
Data feminism : perspectives féministes sur la protection des données
Rédigé par Assia Wirth
-
23 juin 2021Un nombre grandissant de recherches en sciences sociales et en informatique examinent les injustices raciales et de genre liées aux technologies numériques. Certains travaux tentent par ailleurs de remédier à ces inégalités, en s’appuyant notamment sur les théories féministes intersectionnelles. Ces dernières laissent voir les fragilités structurelles des systèmes actuels de collecte et de traitement des données personnelles.

Inégalités & données personnelles
Les technologies numériques ont, dès leur essor dans les années 60, été associées à un imaginaire émancipatoire de réaffirmation des libertés personnelles. Cependant, il apparait de plus en plus évident que la plupart des technologies qui se sont immiscées dans notre quotidien n’ont pas résolu les inégalités socio-économiques de nos sociétés, mais au contraire ont pu dans certains cas contribuer à les exacerber. Aussi, nombre de personnes militant pour plus de justice sociale ont développé des outils d’analyse pour combattre les manifestations technologiques de ces injustices. En le repensant, le numérique peut alors (enfin) devenir un réel vecteur d’émancipation. De nombreux travaux de chercheuses féministes visent à se réapproprier les technologies de la donnée, en passant par une remise en cause de leur construction et utilisation actuelles.
Les pratiques de collecte et de traitement des données, notamment personnelles, se sont en effet développées au gré d’impératifs politiques et économiques bien précis, qui peuvent encore transparaitre à travers leurs utilisations actuelles. Traiter de ces questions au travers de théories féministes permet non seulement de rendre compte des inégalités liées au genre que ces technologies reproduisent, mais par la même occasion de remettre en question les processus de production et d’utilisation des données personnelles ainsi que la place qu’elles occupent dans nos sociétés.
Data feminism
Ces remises en question sont à la base du féminisme des données revendiqué par les chercheuses Catherine D’Ignazio et Lauren F. Klein, qu’elles exposent dans leur livre, Data Feminism, paru en 2020. Elles y interrogent les sciences des données actuelles au fil d’une réflexion intersectionnelle, qui comme elles le rappellent, permet de repenser les dynamiques de pouvoir régissant l’ordre social, notamment celles agissant à l’intersection des discriminations raciales et de genre. A travers ce prisme intersectionnel, elles développent une critique des connaissances produites par la data science actuelle, en poussant entre autres à sa recontextualisation systématique. Le féminisme des données s’articule autour de sept principes fondamentaux : « examiner le pouvoir, défier le pouvoir, élever l’émotion et l’incarnation, repenser la binarité et les hiérarchies, adopter le pluralisme, tenir compte du contexte, et rendre le travail visible. » Les deux premiers principes remettent en cause le type de données ayant tendance à être récoltées par divers acteurs publics et privés ainsi que leur fonction. L’œuvre de l’artiste Mimi Onuhoa, The Library of Missing Datasets (« Bibliothèque des bases de données manquantes »), y est par exemple présentée, qui répertorie des jeux de données dont l’existence serait pertinente mais qui n’ont jamais été constitués, comme des statistiques sur « les personnes n’étant pas éligibles à des logements sociaux en raison de leur casier judiciaire. » Ces pratiques de quantification sont des formes de collecte de « contre-données » permettant de rendre visible un problème et de se mobiliser pour conduire à sa prise en charge. Par exemple, Maria Salguero recense méthodiquement les cas de féminicides au Mexique à partir de la presse locale et les cartographie (à l’instar du travail de recensement des féminicides réalisé en France par le collectif NousToutes).
