On a testé le chiffrement homomorphe !
Rédigé par Monir Azraoui
-
25 mars 2025Nous avons accueilli en juillet 2023 Paul Canchon, étudiant de dernière année en école d’ingénieur, pour un stage de six mois au sein du service de l’expertise technologique afin de tester l’applicabilité du chiffrement totalement homomorphe (FHE) à des tâches d’apprentissage automatique. Son travail démontre que la mise en œuvre du FHE est à la portée de personnes non expertes en cryptographie. Cependant, la technologie disponible actuellement se limite, notamment pour des raisons de temps de calcul, à des cas d’usage relativement restreints, en attendant le développement d’améliorations pouvant ouvrir de nouvelles possibilités.

Introduction
Le chiffrement permet de protéger les données lorsqu'elles sont stockées (chiffrement au repos) ou lorsqu'elles transitent sur un réseau (chiffrement en transit). Toutefois, le chiffrement « traditionnel » requiert que les données soient déchiffrées pour pouvoir être traitées.
Le chiffrement (totalement) homomorphe (FHE) peut renforcer la protection des données même lors de leur utilisation. Il permet de réaliser des opérations sur des données chiffrées sans que celles-ci n’aient à être déchiffrées. Ainsi, le traitement des données peut être réalisé de manière sécurisée, même par des tiers (comme un serveur de cloud) sans jamais exposer les données en clair. Le résultat des opérations reste chiffré et seul le destinataire autorisé, détenant la clé de déchiffrement, pourra accéder à l'information en clair. Cela représente un changement important dans la manière de gérer la confidentialité des données, notamment dans des situations où le traitement de données est délégué à un tiers (par exemple, dans le cadre de services cloud).
Les services de la CNIL (celui de l’expertise technologique, celui de l’intelligence artificielle, ainsi que le LINC) avaient déjà identifié le FHE comme une technologie prometteuse dans la protection des données personnelles, que ce soit dans le cadre de l’utilisation de services cloud, ou dans le cadre de traitements d’intelligence artificielle. Par ailleurs, lors d’entretiens menés avec des experts en cryptographie en 2022 , tous les experts auditionnés ont reconnu le FHE comme figurant parmi les technologies à fort potentiel pour la protection des données.
C’est dans ce contexte que nous avons accueilli, entre juillet 2023 et janvier 2024, Paul Canchon, étudiant en spécialité informatique et cybersécurité en école d’ingénieurs, pour un stage de six mois. L’objet du stage consistait à explorer la technologie de chiffrement homomorphe en concevant et en mettant en œuvre une preuve de concept sur un ou des cas d’usage pratiques de traitement de données personnelles faisant intervenir des algorithmes d’apprentissage automatique. Les interrogations auxquelles ce travail a tenté de répondre étaient les suivantes :
- l’utilisation du FHE est-elle encore trop complexe pour un non expert en cryptographie ?
- quelles performances peut-on espérer aujourd’hui dans l’utilisation du FHE ?
- dans quelle mesure le FHE est-il applicable dans des cas d’usage pratiques ?
Qu’est-ce-que le FHE ?
Le chiffrement totalement homomorphe (FHE) a longtemps été considéré comme un graal de la cryptographie. Cette technologie permet d’effectuer des opérations mathématiques sur des données chiffrées sans connaître les données en clair sous-jacentes. Concrètement, cela signifie que des calculs peuvent être réalisés directement sur les données chiffrées, produisant un résultat chiffré qui, une fois déchiffré, correspond au résultat du calcul comme s’il avait été effectué sur les données en clair.
