
"Reduced" sensors : A new perspective toward image capture that is more respectful of individuals’ rights?
Rédigé par Célestin Hernandez
-
28 August 2025Changes in the legal framework governing "augmented" cameras invite to a closer look at cameras’ sensors themselves. This article examines new types of sensors that could provide stronger personal data protection measures, in addition to more "conventional", purely algorithmic approaches.

The Law of 19 May 2023 on the 2024 Olympic and Paralympic Games authorized, for the first time, the use of artificial intelligence in video surveillance for specific use cases. Focused on a nationwide trial of "augmented cameras", the law aims primarily at testing and assessing the ability of algorithms to process surveillance footage more quickly in order to detect certain types of events.
However, artificial intelligence does not (in theory) only make it possible to process "conventional" video surveillance images more efficiently; it can also, in some cases, outperform the human eye, particularly when dealing with "degraded" content (cf. Geirhos and al.). Beyond algorithms designed to process greater volumes of surveillance footage, other AI models can be embedded directly into cameras to minimize the data collected, thereby offering stronger protection for individuals’ rights and freedoms.
Using algorithms to minimize collected data has its limitations (notably, the fact that a non-degraded video stream may still partially exist) which raises the question of whether there can be sensors that are "reduced" by design.
The LINC has therefore explored these "reduced" sensors, examining the opportunities they present, the limitations encountered, and their potential impact on the very definition of what constitutes a "camera".
Augmented cameras, GDPR, and data minimization
By the way, what exactly is an augmented camera?
The concepts of so-called "intelligent" or "augmented" cameras encompass a wide range of uses in the field of image analysis (also known as "computer vision").
An augmented camera is a conventional video device (as defined below) enhanced with software that can automatically analyse images to detect for example, shapes or objects, track movements, identify events, and more. Unlike conventional cameras, these systems do not simply record footage; they analyse individuals in real time, continuously processing certain information about them.
These devices can be deployed in a wide variety of contexts and use cases, by both public and private actors. They offer several technical advantages : on the one hand, they make it possible to automate the use of images captured by cameras, which is still most often performed by humans (it becomes possible to process video streams from multiple cameras simultaneously without requiring the presence of a human operator) ; on the other hand, they provide an analytical capacity for certain parameters that the human eye could not achieve (although the human eye retains a relative advantage in adaptability and contextualizing the viewed content ; computer vision outperforms in terms of speed and precision for complex tasks, such as estimating speed or detecting crowd movement). In doing so, they make it possible to enhance the value of existing camera networks.
Minimization?
Under the GDPR, the principle of data minimization requires that personal data be adequate, relevant, and limited to what is necessary for the purposes for which they are processed.
Applying this principle can be challenging when dealing with continuous data collection, especially when the information captured can vary significantly from one frame to another, as can the purposes of the processing. In video surveillance, minimization is often embodied in a strict prohibition on filming inside residential buildings. Some rules, however, may be assessed case by case depending on the intended purposes (for instance, the prohibition on filming inside a school cafeteria may be subject to an exemption). These remain broad principles and do not necessarily address the more technical aspects of what constitutes effective data minimization.
In any event, it is essential to recognize the significant paradigm shift introduced by computer vision technologies.
Editor’s note – Reminder:
- Video protection systems capture footage of public spaces and areas open to the public, such as streets, train stations, shopping centres, commercial districts, and swimming pools, etc.
- Video surveillance systems capture footage of private areas not open to the public, such as stockrooms, warehouses, or gated residential properties, etc.
Minimizing data collected by "conventional" cameras
It is generally possible to minimize data collected by a camera by tailoring the capture process to the intended purposes. To do this effectively, it is first important to understand how a camera operates in order to identify realistic minimization options.
What is a "conventional" camera?
A camera captures and records moving images by using an electronic sensor that converts light information into an electrical signal.
It is made up of two main components:
- The lens, which works similarly to the pupil of an eye, controlling the amount of light entering the camera and focusing it onto a sharp focal point.
