
Capteurs « diminués » : Une perspective nouvelle, vers une captation d’images plus respectueuse des droits des personnes ?
Rédigé par Célestin Hernandez
-
13 mars 2025L’évolution du cadre juridique relatif aux caméras « augmentées » appelle une réflexion relative aux capteurs eux-mêmes. Dans cet article, nous nous intéressons à de nouveaux types de capteurs qui pourraient offrir des garanties renforcées pour la protection des données personnelles en complément de méthodes plus « traditionnelles » purement algorithmiques.

La loi du 19 mai 2023 relative aux Jeux olympiques et paralympiques de 2024 a autorisé, pour la première fois, la mise en œuvre de solutions d’intelligence artificielle dans la vidéoprotection pour des cas d’usage définis. Faisant la part belle à une expérimentation nationale des « caméras augmentées » cette loi vise avant tout à tester et vérifier la capacité des algorithmes à exploiter plus rapidement les images de surveillance vidéo pour la détection de certains types d’évènements.
Cependant, l’intelligence artificielle ne permet pas (en théorie) seulement d’exploiter plus efficacement des images de surveillance vidéo « classiques » mais elle permet de dépasser parfois les performances de l’œil humain notamment sur des contenus « dégradés » (cf. Geirhos et al.). Ainsi au-delà des algorithmes permettant de traiter en plus grand volume les images de surveillance vidéo d’autres peuvent être embarqués sur les caméras, à des fins de minimisation des données collectées permettant ainsi de mieux préserver les droits et libertés des personnes.
Le recours à des algorithmes pour minimiser les données collectées dispose de son lot de limitations (existence bien que partielle du flux non dégradé notamment) et la question se pose alors de l’existence de capteurs diminués par « nature ».
Le LINC s’est alors intéressé à ces capteurs « minimisés », aux opportunités qu’ils offrent, aux limites observées mais aussi à leur impact sur la définition même de « caméra ».
Caméras augmentées, RGPD et minimisation
C’est quoi d’ailleurs une caméra augmentée ?
Les notions de caméras dites « intelligentes » ou « augmentées » regroupent des usages très variés dans le domaine de l’analyse d’images (aussi appelée « vision par ordinateur »).
Les caméras augmentées sont des dispositifs vidéo « classiques » (au sens défini ci-après) auxquels sont associés des logiciels permettant une analyse automatique de l’image afin de détecter, par exemple, des formes ou des objets, d’analyser des mouvements, de détecter des événements, etc. Ces caméras sont donc très différentes de celles traditionnellement déployées : les personnes ne sont plus seulement filmées mais analysées de manière automatisée, en temps réel, avec pour effet de traiter en continu certaines informations les concernant.
Ces dispositifs peuvent s’inscrire dans des contextes et usages extrêmement divers, mis en œuvre par des acteurs publics et privés. Ils offrent plusieurs avantages techniques : ils permettent, d’une part, d’automatiser l’exploitation des images captées par les caméras, qui reste encore le plus souvent humaine (il devient possible d’exploiter le flux vidéo de plusieurs caméras et ce en simultané sans nécessiter la présence d’un opérateur humain) ; d’autre part, ils offrent une puissance d’analyse de certains paramètres qu’un œil humain ne pourrait pas atteindre (même si l’œil humain possède une supériorité relative pour l’adaptabilité et la mise en contexte du contenu visionné ; la vision par ordinateur surperforme en termes de vitesse et de précision pour des tâches complexes : estimation de la vitesse, détection d’un mouvement de foule par exemple). Ce faisant, ils permettent de valoriser des parcs de caméras déjà installés.
La minimisation ?
Le principe de minimisation du RGPD prévoit que les données à caractère personnel doivent être adéquates, pertinentes et limitées à ce qui est nécessaire au regard des finalités pour lesquelles elles sont traitées.
Il peut cependant apparaître complexe d’intenter de minimiser une collecte de données continue, profondément variable tant sur les données qu’elle peut récupérer d’une image à l’autre, que sur les finalités qu’elle poursuit. Pour la vidéoprotection, la minimisation se traduit en particulier par une interdiction pure et simple de filmer l’intérieur des immeubles d’habitations. Cependant, certaines de ces considérations peuvent être à apprécier au cas par cas en fonction des finalités poursuivies (par exemple l’interdiction de filmer à l’intérieur d’une cantine d’un établissement scolaire peut être dérogée) et restent générales, sans entrer dans les spécifications plus techniques de ce qui pourrait constituer une minimisation des données.
Il est important dans tous les cas d’apprécier suffisamment le changement de paradigme induit par la vision par ordinateur.
NDLR : Pour rappel :
- Les dispositifs de vidéoprotection filment la voie publique et les lieux ouverts au public : rue, gare, centre commercial, zone marchande, piscine etc.
- Les dispositifs de vidéosurveillance filment les lieux non ouverts au public : réserve d'un magasin, entrepôts, copropriété fermée etc.
