
Projet sur l’IA open source - Généalogie des modèles et base de données présents sur la plateforme Hugging Face
Rédigé par Nicolas Berkouk, Expert Scientifique IA et Anna Charles, Stagiaire IA
-
17 juin 2025L’écosystème de l’intelligence artificielle se structure fortement autour de la mise à disposition en open source de ressources : modèles, jeux de données, librairies. Cela permet à tout un chacun de se saisir – parfois avec des restrictions – de ces ressources, afin de les adapter à des nouveaux besoins (par exemple en affinant les modèles sur des jeux de données spécifiques) et souvent de les mettre à nouveaux à disposition de la communauté. Ce mode de collaboration est sans nul doute à l’origine de très grands succès en IA. Néanmoins, ce foisonnement de modèles et de jeux de données échangés librement pose question vis-à-vis de la protection des données personnelles et leur traçabilité devient un enjeu majeur. Par exemple, dans le cas où les données à caractère personnel d’un individu seraient présentes dans un jeu de données d’entraînement avec des erreurs, comment est-il possible d’identifier les modèles dans lesquels ces données seraient susceptibles d’être contenues ?

Quel est l’objectif de ce projet ?
Afin d’étudier le développement de la communauté de l’IA open source, et de préparer la possibilité d’exercices de droits des citoyens, le projet vise à étudier la base de données des jeux de données et modèles présents sur la plateforme HuggingFace. Cette base de données très riche permet d’établir un arbre généalogique des modèles.
Sur la figure 1, on peut voir un exemple de ruissellement des données d’entrainement d’un modèle dans les modèles engendrés par celui-ci. Si un premier utilisateur publie sur la plateforme un modèle 1 entraîné sur le jeu de données 1 qui contient des données à caractère personnel, un modèle 2 engendré par le modèle 1 (et publié sur la plateforme) sera susceptible de contenir ces données à caractère personnel. Ainsi de suite, le modèle 3 engendré par le modèle 2 sera lui aussi susceptible de contenir ces données.
Afin de permettre l’exercice des droits des citoyens et l’étude de l’écosystème open source, il est donc nécessaire d’avoir une visualisation de la généalogie des modèles présents sur la plateforme HuggingFace.
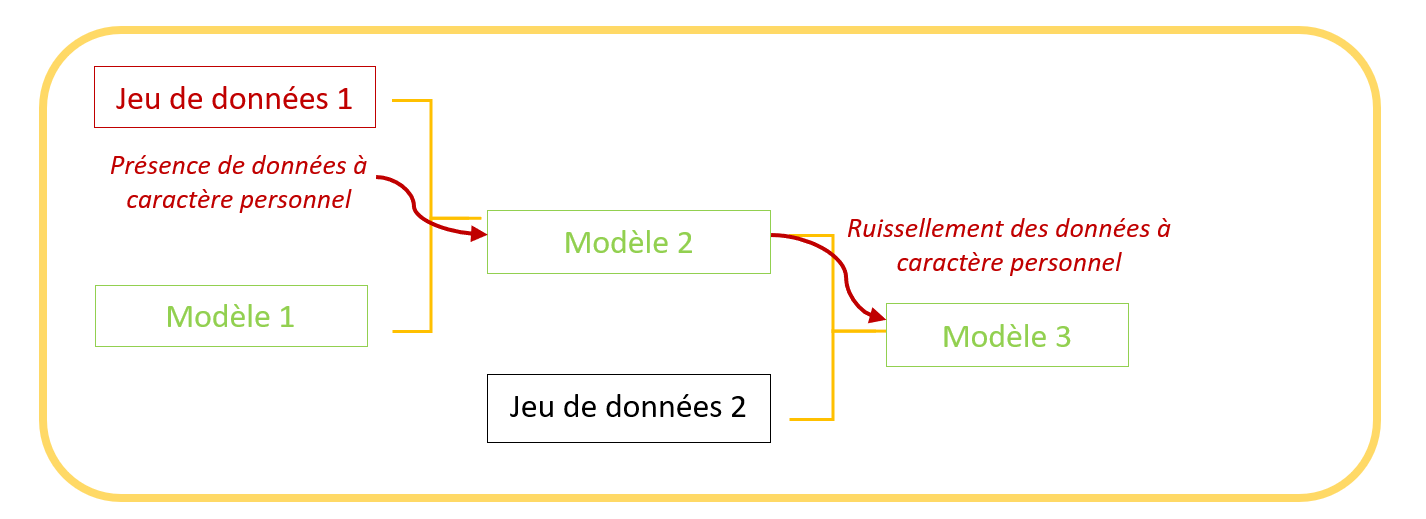
Figure 1 : généalogie de modèles
Quelles données pour quelles utilisations ?
Afin de réaliser ce projet, il nous faut télécharger la base de données présente en accès libre sur la plateforme HuggingFace. Il s’agit de données tabulaires recensant tous les modèles et jeux de données publiés sur la plateforme. Chaque ligne se rapporte à un compte HuggingFace, qui lui-même est détenu, soit par une personne morale (par ex : Microsoft), soit un utilisateur d’HuggingFace (une personne physique). Elle comporte le pseudonyme de l’auteur du modèle/jeu de données, le nom de celui-ci et plusieurs informations inhérentes à un modèle/jeu de données telles que la date de publication, la licence utilisée, le nombre de téléchargements, etc.
Ainsi, chaque ligne de la base qui correspond à une publication par une personne physique constitue une donnée à caractère personnelle, quand bien même nous supprimerions la donnée du pseudonyme (il est possible de réidentifier en allant consulter la base en ligne qui est publiquement accessible). Ces données sont nécessaires pour établir une généalogie des modèles.
Comment les droits des personnes sont-ils respectés ?
Les données utilisées sont manifestement rendues publiques, et ne sont ni sensibles ni hautement personnelles, ainsi, le projet de recherche ne comporte à ce stade pas de risque identifié pour les personnes concernées.
Vous pouvez accéder et obtenir une copie de vos données, vous opposer au traitement de ces données, les faire rectifier ou effacer. Vous disposez également du droit de limiter le traitement de vos données.
Vous pouvez exercer vos droits ou poser vos questions sur ce projet en contactant le service IA de la CNIL : [email protected].
Si vous estimez, après nous avoir contactés, que vos droits « Informatique et Libertés » ne sont pas respectés, vous pouvez contacter le DPO de la CNIL ou adresser une réclamation à votre autorité de protection des données.
Comment ce projet est-il encadré ?
Ce projet relève de la mission d’intérêt public dont est investie la CNIL en application du règlement général sur la protection des données et de la loi Informatique et Libertés modifiée. Il s’inscrit dans la mission d’information de la CNIL telle que définie dans l’article 8.I.1 de la loi Informatique et Libertés mais également dans la mission de suivi de l’évolution des technologies de l’information telle que définie dans l’article 8.I.4.
Seuls les membres du service de l’intelligence artificielle (SIA), en charge de cette étude, auront accès aux données personnelles collectées puis traitées dans le cadre de l’expérimentation, ainsi qu’un chercheur post-doctorant au Medialab de Sciences Po, qui a signé une convention de collaboration avec la CNIL.
Combien de temps durera ce projet ?
Ce projet durera jusqu’en Octobre 2025, sauf nécessité de poursuivre l’expérimentation après information du public. Á l’issue du projet les données traitées seront supprimées.
Illustration : unsplash