- The sensor, which then collects this concentrated light and converts its intensity and color variations into a digital signal that becomes the image.
Repeating these operations in sequence (at a set capture frequency) produces a video. Certain technical, hardware, or organizational measures can then be considered to limit the data collected.
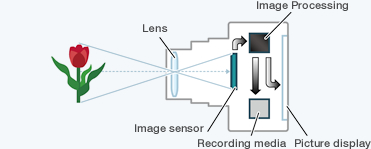
Fig 1: Basic mechanism of a camera (source)
Recommended hardware measures
DORI (Detection, Observation, Recognition, and Identification)
One important principle in assessing the data collected in video surveillance is DORI, which stands for Detection, Observation, Recognition, and Identification. This principle theoretically helps determine the minimum resolution needed to achieve the desired objective among these four levels of DORI.
It establishes objective criteria to overcome the physical differences between cameras of various brands and models. Indeed, numerous variables affect the image quality produced by cameras and, consequently, the purposes they can fulfil. Some of these variables are simple and measurable, but many are not. Likewise, some are controllable, while others are not.
The DORI principle can specify a minimum PPM (Pixels Per Meter) for the different tasks of detection, observation, recognition, and identification. This PPM is calculated (regardless of brand, model, etc.) as follows:
PPM = Resolution (horizontal or vertical; in pixels) ÷ Field of view (horizontal or vertical; in meters)
According to standardization organizations (the International Electrotechnical Commission (IEC), the European Committee for Electrotechnical Standardization (CENELEC), and the British Standards Institution (BSI)) the PPM thresholds for various tasks are as follows :
- Detection: 25 PPM. At this level, the viewer can determine the presence of a vehicle and a person in the image, although few details are visible for the person.
- Observation: 62 PPM. At this level, some characteristics of the individual can be discerned (such as clothing).
- Recognition: 125 PPM. Here, it is possible with a good degree of confidence to potentially re-identify the individual ; details such as license plates may become usable under certain conditions.
- Identification: 250 PPM. It is possible to identify the person with a high degree of confidence, and details are clear enough to read license plates easily.

Fig 2: Illustrated Evolution of the PPM Metric for Detection, Observation, Recognition, and Identification (source)
The reflexion around the chosen resolution can also be done for other technical aspects of the sensor:
- Frame rate: Estimates vary, but generally the frame rate can be reduced to 10 to 12 frames per second (for large-scale outdoor scenes, such as intrusion detection) and increased to 30 to 60 frames per second (for indoor use, such as recognition and tracking).
- The very necessity of using a camera, which will be discussed in more detail below.
It should be noted that the DORI principle can be, most of the time, applied to all the sensors presented below. An appendix detailing the calculation methods for this principle is available at the end of the article.
Refined sensor numbers and positioning
Reasoning based on the DORI framework is a good starting point to achieve objectives while minimizing data collection as much as possible. However, in most use cases, the objectives are not achieved with a single sensor but rather with an entire network of cameras.
Therefore, it is important to consider, in addition to the sensor’s resolution, the challenges of optimizing both the number and positioning of cameras to meet a specific objective.
Overall, regarding these optimization issues, the literature (including Wu et al, Costa et al) is able to define metrics that allow an objective evaluation of the minimum number of sensors, their specific orientations for a given area, as well as given obstruction constraints.
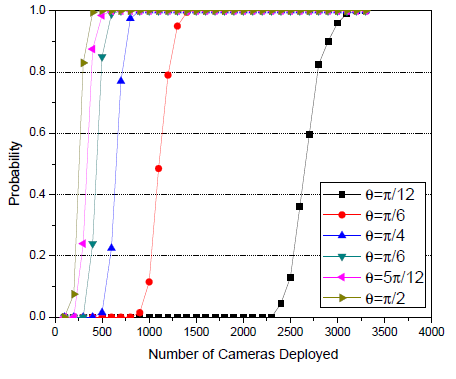
Fig 3: Wang et al. Illustrations of the Minimal Number of Cameras Required to Cover a 100m-Long Border, According to Positioning Angle.