Minimiser les données collectées par des caméras "classiques"
Ainsi, il est vraisemblablement envisageable de minimiser les données collectées par une caméra en s’adaptant aux diverses finalités poursuivies. Il est important avant cela de s’intéresser au fonctionnement des caméras, pour mieux apprécier les possibilités de minimisation.
C’est quoi une caméra « classique » ?
Une caméra permet la captation et l’enregistrement d’images animées en utilisant un capteur électronique qui transforme une information lumineuse en un signal électrique.
Elle est constituée de deux composants majeurs :
- L’objectif, qui fonctionne d’une manière similaire à la pupille en contrôlant la quantité de lumière qui pénètre dans la caméra et en la concentrant dans un point focal net.
- Le capteur, qui collecte ensuite cette lumière concentrée, et convertit l’intensité lumineuse et les variations colorimétriques en un signal numérique qui deviendra l’image.
En répétant ces « opérations » pour une suite d’images (à une fréquence de collecte donnée), on obtient alors une vidéo. Certaines dispositions techniques, matérielles ou organisationnelles peuvent être alors à considérer pour limiter les données collectées.
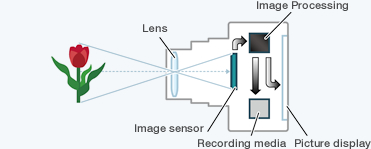
Image 1: Mécanisme simple d'une caméra (source)
Des dispositions matérielles à privilégier
DORI (Détection, Observation, Reconnaissance et Identification)
Un des principes importants de l’appréciation des données collectées dans le cadre de la vidéosurveillance est le DORI pour Détection, Observation, Reconnaissance et Identification. Ce principe permet en théorie de déterminer la résolution minimale pour parvenir à l’objectif recherché parmi les quatre de DORI.
Il permet de définir des critères objectifs pour s’affranchir des différences physiques existantes entre les caméras de différentes marques et modèles. En effet, de nombreuses variables influent sur la qualité de l'image restituée par des caméras et donc les finalités qu’elles sont en mesure d’atteindre. Certaines de ces variables sont simples et mesurables, mais beaucoup ne le sont pas. De même, certaines de ces variables sont contrôlables et d'autres non.
Le principe DORI peut fixer un PPM minimal pour les différentes tâches de : détection, d’observation, de reconnaissance et d’identification. Ce PPM se calcule (et ce indépendamment de la marque, du modèle etc.) comme suit :
PPM = Résolution (horizontale ou verticale ; en pixels) ÷ Champ de vision (horizontal ou vertical ; en mètres)
Pour les instances de normalisation (l’International Electrotechnical Committee (IEC), l’European committee for electrotechnical standardization (CENELEC) et la British Standards Institution (BSI)), les seuils pour les différentes tâches sont fixés à :
- Pour la détection : 25 PPM. A ce niveau, la personne regardant l’image est en mesure de déterminer la présence sur la photo d’un véhicule et d’une personne même si peu de détails sont disponibles pour cette dernière.
- Pour l’observation : 62 PPM. A ce niveau, quelques caractéristiques de l’individu sont exploitables (sa tenue par exemple).
- Pour la reconnaissance : 125 PPM. Ici, avec un bon degré de confiance on peut éventuellement réidentifier l’individu ; des détails comme la plaque d’immatriculation peuvent devenir exploitables dans certaines conditions.
- Pour l’identification : 250 PPM. Il est possible d’identifier la personne avec un haut degré de confiance, les détails disponibles permettent aussi de clairement lire la plaque d’immatriculation.

Image 2: Evolution illustrée de la métrique PPM pour la détection, l’observation, la reconnaissance et l’identification (source)
Le raisonnement sur la résolution peut aussi être associé à une réflexion sur d’autres modalités techniques du capteur :
- La cadence d’images collectées : les estimations varient mais globalement la cadence d’images peut être réduite de 10 à 12 images par seconde (scène extérieure à grande échelle : intrusion) et être augmentée de 30 à 60 images par seconde (en intérieur, pour reconnaissance et suivi).
- La nécessité même d’utiliser une caméra, mais nous y reviendrons plus en détails ci-après.
Il est à noter que le principe DORI est a priori applicable à l’ensemble des capteurs présentés ci-après. Une annexe sur les modalités de calcul de ce principe est disponible en fin d’article.
Volumétrie et positionnement affinés des capteurs
Raisonner sur la base DORI est un bon point de départ afin de parvenir à une finalité avec une collecte de données la plus minimisée possible. Cependant, dans la majorité des cas d’usage, les finalités ne sont pas poursuivies avec un seul et même capteur mais avec un parc entier de caméras.
Ainsi il est important de considérer, en plus de la résolution même du capteur, les problèmes d’optimisation du nombre et du positionnement des caméras pour parvenir à une finalité précise.
Globalement, sur ces problématiques d’optimisation la littérature (dont Wu et al, Costa et al) s’accorde pour tenter d’établir la définition de métriques permettant une évaluation objective du nombre de capteurs minimum, et des orientations spécifiques pour une surface donnée, ainsi que des contraintes d’obstruction données.