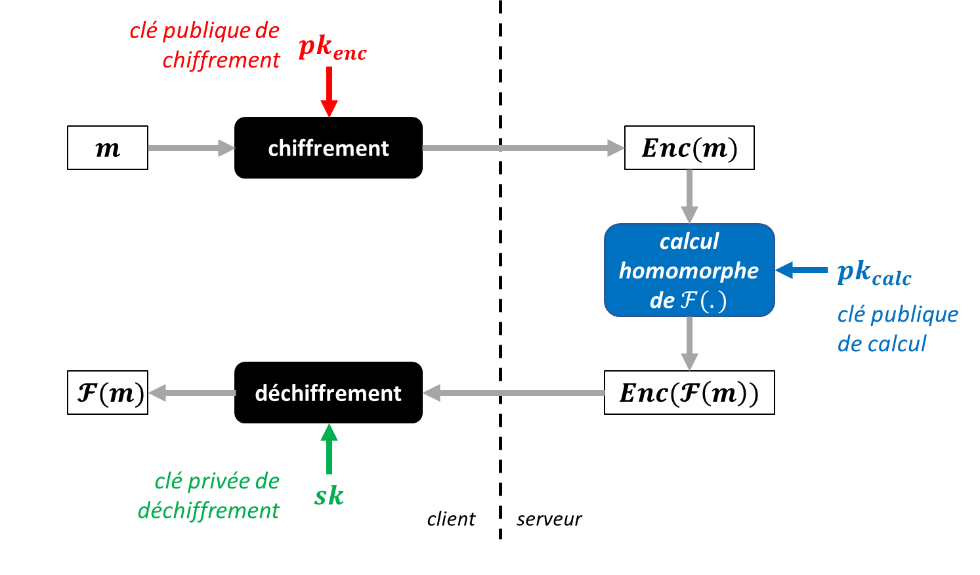
Le FHE permet d’effectuer des opérations (F ) sur des données chiffrées (Enc
), sans avoir accès aux données en clair (m
), aux clés permettant de déchiffrer les données (sk
), ni au résultat de l’opération (F(m)
). Le serveur n’a besoin que d’une clé publique, générée par le client, permettant d’effectuer le calcul homomorphe.
Il existe plusieurs types de chiffrement homomorphe, selon la complexité des opérations que l’on peut réaliser sur le chiffré :
- le chiffrement « partiellement homomorphe » ne permet ainsi de réaliser qu’un seul type d’opération, l’addition ou la multiplication. Bien que d’un usage moins général que le chiffrement presque ou totalement homomorphe, il a un grand intérêt du fait de sa plus grande efficacité ;
- le chiffrement « presque homomorphe » (somewhat homomorphic encryption) permet d’effectuer un certain nombre d’opérations avant que le chiffré en résultant ne devienne impossible à déchiffrer ;
- le chiffrement « totalement homomorphe » (fully homomorphic encryption ; FHE) permet de réaliser un nombre arbitraire d’opérations sur les chiffrés et dispose donc en théorie des applications les plus nombreuses.
Imaginé dès la fin des années 1970, une première réalisation théorique du FHE n’est apparue qu’en 2009 grâce aux travaux de Craig Gentry[1]. Le FHE a longtemps souffert de son image de mécanisme complexe et coûteux, le rendant peu utilisable en pratique. Néanmoins, le FHE a depuis évolué pour devenir plus pratique et plus performant grâce à divers schémas de chiffrement, dont le schéma TFHE[2], l’un des FHE les plus performants actuellement.
Par ailleurs, des outils sont aujourd’hui disponibles en source ouverte pour expérimenter et développer des applications, notamment à base d’apprentissage automatique, dans le monde chiffré.
Quelles sont les implications du FHE dans le domaine de l’apprentissage automatique ?
Le FHE offre des possibilités inédites dans de nombreux domaines, y compris dans celui de l’apprentissage automatique. En effet, de nombreuses applications d’apprentissage automatique nécessitent le traitement de vastes quantités d’informations, notamment de données personnelles, pour l'entraînement et l'évaluation des modèles. Ces tâches comprennent le traitement de texte, l’analyse de données de santé, la reconnaissance du locuteur ou encore la reconnaissance faciale.
L’application du FHE pourrait permettre de concilier la nécessité de traiter des données personnelles pour entraîner et exploiter des modèles et celle de préserver la confidentialité de ces données et la vie privée des personnes concernées.
Pour qu’un système d’apprentissage automatique remplisse ces exigences, trois garanties doivent être prévues :
1. la protection des données d’apprentissage lors de l’entraînement d’un modèle ;
2. la protection des données en entrée lors de l’utilisation d’un modèle entraîné ;
3. la protection des données en sortie lors de l’utilisation d’un modèle entraîné.