Wang et al. present, for example, a probabilistic system to optimize the number of cameras needed to cover a separation zone (the objective here being to determine the minimum number of cameras required to detect an intruder within a limited area).
These optimization considerations are primarily aimed at cost reduction ; however, the reasoning can also help determine a minimal number of sensors to achieve a minimization objective.
Therefore, although these metrics should be considered when setting up a camera network for minimization purposes, their applicability can be challenging due to:
- The variety of use cases and the diversity of objectives pursued, which dictate different constraints that are difficult to generalize in mathematical calculations;
- The need for a “broad-enough” field of view to allow proper training, acceptable performance, and good generalization (among other factors);
- Finnaly, most studies focus on « classical » camera placements without evaluating less common viewing angles (such as ceiling-mounted cameras filming the floor), which can also be interesting from a minimization perspective.
Short-term and local minimization
Degradation of the stream
The previously mentioned use cases suggest, first and foremost, that it is not absolutely necessary for AI to use the entirety of the images captured by a camera:
- To detect abandoned objects, the notion of abandonment implies that only the object itself and a limited surrounding area would be sufficient for detection;
- For crossing or presence within a restricted or sensitive zone, only the relevant area appears important to consider. The mere presence in this area can justify a detection of crossing (in most cases).
Moreover, to simply detect the presence of a person or object, it would seem relatively relevant not to focus on details such as faces or clothing, for example.
The possible processing techniques that could be implemented include:
- Localized blurring, or replacing faces with synthetic data : He et al notably demonstrate comparable object detection performance with blurred or replaced faces (both during training and inference).

Fig 4: Different degraded versions of the same image according to He et al.
- "Outlining", for example, as done by OpenPose, detects bodies present in an image and then converts them into silhouettes. Hur et al. propose detecting and tracking people using their silhouettes in a fairly constrained environment: a classroom. The results show good re-identification performance and suggest that silhouettes may be sufficient, particularly for tasks such as person detection, counting, etc.

Fig 5: Example of an output provided by OpenPose (source)
Editor’s note: OpenPose is a pose estimation system developed by researchers at Carnegie Mellon University (CMU) capable of detecting and tracking the human body in real time and accurately determining its pose in 3D space.
It should be noted that the examples of minimization measures mentioned above involve detecting a face or silhouette upstream of the algorithmic processing aimed at the purpose. It is therefore necessary to evaluate the benefit-risk balance of such manipulation.
- Image obfuscation: Coninck et al. propose degrading the image into an unusable and non-reversible form while still ensuring adequate person detection performance.
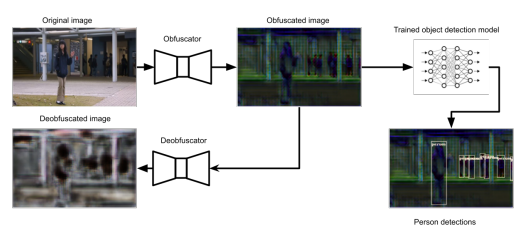
Fig 6: Illustration of the obfuscation model: the image is degraded, and an algorithm verifies that the obfuscation cannot be reversed before proceeding with detection.
Reduction and operational protection
Beyond video stream degradation processes, other more operational recommendations can be implemented to ensure further data minimization, as long as this is compatible with the pursued objectives:
- Not allowing the video stream to be replayed, but only the sought alert, thereby restricting the existence of the video stream for control purposes (alert control and validation);
- Limiting detection tasks to areas different from those containing the most personal data : Tian et al. for example, demonstrated that for detecting abandoned objects, tracking and detecting "classic" objects did not work sufficiently well in crowded areas with many people and other objects ; the importance here lies in variations observed only in the background (an abandoned object is by definition static);
- Performing algorithmic operations locally, directly on the video device, to limit data copies (Rodriguez et al.);
- Finally, strengthening the security of the video stream through homomorphic encryption of the video stream (Jia et al.) and detection on encrypted or degraded data.