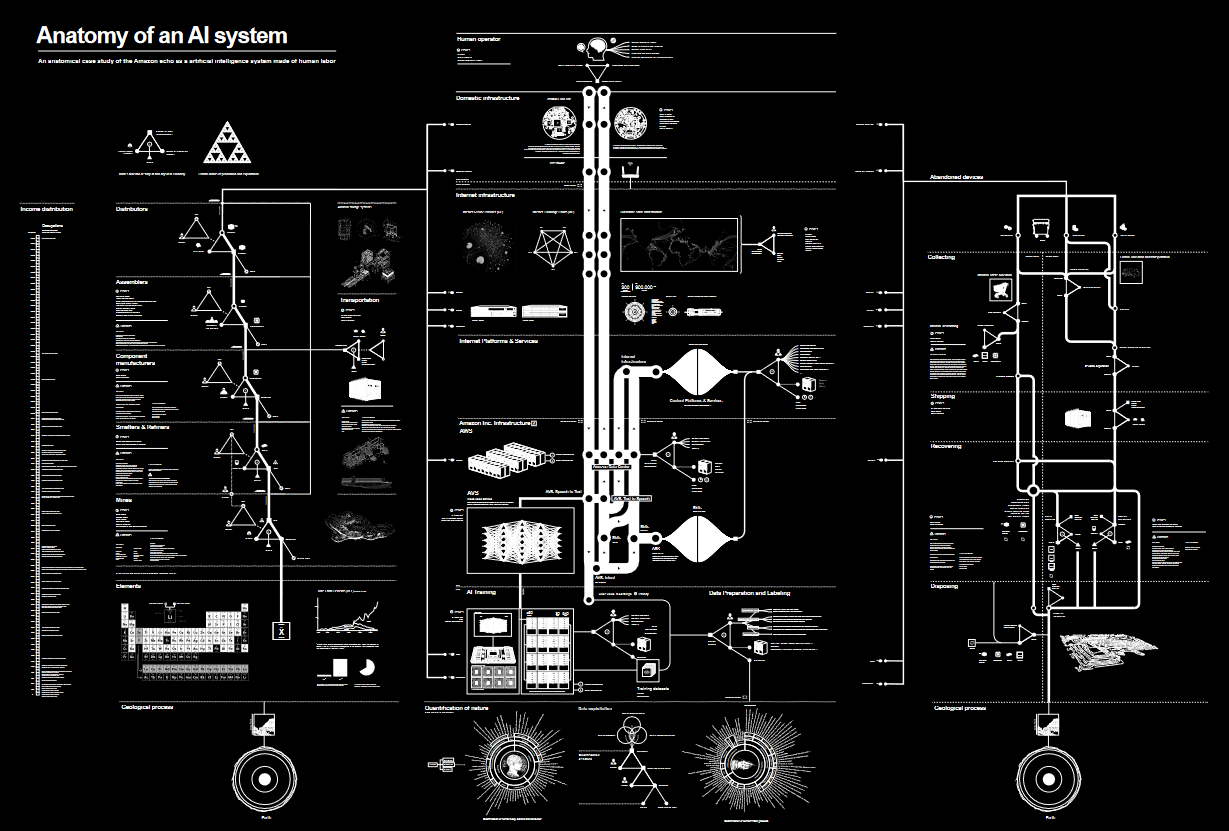
La mise en visibilité du fonctionnement des systèmes de collecte et de traitement des données est également un des principes défendus par le féminisme de données, pour poser les bases de nouvelles pratiques d’utilisation des données, comme par exemple les travaux utilisant des outils de visualisation pour démystifier les procédés opaques d’algorithmes. L’œuvre « Anatomie d’un système d’IA » de Kate Crawford et Vladan Joder, qui décompose tous les composants humains et matériels nécessaires à la production de l’assistant vocal Echo d’Amazon y fait figure d’exemple.
Féminisme des données personnelles
Si D’Ignazio et Klein raisonnent sur les traitements de données en règle générale, leurs travaux ont des implications tout particulièrement intéressantes pour la protection des données personnelles. Ils peuvent entre autres inviter à questionner les données produites par les divers formulaires administratifs. Ces derniers reflètent selon elles un ordre social bien précis qu’ils servent à reproduire. Par exemple, en France, une circulaire du Premier ministre du 21 février 2012, préconisait la suppression des cases « mademoiselle », « nom de jeune fille », « nom d'épouse » et « nom d'époux » de tous les formulaires administratifs, et réaffirmait la demande faite aux administrations, en 1967 et en 1974, de ne pas recourir à l’emploi de certaines formules que ne sauraient constituer un « élément de l’état civil des intéressées ». Si ces préconisations ont été reprises en 2018 dans un guide coécrit par le ministère du travail et celui de l’égalité femmes-hommes à des destination des PME et TPE, on retrouve encore souvent la dénomination Mademoiselle utilisée par des entreprises. Un détail qui pourrait être considéré par certains comme anodin en apparence mais qui renvoie à un imaginaire conservateur où une femme adulte est une femme mariée.