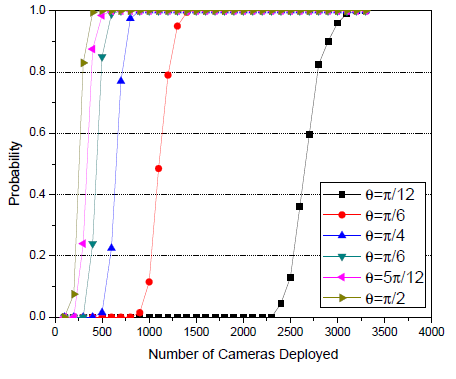
Image 3 : Wang et al. Illustrations du nombre minimal de caméras pour couvrir une frontière de 100m de long, selon l’angle de positionnement.
Wang et al. présentent par exemple un système probabiliste d’optimisation du nombre de caméras pour la couverture d’une zone de séparation (l’objectif ici étant de déterminer le nombre minimum de caméras nécessaires pour la détection d’un intrus dans une zone limitée).
Ces considérations d’optimisation le sont majoritairement pour une finalité de réduction des coûts ; cependant le raisonnement peut aussi permettre de déterminer un nombre de capteur minimal et ainsi de poursuivre un objectif de minimisation.
De ce fait, bien qu’à considérer lors de la mise en place d’un parc vidéo à des fins de minimisation, ces métriques peuvent souffrir d’une applicabilité complexe :
- les cas d’usages variés et les finalités poursuivies diverses offrent des contraintes différentes difficilement généralisables dans un calcul mathématique ;
- un angle de vue suffisant est nécessaire pour permettre un entraînement et des performances acceptables ainsi qu’une bonne généralisation (notamment) ;
- enfin, ces études considèrent pour la plupart des positionnements de caméras dits « classiques » sans évaluer des angles de vue moins communs (caméras au plafond filmant le sol par exemple) mais tout aussi intéressant d’un point de vue de la minimisation.
Une minimisation à bref délai et locale
Dégradation du flux
Les cas d’usages précédemment cités présagent, en premier lieu, du fait qu’il n’apparaît pas absolument nécessaire que l’intégralité des images captées par une caméra soit utilisée par l’intelligence artificielle :
- pour la présence d’objets abandonnés, la notion d’abandon laisse à supposer que seul l’objet et une zone périphérique restreinte suffiraient pour caractériser la détection ;
- pour le franchissement ou la présence dans une zone interdite ou sensible, seule la zone concernée apparaît comme importante à considérer. La simple présence dans cette dernière peut justifier d’un franchissement (dans la plupart des cas).
De plus, pour caractériser seulement la présence d’une personne ou d’un objet, il apparaîtrait suffisant de ne pas s’intéresser aux visages ni aux vêtements par exemple.
Les traitements pouvant être mis en place seraient alors les suivants :
- le floutage localisé, ou le remplacement par des données synthétiques des visages : He et al démontrent notamment des performances dans la détection d’objets équivalentes avec des visages floutés ou remplacés (à l’entraînement ainsi qu’à l’inférence).

Image 4 : Différentes versions dégradées d’une même image pour He et al.
- Le « silhouettage » par exemple comme peut le faire OpenPose en détectant les corps présents sur une image puis en les convertissant en silhouette. Hur et al. proposent de détecter et suivre des personnes en utilisant leurs silhouettes dans un environnement assez contraint : une salle de classe. Les résultats obtenus caractérisent une bonne réidentification et laissent à penser que la silhouette peut être suffisante, notamment pour de la détection de personnes, du comptage, etc.

Image 5 : Exemple d’une restitution proposée par OpenPose (source)
NDLR : OpenPose est un système d'estimation de pose développé par des chercheurs de l'Université Carnegie Mellon (CMU) capable de détecter et de suivre le corps humain en temps réel et de déterminer avec précision sa pose dans l'espace 3D.
Il est à noter que les exemples de mesures de minimisation cités ci-dessus impliquent la détection d’un visage ou d’une silhouette en amont du traitement algorithmique poursuivant la finalité. Il conviendrait alors d’évaluer la balance bénéfices-risques d’une telle manipulation.
- L’offuscation d’image : Coninck et al. proposent de dégrader l’image dans une forme inexploitable et non inversible tout en garantissant des performances de détections de personnes adéquates.