Minimized data but still a lot of information!
Re-identification still possible
The major challenge for short-term and local minimization is that it assumes the existence (even if as brief as possible) of the original, unaltered video stream. By maximizing operational security procedures, the risk of access to these unaltered images is easier to control. However, the possible existence of a conventional video system alongside augmented cameras reduces the benefits of efforts made to minimize data.
Moreover, degradations (regardless of the types of sensors used, as presented below), no matter how advanced, do not make the resulting images anonymous:
- In case an unperturbed stream is available;
- Due to the possibility of reversing a degradation process:
- removal of added blur or noise (Sun et al.);
- reconstruction of obscured content (McPherson et al.);
- partial re-identification based on a person’s posture (Liu et al.);
- And when the operator can intervene directly with a filmed person, which makes them identifiable by default.
Operational complexity
Reduction measures also lead to more operational challenges. Indeed, adding reduction measures (through additional algorithmic processing as discussed above) can hinder detection performance by reducing accuracy or increasing processing time. Moreover, the state of the art on this topic is limited, unlike that for detection on "classic" video streams. Consequently, training datasets and specific AI models may be less common.
Finally, reduction pre-processing does not prevent augmented cameras from being exposed to attacks. Examples include patterns that prevent human detection (Thys et al. et Xu et al.), or that directly disrupt neural networks (Liu et al. et Mohamad Nezami et al.). Indeed, reduction operations can be seen as increasing the attack surface, opening up relatively unexplored considerations : notably Shah et al (It is worth noting that « stream degradation » can sometimes also be considered as providing robustness against certain attacks, notably evasion attacks).
New sensors and minimization at the source?
While short-term and local minimization offers good perspectives for minimisation, it is not the only possibility to consider. Indeed, other types of sensors can address use cases for which cameras (augmented or not) are employed. These sensors may provide data minimization directly "at the source” by limiting the risks mentioned above.
A first distinction within this family of sensors is between "passive" and "active" sensors. A conventional camera is a passive sensor in the sense that it receives information (light, as we saw earlier) which its sensor can convert into a physical measurement and digital data. Active sensors, which we will discuss next, emit a signal or information and then capture and interpret the returned signal (echo, reflection, etc.).
"Passive" sensors
Infrared cameras / thermal cameras
Infrared or thermal cameras (since they are actually similar) differ from a conventional camera in the type of sensor they use. This sensor is no longer sensitive to visible light but to infrared radiation ; which associates a temperature to a light intensity.

Fig 7: Example of an image captured by a thermal camera
The resulting image from a thermal camera provides additional information (such as the potential temperature of a person, which can help to more easily confirm human presence compared to a conventional camera) but generally produces an image that is less interpretable for the human eye.
It is worth noting that thermal cameras may also be subject to the DORI principle in a slightly different way than what is applied to "conventional" cameras.
Referring to military applications that take into account the resolution limitations previously mentioned, the principle here is expressed as DRI : Detection, Recognition, and Identification (which differs from the identification presented earlier ; here it simply means distinguishing, for example, whether a human already recognized is wearing a helmet or not).
The prospect of using thermal cameras has already been explored for tasks such as person detection, tracking, and sometimes object detection, with performance levels approaching those of conventional sensors. (see Batchuluun et al. and Krišto et al.)
Since these sensors generally protect individuals’ identities more than classical cameras, their use can thus contribute to a data minimization approach.
Event-based cameras
Event-based or neuromorphic cameras also differ in the type of sensor they use. Unlike conventional or thermal cameras, these sensors attempt to mimic the way the human eye works, particularly its asynchronous nature.
A conventional camera captures images at regular intervals ; each image, composed of pixels, is a snapshot of a scene and represents the overall brightness of that scene at a given moment. In contrast, a neuromorphic camera captures "events" (that is, asynchronous changes in brightness at the level of individual pixels) rather than a complete image.