D’Ignazio et Klein remettent aussi en question la binarité, entre autres du genre, au sein des sciences des données. En effet, la binarité formelle est de plus en plus questionnée : près de 15% de la population française entre 18 et 44 ans ne se reconnaitraient pas dans celle-ci, et s’identifient comme non-binaires, genderfluids, non-conformes, etc. L’importance donnée au genre auquel une personne s’identifie plutôt qu’au sexe assigné à la naissance soulève la question de la pertinence du renseignement du « sexe » qui reste la norme pour bon nombre de documents administratifs. Cette dissonance souligne une tension centrale aux débats sur les données personnelles : faudrait-il affiner les catégories de données existantes, comme la ville de New York qui reconnait aujourd’hui par exemple trente-et-un genres différents, ou au contraire ne pas chercher à renseigner le genre, en estimant que sa fluidité ne le rend ni pertinent ni nécessaire comme critère d’identification ?
Cette réflexion va dans le sens des travaux de Caroline Criado Perez, qui dans son livre Invisible Women : Exposing Data Bias in a World Designed for Men remarque les processus d’invisibilisation des femmes par les statistiques dans les domaines dirigés majoritairement par des hommes (soit une grande partie des décisions publiques) qui peuvent leur porter préjudice à divers moments de leur vie. Ainsi, elle démontre par exemple que certaines bases de données constituées et utilisées par diverses organisations à des fins de gestion urbaine peuvent se révéler discriminatoires envers les femmes. Un des premiers exemples proposés par l’autrice concerne les emplois du temps de déneigement d’une commune en Suède. Les responsables, majoritairement masculins, avaient originellement donné la priorité aux voies de circulation utilisées par les voitures, pour ne s’occuper qu’ensuite des zones piétonnes. Or, ces dernières sont principalement utilisées par des femmes, qui en moyenne circulent plus à pied et en transports en commun que les hommes, qui se déplacent majoritairement en voiture. D’un point de vue pratique, il apparait cependant plus simple de circuler dans une zone non-déneigée en voiture plutôt qu’à pied. Les responsables des opérations n’avaient pas pris en compte toutes ces variables, mais avaient simplement mis au point un programme qui correspondaient à leur propre expérience de vie. Cependant, réajuster l’organisation pour déneiger en priorité les zones piétonnes, en plus d’apparaitre comme plus logique, a même mené à des économies, au niveau des frais d’hospitalisation, les cas d’accidents et blessures de piétons causées par la neige ayant considérablement diminué. Ce cas illustre l’importance des données utilisées pour informer tout choix de politique publique, et des conséquences des biais qu’elles peuvent contenir.
Des inégalités automatisées
Les inégalités structurelles que peuvent contenir certaines données apparaissent tout particulièrement problématiques lorsqu’elles deviennent automatisées notamment en servant de base d’entrainement pour des systèmes algorithmiques. En 2018, Amazon avait par exemple été contraint d’abandonner sa solution de ressources humaines automatisée qui privilégiait le recrutement des hommes. Il s’est avéré en effet que le système accordant une certaine importance aux universités des candidats et se basant sur les statistiques des employés d’Amazon, un candidat venant d’une université dont un grand nombre de diplômés avaient déjà rejoint les rangs de l’entreprise se trouvait automatiquement plus avantagé qu’un autre ayant suivi les cours d’une université moins représentée. Or, les États-Unis ayant de nombreuses universités non-mixtes réservées aux femmes, et ces dernières étant historiquement moins représentées notamment dans les rôles les mieux payées, les candidates de ces universités se retrouvaient automatiquement rejetées par le système RH. Non seulement un déséquilibre historique se voyait donc reproduit par le programme, mais l’injustice engendrée par son utilisation ne fut reconnue qu’au bout d’un an d’utilisation. Comme le rappelle un rapport éthique de la CNIL sur le sujet, ces biais sont en grande partie dus aux jeux de données utilisés pour entrainer ces algorithmes, le « caractère historique d’un jeu de données confère à celui-ci la capacité à reproduire des inégalités ou des discriminations préexistantes. » Dans le cas discuté ici, les données de réussite passée d’employées et employés alimentaient ainsi la reproduction d’inégalités de genre au sein des équipes.