Le FHE pourrait en théorie répondre à ces trois objectifs de protection des données car il permet de traiter les données sans jamais les exposer en clair :
- lors de l’utilisation d’un modèle (garanties 2 et 3), notamment dans une architecture client-serveur ou « ML-as-a-service » dans un cloud, un client pourrait chiffrer ses données d’entrée en utilisant un système de FHE, les envoyer au serveur qui effectue les calculs nécessaires et renvoie les résultats chiffrés au client. Le serveur ne voit jamais les données en clair et seul le client peut déchiffrer les résultats.
- en ce qui concerne l'entraînement des modèles, bien que cette tâche soit encore complexe avec le FHE, elle représente un domaine de recherche actif. Actuellement, entraîner un modèle avec des données chiffrées est difficile, mais des progrès importants sont attendus. Le FHE permet de maintenir les données chiffrées tout au long de la phase d'entraînement, incluant les calculs et les mises à jour des paramètres du modèle. Ainsi, même le fournisseur de services d'apprentissage automatique ne peut pas accéder aux données en clair utilisées pour l'entraînement.
En outre, le FHE garantit que le transfert de données chiffrées vers un serveur d’apprentissage automatique est sécurisé contre tout acteur malveillant, limitant ainsi les violations de données.
En résumé, le FHE permet d’offrir des garanties de protection des données dès la conception (privacy-by-design) en protégeant les données contre un fournisseur de modèle un peu trop curieux, mais aussi des garanties de sécurité vis-à-vis de tiers malveillant.
Quels sont les défis potentiels du FHE pour l’apprentissage automatique ?
Malgré ses promesses, le FHE présente des défis importants en termes de performance, de complexité et de précision qui doivent être surmontés pour devenir une solution viable dans de nombreux domaines pratiques.
Temps de traitement plus longs que sur des données en clair
Les opérations sur des données chiffrées sont plus lentes et consomment plus de ressources que celles sur des données en clair. Cela peut entraîner des limitations pour les applications d’apprentissage automatique, surtout dans les environnements à ressources limitées ou nécessitant un traitement en temps réel (comme la détection d’intrusion dans un système informatique ou la reconnaissance faciale pour le contrôle d’accès).
Taille des données chiffrées
Les données chiffrées en FHE occupent beaucoup plus d'espace de stockage et de mémoire que les données en clair. De plus, les résultats intermédiaires des opérations homomorphes dans le cadre de l’utilisation d’un modèle d’apprentissage automatique augmentent encore cette taille.
Entraînement d’un modèle sur des données chiffrées
Comme rapidement évoqué précédemment, entraîner un modèle d’apprentissage automatique sur des données chiffrées avec du FHE est une tâche difficile à l’heure actuelle. En effet, des opérations mathématiques typiques des entraînements de modèles d’apprentissage automatique comme le calcul du gradient dont le calcul de dérivées des fonctions d’activation et la rétropropagation du gradient de la fonction objectif sont, pour le moment, difficilement compatibles avec des données chiffrées. Par ailleurs, un autre problème est de savoir quand l’entraînement doit s’arrêter. Comme les données et les poids du modèle sont chiffrés, il est difficile de savoir si le modèle est sur ou sous-entraîné.
Dégradation de la précision du modèle
Pour fonctionner efficacement sur des données chiffrées en FHE, les modèles pourraient devoir être adaptés et optimisés, ce qui pourrait entraîner des changements mineurs dans les mesures de précision du modèle. Les fonctions non-linéaires, notamment celles utilisées comme fonctions d’activation dans les réseaux de neurone (ReLU, sigmoïde, etc.) sont particulièrement difficiles à reproduire avec précision dans le domaine chiffré. De plus, l’encodage, c’est-à-dire la conversion des données de nombres réels en nombres entiers pour le FHE, peut également entraîner une perte de précision, exigeant un compromis à trouver entre précision du modèle et rapidité des calculs homomorphes.
Malgré ces obstacles à l’application du FHE à l’apprentissage automatique, il nous est apparu nécessaire d’explorer concrètement l'efficacité de cette technologie dans le cadre de cas d'usage pratiques.
Quels enseignements peut-on tirer du stage ?
