
Peut-on évaluer la richesse en données des contenus culturels ?
Rédigé par Olivier Desbiey
-
09 février 2016Si les consommations de contenus culturels numériques renferment pour la plupart des informations sur les goûts et habitudes de leurs utilisateurs, leur densité et leur richesse varient en revanche grandement selon le type de contenu considéré.

S’il parait évident que l’on peut déduire des informations assez intimes de la vie d’un utilisateur sur la base des contenus culturels qu’il consomme – d’abord parce qu’il consomme ce qui lui plait, et ensuite parce que c’est au contact des œuvres que s’élaborent et se réinvente son identité – on ne peut probablement inférer les mêmes caractéristiques d’une playlist musicale, d’un roman, du premier épisode d’une série ou d’un jeu sur smartphone. Nous avions consacré une partie de notre Cahier IP 3 « Les données, muses et frontière de la création », à l’exploration de la spécificité des données personnelles culturelles.
La nature de ces contenus et certaines de leurs propriétés vont en effet grandement influer sur leur potentiel prédictif associé au profil de celui qui les consomme. Le dernier roman lu est probablement plus révélateur des goûts profonds de l'individu que le dernier morceau de musique écouté; ce dernier pouvant être davantage influencé par le contexte (selon le moment de la journée, l’activité, l’entourage,…) et donc très riche en enseignements sur les modes de vie.
La richesse en données : entre points de données algorithmisables et représentations sociales
Pour caractériser ces différences, nous nous sommes appuyés sur sept critères permettant de décrire et d’évaluer la richesse en points de données par unité de contenu, pour chacun de nos quatre secteurs d’intérêt. Par « unité de contenu », nous souhaitions mettre en avant la « granulométrie » de notre réflexion : une unité de contenu est un « grain » cohérent de contenu qui peut être consommé. Une « œuvre » en tant que telle, dans le sens d’un objet fini : une chanson, un livre, un film ou un épisode de série, un jeu vidéo. Chacun de ces grains possédant des caractéristiques propres en termes de qualités et quantités de points de données.
Volume

Densité

Agrégation

Contexte
Indique dans quelle mesure la consommation de contenus peut être influencée par l'environnement.
Valeur Marginale

Engagement

Décrit l’investissement de l’utilisateur dans la consommation de chaque unité de contenu. Si un utilisateur peut écouter un titre de musique en faisant autre chose ou parce qu’il était programmé dans une playlist, son engagement est en revanche maximal pour un jeu vidéo où son expérience de jeu est unique, ou pour un livre, qui va lui demander de dédier plusieurs heures à la lecture.
Réputation

On comprend de la combinaison de ces critères, comment, au travers d’une unité de contenu ou d’une collection, il est possible de construire des modèles de recommandation basés d’une part sur le profil calculé de l’utilisateur et d’autre part sur les liens unissant différents contenus. Ce travail implique une « science » des données qui va bien au-delà de la seule fabrication d’algorithmes. Les data scientists ne sont pas juste là pour la science du code et des mathématiques mais aussi pour apporter une analyse substantielle. Comme le dit Drew Conway, auteur d’un célébre « diagramme de Venn des data science » :
"Data plus math and statistics only gets you machine learning, which is great if that is what you are interested in, but not if you are doing data science. Science is about discovery and building knowledge, which requires some motivating questions about the world and hypotheses that can be brought to data and tested with statistical methods."
Le tableau résume les spécificités en points de données de chacun des quatres secteurs. Il met en évidence qu'il n'existe pas une grande catégorie de données personnelles mais tout un archipel de données très variées associées aux consommations de services culturels et ludiques : chaque type de contenu créatif a des propriétés très fortes et distinctives qui permettent des usages et des analyses eux aussi très variés.
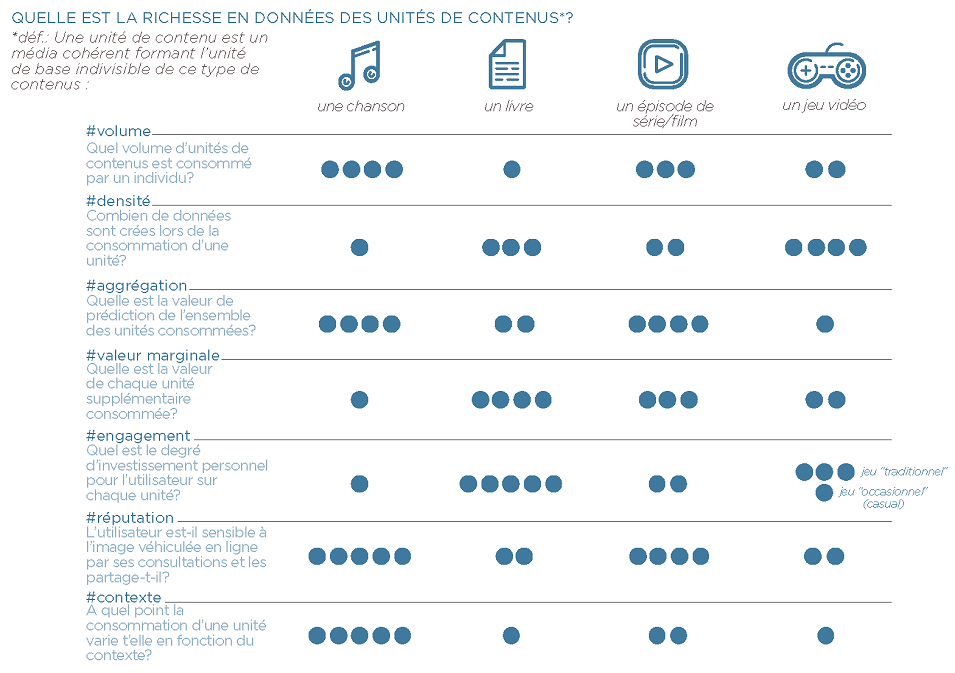
Les critères décrivent à la fois des éléments objectivables des contenus que l’on retrouve dans les métadonnées (nombre de pages d’un livre, « bpm » d’un morceau de musique, liste des acteurs d’un film, difficulté d’un jeu vidéo) et des éléments plus qualitatifs, liés à des représentations sociales et des comportements. Les métadonnées sont particulièrement utiles pour entrainer les algorithmes et générer des graphs entre des contenus similaires, quand les autres données, parce qu’elles révèlent des univers de représentation plus subjectifs, sont plus délicates à capturer et à interpréter. On sait ainsi que l’algorithme de Spotify, pour améliorer les recommandations personnalisées, n’intègre pas les morceaux lus en mode ‘écoute privée’ (dont on devine que l’utilisateur ne souhaite pas en faire la publicité auprès de son réseau). Un choix pertinent lorsque l’on sait que 25% des utilisateurs de service de streaming musical ont déjà été influencés dans leurs choix d’écoute ou de partage, sachant que leurs écoutes pouvaient être vues par leurs contacts ou amis (source Médiamétrie 2015).
C’est probablement tout l’enjeu des fonctionnalités de recommandation : arriver à capturer cette dimension sensible de nos pratiques culturelles...