Repenser l’automatisation des identités
En outre, les biais statistiques touchent d’autres catégories de classification des identités, comme par exemple la couleur de peau, l’identité de genre ou l’orientation sexuelle. Cette idée est centrale au féminisme des données et son projet de « repenser la binarité et les hiérarchies » ainsi que « d’adopter le pluralisme. » La sociologue Ruha Benjamin évoque par exemple dans son ouvrage Race After Technology le racisme d’un concours de beauté automatisé, Beauty AI, dans lequel les participantes à peau claire sont systématiquement mieux classées que les candidates présentant une peau plus foncée. Les canons de beauté ayant informé la construction du système, par définition discriminatoires, se révèlent alors fondamentalement racistes. Les exemples de systèmes algorithmiques racistes et sexistes sont nombreux : la chercheuse en informatique Joy Buolamwini a démontré dans ses travaux les biais racistes et sexistes de systèmes de reconnaissance faciale largement commercialisés (IBM, Microsoft, et Face ++ ID) ; Safiya Umoja Noble, professeure en sciences de l’information a exploré les biais racistes et sexistes des résultats de recherches d’images du moteur de recherche Search de Google ; et la professeure Kate Crawford et l’artiste Trevor Paglen ont quant à eux exposé les biais raciaux et sexistes structurels d’ImageNet, base de données d’images majeure servant à l’entrainement de beaucoup d’algorithmes de vision computationnelle. Loin d’être des cas isolés, et comme le précisait par exemple le rapport de la CNIL, bien souvent les algorithmes ont pour effet de reproduire des discriminations préexistantes, dès lors que les biais sont intégrés aux données. En juin 2020, à l’issue d’un séminaire réunissant des experts du sujet, Le Défenseur des droits, avec la CNIL, appelaient à une mobilisation collective et publiait des premières recommandations afin de prévenir et lutter contre les biais discriminatoires des algorithmes.
Le féminisme des données fait écho aux diverses formes de « statactivisme » telles qu’elles sont présentées par Isabelle Bruno, Emmanuel Didier et Julien Prévieux dans leur ouvrage éponyme. Sous ce terme s’articulent différentes techniques de visualisation et de traitement des données servant à souligner certaines injustices sociales endémiques aux sociétés subissant une quantification de plus en plus soutenue. Ces deux approches se retrouvent donc dans leur ambition commune de détourner des outils techniques de leurs utilisations les plus répandues, afin de mieux comprendre et « lutter » contre certaines injustices.
En plaçant des concepts comme le genre, la race, ou la sexualité au centre de ses réflexions, le féminisme des données apporte de nouveaux outils pour traiter de ces questions, en même temps qu’il permet à un plus grand nombre d’individus de rendre compte de ses expériences de vie, et ainsi de se réapproprier ses données, personnelles et collectives. Cette approche peut servir à mieux se représenter les dynamiques de pouvoir à l’origine de nos données personnelles, à travers une recontextualisation systématique des productions et traitements de données auxquels nous sommes soumis quotidiennement. Le féminisme des données propose ainsi des réflexions allant dans le sens de certaines pratiques de protection des données personnelles actuelles, notamment en ce qui concerne la transparence et la pertinence de leur collecte. Paradoxalement, il peut être également vu comme contraire à une approche plus frugale de la protection des données, qui aurait plutôt tendance à réduire les types de données collectées : en effet, l’étude de certains biais justifie-t-elle systématiquement la collecte de données sensibles ? Quel encadrement nécessiterait alors cette dernière.