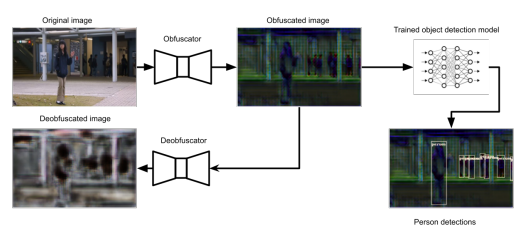
Image 6 : Illustration du modèle d’offuscation : l’image est dégradée et un algorithme contrôle la non possibilité d’inversion de l’offuscation avant de procéder à de la détection
Minimisation et sécurisation opérationnelle
Au-delà des processus de dégradation du flux vidéo, d’autres préconisations plus opérationnelles peuvent être mises en place pour assurer une minimisation supplémentaire des données, dès lors que cela est compatible avec les finalités poursuivies :
- ne pas permettre une restitution du flux mais seulement de l’alerte recherchée en restreignant ainsi l’existence du flux vidéo à des fins de contrôle (pour validation de l’alerte) ;
- limiter les tâches de détection à une zone différente de celles contenant le plus de données personnelles : Tian et al. ont par exemple démontré que pour la détection d’objets abandonnés le suivi et la détection d’objets « classiques » ne fonctionnaient pas suffisamment dans des lieux denses en personnes et en objets tiers ; l’importance ici réside dans les variations observées uniquement à l’arrière-plan (un objet abandonné est par définition statique) ;
- réaliser les opérations algorithmiques en local, directement sur le dispositif de vidéo, afin de limiter les copies de données (Rodriguez et al.) ;
- enfin, renforcer la sécurité du flux vidéo par le chiffrement homomorphe du flux vidéo (Jia et al.) et la détection sur des données chiffrées ou perturbées.
Des données minimisées mais toujours beaucoup d’information !
Une réidentification toujours possible
La problématique majeure pour la minimisation à bref délai et locale, est que cette dernière suppose l’existence (même si la plus brève possible) du flux vidéo non dégradé. En maximisant les procédures de sécurisation opérationnelle, le risque d’accès à ces images non altérées est plus facile à maîtriser. Néanmoins, l’existence éventuelle d’un parc de vidéo classique en complément des caméras augmentées réduit le bénéfice des efforts consentis pour minimiser les données.
De plus, les dégradations (et quels que soient les types de capteurs utilisés comme présentés ci-après), aussi poussées qu’elles soient, ne rendent pas pour autant les images produites anonymes :
- en cas de disponibilité d’un flux non perturbé ;
- de par la possibilité d’inversion d’un traitement de dégradation :
- suppression du flou ou de bruit ajouté (Sun et al.) ;
- reconstruction des contenus offusqués (McPherson et al.) ;
- réidentification partielle sur la base de la posture d’une personne (Liu et al.) ;
- et en cas de possibilité pour l’opérateur d’intervenir auprès d’une personne filmée, ce qui la rend de facto identifiable.
Complexité opérationnelle
Les mesures de minimisation entraînent aussi des problématiques plus opérationnelles. En effet, l’ajout de mesures de minimisation (par le biais de traitements algorithmiques supplémentaires comme vu plus haut) peut être un frein aux performances de détection en réduisant la précision ou en allongeant le temps de traitement. Aussi, l’état de l’art sur ce sujet est réduit, à la différence de celui de la détection sur des flux « classiques ». Ainsi, les bases de données d’entraînement, les modèles d’IA spécifiques peuvent être moins répandus.
Enfin, les pré-traitements de minimisation n’empêchent pas les caméras augmentées d’être exposées à des risques d’attaques. On peut citer l’exemple des motifs empêchant la détection d’un être humain (Thys et al. et Xu et al.), ou qui perturbent le réseau de neurones directement (Liu et al. et Mohamad Nezami et al.; en effet les traitements de minimisation peuvent être vus comme une augmentation de la surface d’attaque et ouvrent ainsi des perspectives encore peu étudiées : Shah et al notamment (il est à noter que la « dégradation du flux peut aussi parfois être considérée comme garantissant une robustesse à certaines attaques notamment les attaques par évasion).
Des nouveaux capteurs et une minimisation à l’origine ?
Si la minimisation à bref délai et locale offre des possibilités, elle n’est pas la seule perspective à considérer. En effet, d’autres types de capteurs peuvent répondre aux cas d’usage pour lesquels des caméras (augmentées ou non) sont utilisées. Ceux-ci peuvent offrir une minimisation à l’origine en limitant les risques évoqués plus haut.
Une première distinction dans cette famille de capteurs est à opérer entre capteurs « passifs » et capteurs « actifs ». Une caméra classique est un capteur passif dans le sens où elle reçoit une information (la lumière comme nous l’avons vu précédemment) que son capteur est en mesure de convertir en mesure physique et en donnée numérique. Les capteurs actifs, que nous verrons ensuite, émettent quant à eux un signal ou une information dont ils captent et interprètent le retour (l’écho, la réflexion, etc.).
Capteurs « passifs »
Caméras infrarouges / caméras thermiques
Les caméras infrarouges ou thermiques (puisqu’elles sont en réalité similaires) diffèrent d’une caméra classique sur le capteur qu’elles utilisent. Ce dernier n’est plus sensible à la lumière visible mais aux rayonnements infrarouges ; et ceux-ci permettent d’associer une température à une intensité lumineuse.

