l’entraînement (Carlini et al., 2022). Nous avons donc décidé de dédupliquer les données d’entraînement et de n’entraîner le modèle que pour une époque, c’est-à-dire une seule itération d’apprentissage. Ensuite, pour les données que nous utilisions issues du Common Crawl [NDLR : Common Crawl est une ONG dont l’objectif est de collecter certaines données sur le Web par moissonnage ou scraping, pour ensuite les partager en open data], qui posent à notre sens le plus de risques liés à la vie privée, nous avons remplacé les données personnelles que nous savions identifier (email, identifiants, etc…) par des tokens spéciaux (PI:EMAIL, PI:USER, etc…) avant de les exposer au modèle. Enfin, nous avons organisé un effort collaboratif de deux mois durant lequel des dizaines de participants ont annoté des données dans huit langues pour permettre de développer des outils de détection des données personnelles multilingues plus performants. Cela nous a permis de les enlever plus facilement des jeux de données d'entraînement des modèles de langue.
Au-delà des travaux menés en amont de l’entraînement de BLOOM, nous espérons aussi que la mise à disposition du modèle permettra à aux institutions de participer à la recherche sur ce sujet plus facilement et en ayant un accès complet aux systèmes étudiés. L’objectif in fine est qu’un plus grand nombre d’institutions participent à la recherche sur le sujet Nous sommes convaincus que la seule manière de développer des méthodes de protection de la vie privée adaptées à ces nouvelles technologies est d’opter pour une approche collaborative. Cela implique d’engager des échanges avec des institutions publiques et autorités expertes du sujet comme la CNIL. En effet nous partageons des objectifs communs : promouvoir l’innovation ouverte et bienveillante en IA et TAL [NDLR : traitement automatique de la langue, en anglais NLP, natural language processing], qui mette le respect de la vie privée au cœur de la recherche.
[LINC] L’ambition de BigScience est de favoriser la science ouverte et de mettre à disposition les outils développés dans le cadre du projet. Toutefois, on assiste depuis plusieurs années à une réflexion sur les risques de ces technologies – qui sont au cœur du projet de réglementation sur l’IA en cours d’adoption par l’UE – ainsi qu’une prise de conscience des chercheurs, ingénieurs et autres producteurs de ces ressources et connaissances. Que prévoit BigScience pour favoriser des pratiques responsables ?
[BigScience] Afin de répondre à des besoins intrinsèques du projet mais aussi aux contraintes légales de plus en plus explicites dans l'industrie de l'IA, BigScience a créé la licence RAIL (Responsible AI License). Les licences open source actuelles, telles quelles, ne prennent pas en compte les questions d'utilisation responsables des modèles d’IA. Et ce pour deux raisons principales :
- (i) la différence entre le modèle et le logiciel qui sont deux types d’artefacts différents avec des comportements différents, et donc porteurs de besoins de gouvernance et d'utilisation différentes ;
- (ii) la définition de free software, qui a influencé la définition de l’open source (principe 6). Cette définition est basée sur la “Freedom 0” qui défend l'idée que l'utilisateur du code peut faire ce qu’il veut avec, même si l’utilisateur est une personne malveillante. Dans le domaine de l'IA, on ne peut tout simplement pas se permettre cela. La communauté scientifique tout entière doit réagir pour éduquer à une utilisation tant ouverte que responsable des modèles, et cela va être possible grâce, en partie, à des licences RAIL et ouvertes.
Pour notre cas particulier, nous avons créé une licence spécifique pour BLOOM. Cette licence intègre une « clause d’utilisation responsable » qui impose des restrictions d'utilisation du modèle dans les contextes pouvant générer des risques ou dommages pour la société et les individus (risques portant sur les données personnelles inclus - Annex A(d)). De plus, cette clause d’utilisation responsable a été conçue pour avoir un effet viral, c'est-à-dire que toutes les versions dérivées de BLOOM, indépendamment de la licence choisie, sont obligées de l’inclure. Bien évidemment, cette licence est ouverte, puisqu'elle contient l’esprit des licences open source permissives telles que Apache 2.0, mais elle intègre également les préoccupations de la communauté BigScience quant au potentiel du modèle [NDLR : voir ici l’article et FAQ pour la licence RAIL ouverte].
[LINC] Une fois le modèle entraîné et les conclusions du projet tirées, quelles perspectives envisagez-vous pour BigScience ?
[BigScience] On a pu observer tout au long de l'année la place unique qu’a occupée BigScience dans le contexte des projets collaboratifs de recherche en IA. En particulier, ses efforts multidisciplinaires tels que BigBio pour les applications biomédicales des modèles de langue, ou le développement d’un ensemble de ressources légales à l’usage des chercheurs en TAL - en collaboration avec la faculté de droit de New York University - montrent l’ampleur et la portée que peut avoir un investissement pour la recherche collaborative (ici un don de calcul estimé à 3M d’euros sur le supercalculateur Jean Zay). BigScience peut être conçu comme la base future pour d'autres grands projets scientifiques, lesquels seront aussi poussés par des États en support de la science ouverte. En plus des modèles, corpora, et outils techniques développés au cours du projet, tous nos procédés de gouvernance et nos investissements dans les aspects sociétaux du développement de ce type de modèle ont été conçus pour permettre la réutilisation de notre travail.
Maintenant que BLOOM est entraîné et mis à disposition, il reste aussi beaucoup à faire pour l'évaluer et pour prendre toute la mesure des nouvelles directions de recherche que permet l’accès public à un modèle de cette taille. Des travaux ont déjà commencé au sein de BigScience, mais nous espérons aussi voir de plus en plus de recherches menées sur le modèle et le corpus par des institutions qui n’ont pas forcément participé au projet initial. En particulier, nous espérons que ces travaux permettront aux instituts d’archives nationaux et autres détenteurs de données d’usage public de mieux comprendre les tenants et aboutissants de l’utilisation de ces données pour l’apprentissage d’IA et le bénéfice que le public peut en tirer. Ces institutions ont un rôle important à jouer dans un développement réellement démocratique de ces technologies.