The data produced by a classical camera can be represented as a grid showing the brightness value captured for each pixel. For neuromorphic cameras, the collected data represents only the pixel(s) involved in an event.
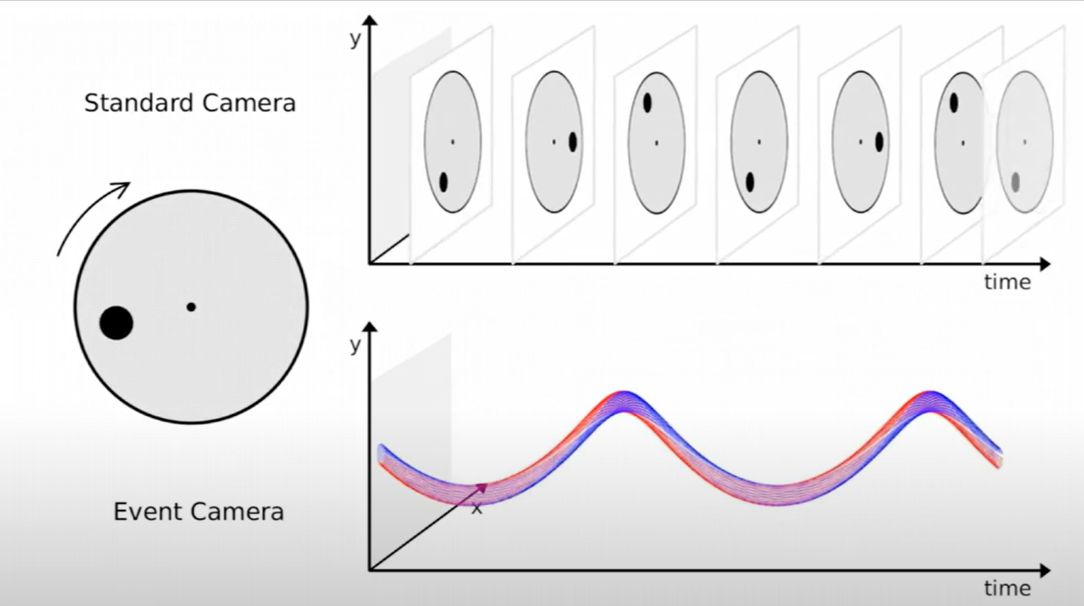
Fig 11: Illustration of what is captured by a conventional camera (top) and a neuromorphic camera (bottom) for a moving object (source)
The circle on the left is rotating, and the conventional camera captures images at regular intervals. The neuromorphic sensor, on the other hand, captures and locates the changes in brightness caused by the rotation.
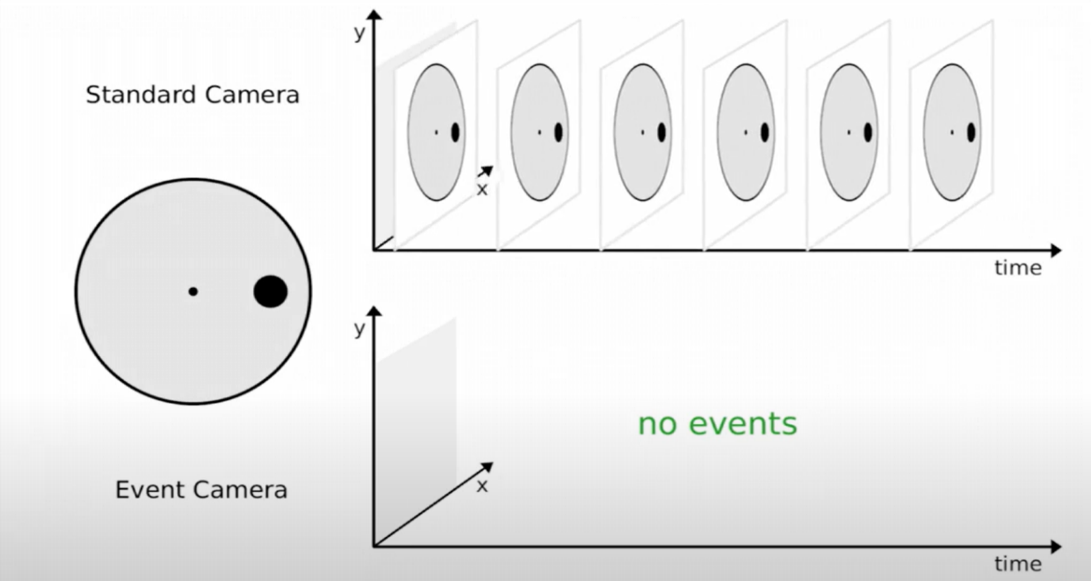
Image 12: Illustration of what is captured by a conventional camera (top) and a neuromorphic camera (bottom) for a static object
The circle on the left is no longer rotating, and the conventional camera continues to capture images at regular intervals. The neuromorphic sensor, no longer detecting any local changes in brightness, captures absolutely nothing.