Image 7 : Exemple d’une image captée par une caméra thermique
L’image résultante d’une caméra thermique fournit une information supplémentaire (la température éventuelle d’une personne qui permet d’ailleurs de lever le doute sur la présence humaine plus aisément qu’avec une caméra classique) mais restitue de manière générale une image moins exploitable pour l’œil humain.
Il est à noter que les caméras thermiques peuvent d’ailleurs être confrontées au principe DORI d’une manière légèrement différente que celle utilisée pour les caméras « classiques ».

Fig 8: Detection threshold for a thermal camera (1 to 3 PPM) (source)
Detection refers to the distance at which the target appears on the screen. This target is either warmer or cooler than the surrounding environment.

Fig 9: Recognition threshold for a thermal camera (3 to 7 PPM)
Recognition refers to the distance at which it is possible to determine the class of the detected object (human, vehicle, etc.)

Fig 10: Identification threshold for a thermal camera (6 to 14 PPM)
Identification corresponds to the distance at which the observer is able to distinguish between types within a class (e.g., truck, 4x4, car).
En référence aux applications militaires qui prennent en compte les limitations de résolution déjà évoquées, le principe se décline ici en DRI : pour détection, reconnaissance et identification (différente de l’identification déjà présentée plus haut ; ici il s’agit simplement de distinguer par exemple si l’être humain déjà reconnu porte un casque ou non).
La perspective d’utiliser des caméras thermiques a déjà été explorée pour des tâches de détection de personnes, de suivi et parfois de détection d’objets avec des niveaux de performances se rapprochant des capteurs classiques. (voir Batchuluun et al. et Krišto et al. notamment)
Ces capteurs permettant généralement de protéger l’identité des individus davantage que les caméras classiques, leur utilisation peut alors être un apport dans une démarche de minimisation.
Caméras événementielles
Les caméras événementielles ou neuromorphiques se distinguent elles aussi au niveau du capteur qu’elles utilisent. A la différence des caméras classiques ou thermiques, ces capteurs essayent de se rapprocher du mode de fonctionnement de l’œil humain et notamment de son caractère asynchrone.
Une caméra classique capture des images à intervalles réguliers ; chaque image, et les pixels dont elle est composée, est un instantanée d’une scène et la représentation de la luminosité globale de cette dernière à un instant donné. Une caméra neuromorphique va quant à elle capturer des « événements » (c’est-à-dire des changements de luminosité au niveau des pixels individuels) asynchrones plus qu’une image complète.
Les données produites par une caméra classique peuvent se représenter sous la forme d’une grille regroupant la valeur de luminosité capturée pour chacun des pixels. Pour les caméras neuromorphiques, les données collectées représentent le ou les pixels concernés par un évènement.
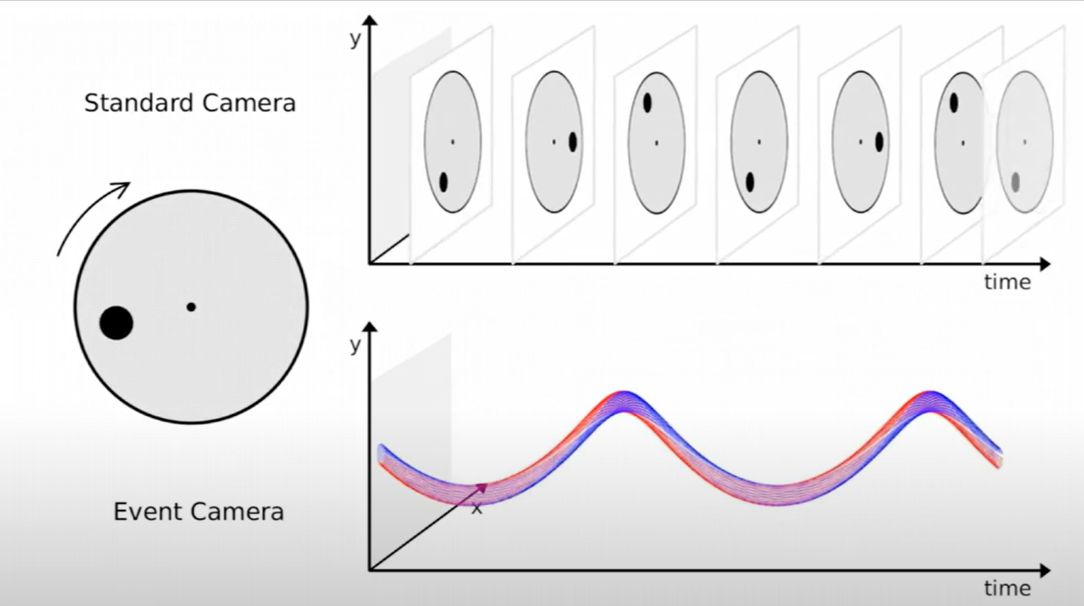
Image 11 : Illustration de ce qui est capturé par une caméra classique (en haut) et une caméra neuromorphique (en bas) pour un objet en mouvement (source)
Le cercle à gauche est en rotation, et la caméra classique va capturer à intervalles réguliers les images. Le capteur neuromorphique va quant à lui capturer et situer les changements de luminosité induits par la rotation.