Yacine Jernite
Yacine Jernite est chercheur à Hugging Face, ou il a participé à l'organisation du projet BigScience et co-dirigé les efforts liés aux données d'entraînement. Ses travaux portent sur la gouvernance des données et modèles d'apprentissage machine à l'intersection de leurs aspects techniques, sociétaux, et légaux, et en particulier sur les pratiques de documentation de ces systèmes.

Giada Pistilli
Giada Pistilli est l’éthicienne principale à Hugging Face, et participe au projet BigScience en tant que co-présidente du groupe de travail Éthique et Légal. Elle travaille en éthique descriptive et éthique appliquée sur l’impact des modèles d’IA sur la société, à l’intersection entre les outils de gouvernance politiques et légaux. Elle prépare également une thèse en philosophie politique et morale à Sorbonne Université.

Mathilde Bras
Mathilde Bras est experte des transformations numériques de l’action publique, engagée pour un numérique d’intérêt général et une démocratie ouverte et inclusive. Au sein d’Etalab, elle a structuré des communautés d’innovateur·trice·s, en coordonnant des actions de gouvernement ouvert et en développant le programme Entrepreneurs d’intérêt général. Elle intervient désormais auprès d’acteurs publics, privés et associatifs pour engager des actions d’ouverture et de numérique d’intérêt général.

Carlos Muñoz Ferrandis
Carlos Muñoz Ferrandis est Tech & Regulatory Affairs Counsel à Hugging Face et fait partie du groupe d´experts ONE AI de l´OCDE. Il est Co-Chair à BigScience dans le groupe de travail Légal/Étique, où il est l'un des précurseurs et auteur de la licence du modèle BLOOM. Il promeut activement l´utilisation de licences ouvertes et responsables pour l´IA. Carlos travaille aussi sur le sujet des “sandbox” et régulation expérimentale. Il a développé sa thèse doctorale en entier au Max Planck Institute for Innovation and Competition à Munich.
Illustration - Sentinel Parrots (Commons Wikimedia)


{kind=link}