Notre stagiaire s'est vu confier la mission de tester une bibliothèque open source de FHE et de machine learning, le framework Concrete (de l’entreprise Zama), pour réaliser des preuves de concept. Il existe un certain nombre de bibliothèques ouvertes de plus en plus avancées qui prennent en charge le calcul en FHE (SEAL de Microsoft, HElib développé par IBM, le projet OpenFHE développé par Duality, etc.). Nous avons fait le choix pour le stage d’utiliser le framework Concrete en raison de son caractère open source et de son ambition de rendre le FHE accessible à tous les développeurs. En particulier, ce framework propose un compilateur qui permet de rendre un programme compatible avec des données chiffrées en FHE, en faisant abstraction des fonctions cryptographiques de bas niveau, facilitant ainsi son utilisation.
Le stage s'est déroulé en plusieurs phases, avec pour objectif principal de tester et d'évaluer la performance des modèles d’apprentissage automatique en environnement chiffré. Pour ce faire, dans une première phase, une phase de « découverte », notre stagiaire, non-expert en cryptographie, s’est approprié le framework, afin de répondre à notre première interrogation de savoir si un non-expert pouvait développer des programmes compatibles avec le FHE. Dans une deuxième phase, il a développé deux preuves de concept : la détection de trafic malveillant par analyse de logs et la reconnaissance faciale, à partir de données mises à disposition en ligne par des équipes de recherche académique. Avec une grande autonomie dans le choix des algorithmes d'apprentissage automatique à utiliser, notre stagiaire a entrepris une analyse approfondie de ces cas d'usage, en se basant sur des modèles existants et en explorant les possibilités offertes par la bibliothèque de FHE.
Concernant le premier objectif, le framework Concrete est relativement simple à utiliser avec les modèles intégrés (SVM, régression logistique, régression linéaire, arbres de décision, forêts aléatoires et XGB), leur manipulation étant presque identique à celle des modèles de bibliothèque d'apprentissage automatique, comme scikit-learn. En particulier, l'utilisation du compilateur permet de convertir facilement un modèle classique en un modèle compatible avec le chiffrement homomorphe. Toutefois, pour des modèles de réseaux de neurones définis par le développeur, il est nécessaire de faire quelques ajustements à la main avant de faire appel au compilateur. Dans l’ensemble, le stage a montré que le FHE est devenu accessible pour un non-expert.
Concernant les performances, les modèles exécutés sur des données chiffrées en FHE atteignent des résultats de scoring (le f1 score pour la classification et l’erreur moyenne absolue pour la régression) relativement similaires aux modèles de bibliothèque d'apprentissage automatique, comme scikit-learn. La principale différence concerne les temps d’inférence. Même si les modèles sur données chiffrées peuvent obtenir de bons résultats pour un temps d’inférence relativement court, les résultats montrent qu’ils restent 1000 à 100 000 fois plus lent que les modèles classiques. Les modèles d’arbres sont particulièrement sensibles à cette différence de performance. Cela vient du fait que sur des modèles non linéaires, le FHE nécessite des opérations supplémentaires coûteuses (ce sont les opérations de bootstrapping).
Le premier cas d'usage a porté sur la détection de trafic malveillant, utilisant des modèles SVM et XGB. Pour faire cette détection, Paul a utilisé le jeu de données CICIDS2017 contenant des logs (fictifs) pouvant contenir des données personnelles comme des adresses IPs. Ces logs sont donc chiffrés en FHE et analysés en utilisant les modèles précités. Les résultats obtenus sont satisfaisants en termes de précision du modèle, comparé à l’exécution du modèle sur des données en clair. L’inconvénient majeur reste le temps d’inférence lors de l’utilisation du chiffrement FHE comparé à des données en clair. De plus, la taille des données chiffrées en utilisant le chiffrement homomorphe est généralement au moins 1000 fois plus importante que les données non chiffrées. Finalement, on peut conclure que l’utilisation de modèles dans un problème demandant de faire de l’inférence sur des données chiffrées en temps réel, comme pour de l’analyse de logs chiffrés via un IDS, semble difficilement réalisable pour le moment avec ce dispositif. Cependant, on peut trouver un intérêt au FHE dans un contexte ne nécessitant pas de réponse en temps réel. En reprenant notre cas d’usage, on peut imaginer qu’au lieu de réaliser les analyses au niveau d’un IDS, on pourrait les faire lors d’une investigation forensique sur des logs chiffrés.