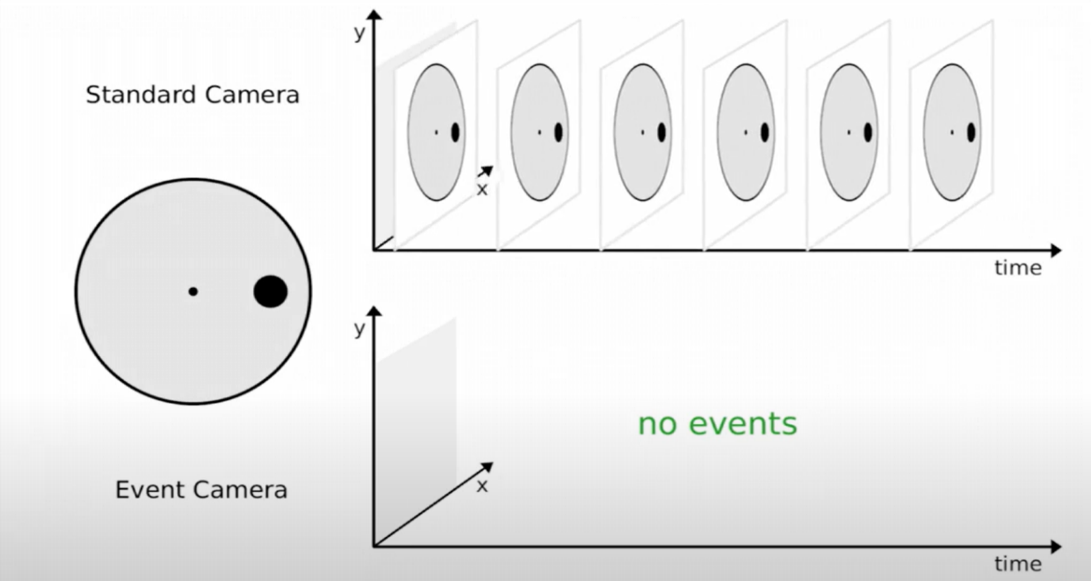
Image 12 : Illustration de ce qui est capturé par une caméra classique (en haut) et une caméra neuromorphique (en bas) pour un objet statique
Le cercle à gauche n’est plus en rotation, et la caméra classique continue à capturer à intervalles réguliers les images. Le capteur neuromorphique ne détectant plus de changements locaux de luminosité ne capture absolument rien.
Les capteurs neuromorphiques produisent alors une image qui retrace le mouvement d’un objet et qui occulte certains éléments captés par des caméras classiques (couleurs, formes précises etc.). Il est à noter que le niveau de précision de ces caméras peut tout de même permettre d’identifier des personnes lorsque celles-ci se déplacent à proximité du capteur.

Image 13 : Illustration de ce qui est capturé par une caméra classique (à gauche) et une caméra neuromorphique (à droite) (source)
Les capteurs neuromorphiques, bien que relativement récents, ont déjà été étudiés pour des tâches de détection et suivi d’objets ou de personnes avec des niveaux de performances relativement corrects. (Liu et al. par exemple)
Les capteurs actifs
Les capteurs actifs comme évoqué plus haut doivent émettre un signal afin de collecter des informations, dans la même optique qu’une chauve-souris utilisant l’écholocalisation pour se représenter le paysage nocturne qu’elle essaye de traverser.
LIDAR (détection et estimation de la distance par la lumière)

Image 14 : Exemple d’un nuage de points 3D qu’est en mesure de capturer un LIDAR (source)
Le LIDAR, acronyme anglais équivalent à « détection et estimation de la distance par la lumière » (light detection and ranging), est un capteur cherchant à déterminer les distances qui le séparent des objets présents dans une scène en émettant un signal lumineux (par le biais d’un laser) et en mesurant le temps que met ce signal à revenir à son origine ; ce faisant ils produisent une cartographie (souvent exploitée dans des travaux de géologie par exemple mais aussi à bord de l’ISS pour déterminer la hauteur et la structure de la végétation dans une canopée). Ces capteurs sont souvent composés d’une multitude d’émetteurs permettant une restitution plus fidèle et précise (et ainsi une cartographie 3D plus « profondément exploitable »).
Les LIDAR peuvent être utilisés à des fins de détection et suivi de personnes ou d’objets, même s’ils ne fournissent pas une représentation aussi détaillée que les capteurs classiques.