Le second cas d'usage ambitionnait de réaliser une reconnaissance faciale basée sur des réseaux de neurones appliqués à des données chiffrées. L'objectif initial consistait à implémenter toute la chaîne du processus (détection de visages, extraction des caractéristiques et comparaison de celles-ci avec une base de test) dans le domaine chiffré. Cependant, les limitations de la bibliothèque utilisée à l’époque du stage, notamment la prise en charge limitée de certaines fonctions de réseaux de neurones, ont rendu ce travail fastidieux. Le cas d’usage a donc été restreint à la première étape, à savoir la détection de visage sur une image chiffrée en FHE, en utilisant un modèle de réseau de neurones. Néanmoins, la réalisation du cas d’usage n'a pas abouti en raison de la complexité et du temps d'inférence prohibitif. Les difficultés rencontrées lors de l'utilisation du framework Concrete montrent que le chiffrement homomorphe présente encore des défis importants pour la détection de visage et la reconnaissance faciale dans ce contexte.
Enseignements tirés
L'expérience du stage a permis de mettre en lumière plusieurs aspects du FHE. Tout d'abord, il est apparu que l'utilisation de la bibliothèque de FHE était relativement accessible, même pour un non-expert en cryptographie. Les API simples et les modèles pré-implémentés ont facilité la manipulation et le déploiement d’algorithmes d’apprentissage automatique en FHE. De plus, les résultats obtenus ont démontré que les modèles d'apprentissage automatique en FHE pouvaient fournir des performances en termes de précision comparables à celles des modèles non chiffrés, tout en préservant la confidentialité des données.
Cependant, plusieurs défis ont été rencontrés tout au long du stage. Le principal défi était lié au temps d'exécution significativement plus long des modèles en FHE par rapport aux modèles non chiffrés. Ce délai, bien que compréhensible compte tenu de la nature du chiffrement homomorphe, représente encore une contrainte non négligeable pour les applications en temps réel. De plus, des contraintes matérielles ont limité la taille des modèles pouvant être traités, ce qui a posé des défis supplémentaires en termes de complexité des tâches envisagées.
Perspectives (implications pour la CNIL)
Sur la base des enseignements tirés de cette étude, une autorité de protection des données comme la CNIL pourrait formuler les recommandations suivantes à destination des organismes intéressés par l'application du chiffrement homomorphe (FHE) dans le domaine de l’apprentissage automatique :
- Le FHE, bien que complexe, est de plus en plus accessible grâce à des bibliothèques comme Concrete.
- Les modèles d’apprentissage automatique utilisant le FHE peuvent offrir des performances similaires en termes de précision par rapport aux modèles non chiffrés. Toutefois, les organismes doivent être conscients des limitations actuelles en matière de temps d'inférence, qui peuvent être sensiblement plus longs.
- Pour cette raison, le FHE n'est pas encore adapté à des applications nécessitant des analyses en temps réel. L'utilisation du FHE semble aujourd’hui plus adapté à des tâches qui ne nécessitent pas de réponses immédiates.
- Les modèles linéaires sont plus adaptés à l’usage du FHE en raison de leur compatibilité avec la réalisation d’opérations chiffrées que ce n’est le cas pour les modèles non linéaires, rendant l’utilisation de ces derniers pas encore optimale dans un environnement chiffré.
Néanmoins, le stage a montré que l'utilisation du FHE permettait de traiter des données personnelles tout en préservant leur confidentialité, dans l’esprit du privacy-by-design, ce qui pourrait être particulièrement pertinent dans les secteurs régulés comme le régalien, la santé ou la finance.
Les responsables de traitement des données qui pourraient trouver les limitations actuelles de performances du FHE trop contraignantes, devraient envisager d'autres technologies de protection des données, telles que le calcul multipartite sécurisé (MPC). Mais qu'il s'agisse du FHE ou du MPC chaque avancée technologique contribue à mieux garantir la confidentialité et la sécurité des données personnelles.
Remerciements
L'auteur tient à remercier Paul Canchon pour son investissement lors du stage.
[1] Gentry, C. (2009). Fully homomorphic encryption using ideal lattices. In Proceedings of the forty-first annual ACM symposium on Theory of computing (pp. 169-178).
[2] I. Chilloti et al. (2020). TFHE: Fast Fully Homomorphic Encryption over the Torus. In Journal of Cryptology (pp. 34-91).
Illustration : pexels