TOF (temps de vol)
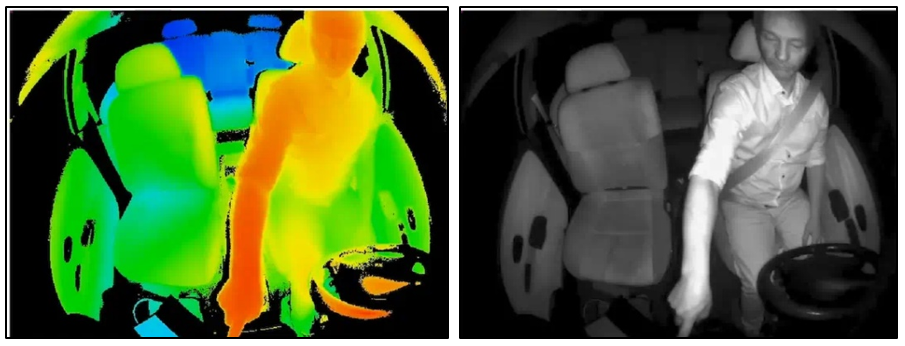
Image 15 : Illustration de ce qui est capturé par un capteur TOF (à gauche) et une caméra classique (à droite) (source)
Les capteurs TOF ou time of flight ou encore « temps de vol » ont un fonctionnement similaire aux capteurs LIDAR (dont l’utilisation est plus répandue). Les capteurs « temps de vol » disposant d’un émetteur laser sont d’ailleurs considérés comme partie intégrante de la famille des LIDAR. La distinction est opérée notamment pour les cas d’usage poursuivis par les deux types de capteur.
Les dispositifs « temps de vol » sont utilisés pour des applications civiles depuis les années 2000. Ils sont notamment utilisés dans les caméras de smartphones à des fins d’amélioration de la qualité des prises de vue (notamment les fonctionnalités « portrait ») mais aussi dans le domaine de la robotique. En effet, ces capteurs sont légers, performants et permettent aux systèmes embarqués de procéder à l’élaboration de représentations visuelles (comme une carte de l’espace pour de la détection d’obstacles pour un aspirateur par exemple) de manière rapide et fiable.
Au-delà de ces applications, il est à noter que les capteurs « temps de vol » sont déjà considérés dans la recherche pour des cas d’usage de vidéo intelligente :
- détection et estimation du flux de personnes sur la base d’une captation « temps de vol » ;
- détection d’objets et classification.
Les avantages d’une minimisation à l’origine
Des avantages généraux
Pour l’ensemble des capteurs présentés jusqu’ici, nous avons pu constater que :
- la littérature scientifique présente des situations où ces capteurs sont utilisés pour détecter des événements tels que la présence d’objets abandonnés, la présence humaine, ou pour mesurer une densité de personnes avec des performances pouvant être considérées comme à prime abord « satisfaisantes » ;
- ces capteurs produisent des représentations visuelles différentes de celles d’une caméra classique. Elles peuvent être considérées comme « diminuées » dans la mesure où elles contiennent moins d’informations directement exploitables visuellement (même si le LIDAR et les capteurs thermiques fournissent par exemple une information supplémentaire : la température ou la distance), en particulier pour un observateur humain ;
- ces capteurs minimisent les données collectées sans avoir recours à un traitement algorithmique, il n’existe alors pas de version « claire » du flux non dégradé puisque ce dernier n’est jamais collecté. Ces capteurs permettent alors de ne pas recueillir d’informations de manière injustifiées lorsque la finalité poursuivie ne nécessite pas des représentations « classiques ».
Mais aussi des gains spécifiques à certains capteurs
Au-delà de ces avantages globaux identifiés il est à noter que :
- pour les LIDAR :
- les puissances de calculs requises pour opérer sur un nuage de points 3D sont moins élevées que celles nécessaires à un flux vidéo classique ;
- la possibilité de disposer d’une information de profondeur peut garantir l’évitement de certaines limites posées par la détection sur des images classiques. La notion de profondeur permet aussi de régler des seuils de détection (en excluant par exemples les distances trop faibles ou élevées) ;
- pour les caméras événementielles :
- ces dernières consomment et stockent dans tous les cas moins de données (puisqu’une absence d’événements suppose une absence d’enregistrement),

Image 16 : Exemple d’une détection erronée d’un algorithme sur une image classique (la publicité est identifiée comme un piéton (source)
- elles fonctionnent mieux dans des dispositions parfois moins bien supportées par les capteurs classiques (mouvements de foules par exemple ; en effet les caméras neuromorphiques sont moins assujetties au flou puisqu’elles disposent d’une résolution temporelle beaucoup plus élevée qu’une caméra classique).
Mais ces solutions ne sont pas non plus exemptes de risques
Ces gains relatifs sont néanmoins à mettre en perspective avec leurs risques ou limitations.
- les attaques précédemment citées sont aussi susceptibles d’être mises en place pour d’autres capteurs :
- utilisation d’objets réfléchissant pour attaques adverses sur un capteur LIDAR permettant de perturber la détection d’objets ;
- utilisation d’un falsificateur (émetteur de rayons lumineux) pour fausser les détections d’un LIDAR ;
- perturbation du flux d’évènements collectés pour tromper le détecteur ;
- « contournement » de la minimisation : possibilité par exemple de reconstruire une image sur la base d’un flux d’événements.
Ces attaques, bien que comparables (présentations adverses) à celles utilisées pour des capteurs classiques diffèrent néanmoins sur le fait que la levée de doute par un opérateur humain n’est pas aussi aisée que pour une image classique. Par exemple, il est difficile sur un nuage de points 3D ou sur un mouvement de pixels de déterminer si les données affichées sont altérées par un attaquant ou révèlent un type d’événement inconnu…
Ces capteurs n’exemptent pas non plus des considérations de minimisation et de sécurisation opérationnelles et techniques déjà présentées plus haut puisqu’ils ne produisent pas dans tous les cas une donnée intrinsèquement anonyme (l’évaluation du caractère anonyme se fait au cas par cas et en fonction des cas d’usages).
Et une généralisation plus difficile à envisager
Au-delà des problématiques d’exposition à des attaques il est à noter que les capteurs « diminués » tels que présentés entraînent des contraintes opérationnelles qui peuvent ralentir leur adoption.
En effet, l’hégémonie des caméras laisse à supposer une transition difficile vers de nouveaux capteurs surtout en considérant que ces derniers :
- ne bénéficient pas d’un investissement de la recherche aussi important que pour les caméras classiques (sur les algorithmes notamment, en effet ceux permettant la détection par exemple sont spécifiques à la nature des données, et donc ne sont pas transposables (trivialement en tout cas) d’un capteur à l’autre. Il en est d’ailleurs de même pour les bases de données ou les communautés ;
- ne garantissent pas l’absence de collecte de données à caractère personnel (quand bien même ils entraînent, par rapport aux caméras, une minimisation effective des données collectées) ;
- enfin, la majorité de ces capteurs demeure aujourd’hui plus coûteuse au prix unitaire que des caméras.
Au final pourquoi une caméra ?
En considérant bien les évolutions de l’intelligence artificielle et ses capacités il est important de se demander si le problème relatif à la minimisation sur des capteurs vidéo, ne réside pas dans la vision trop anthropomorphique de la vision par ordinateur ? En effet, si l’on peut envisager l’importance de rendre la plus humaine possible une interface purement orientée vers la communication directe avec un être humain ; il convient de se demander si un ordinateur a réellement besoin de voir comme nous afin qu’il détecte ce que l’on souhaite. De la même manière qu’un véhicule motorisé n’a plus grand-chose à voir avec un marathonien d’un point de vue purement technique et organique, pourquoi un capteur purement destiné à une détection automatique devrait-il imiter notre œil ? Certains véhicules autonomes abandonnent déjà les caméras pour utiliser seulement des LIDAR, les robots et capteurs embarqués dans nos domiciles se dotent d’une vision d’autant plus réduite.
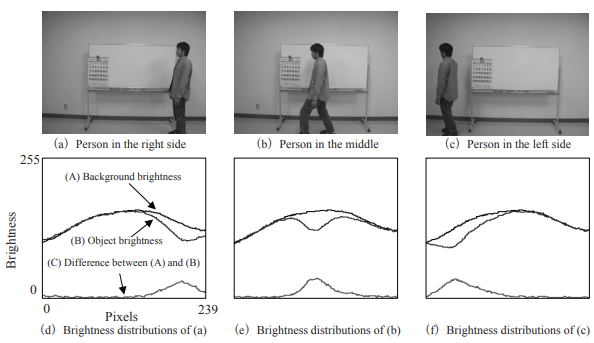
Image 17 : Visualisation de la présence ou non d’une personne
et de sa localisation sur l’image par
la simple évolution de la distribution de la luminosité. (Source)

Image 18 : Comparaison entre la vue d’une caméra « classique » et celle pouvant être utilisée par des robots ménagers par exemple. La dégradation ne se fait pas algorithmiquement mais bien sur le capteur directement. (source)
Lewis Mumford, partisan d’une technique plus durable, écrit d’ailleurs dans son livre Techniques et Civilisations « le type de machine le plus inefficace est l'imitation mécanique réaliste d'un homme ou d'un autre animal ».
Cependant, réclamer d’une technologie qu’elle soit la plus minimaliste possible peut revenir à exclure la possibilité pour un humain de revenir sur ce que « la machine » a décidé ou a cru voir. Il est nécessaire de mettre en balance le principe de minimisation avec le besoin de transparence (donc d’explicabilité) qui implique de pouvoir rendre compte des traitements automatisés et de leurs résultats.
Il est dans tous les cas importants de considérer par quoi nous accepterions d’être détectés, observés et éventuellement jugés. Même si les caméras ne sont pas toujours celles que l’on pense, ni là ou on pense qu’elles se trouvent (Liu et al. démontrent notamment la faisabilité d’une reconstruction d’images à partir du capteur de proximité d’une tablette ; soit un capteur d’un seul pixel de résolution).
Les perspectives d’évolutions sont nombreuses et donneront peut-être à voir une technique plus minimaliste et moins organique.
Illustration (haut de page) : Pixabay, revisitée.