Neuromorphic sensors thus produce an image that traces the movement of an object while omitting certain elements captured by conventional cameras (such as colors, precise shapes, etc.). It should be noted that the level of precision of these cameras can still make it possible to identify people when they move close to the sensor.

Fig 13: Illustration of what is captured by a conventional camera (left) and a neuromorphic camera (right) (source)
Neuromorphic sensors, although relatively recent, have already been studied for object and person detection and tracking tasks with relatively good performance levels. (for example Liu et al.)
Active sensors
Active sensors, as mentioned earlier, must emit a signal in order to collect information, in the same way that a bat uses echolocation to map the nocturnal landscape it tries to navigate.
LIDAR (Detection and distance estimation by means of light)

Fig 14: Example of a 3D point cloud that a LIDAR is capable of capturing (source)
LIDAR, an acronym for "Light Detection and Ranging", is a sensor designed to determine the distances between itself and objects in a scene by emitting a light signal (using a laser) and measuring the time it takes for the signal to return to its origin. By doing so, it produces a map (often used in fields such as geology, but also aboard the ISS to determine the height and structure of vegetation in a canopy). These sensors often consist of multiple emitters, allowing for a more accurate and detailed rendering, thus enabling a more "deeply exploitable" 3D mapping.
LIDARs can be used for detecting and tracking people or objects, even though they do not provide as detailed a representation as conventional sensors.
TOF (time of flight)
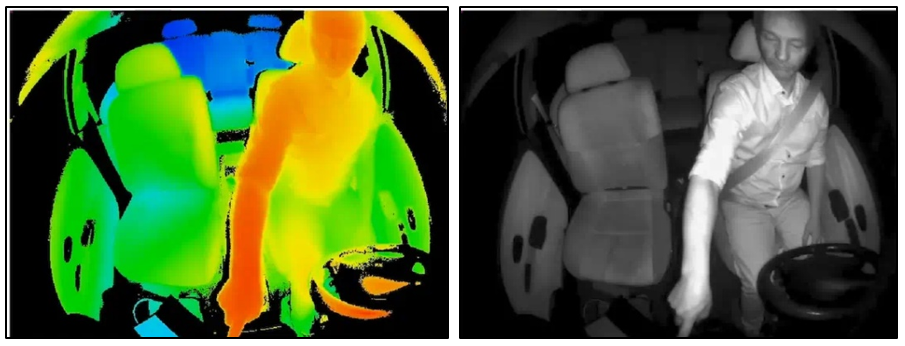
Fig 15: Illustration of what is captured by a TOF sensor (on the left) and a conventional camera (on the right) (source)
TOF sensors, or time of flight, operate in a similar way to LIDAR sensors (which are more widely used). TOF sensors equipped with a laser emitter are, by the way, considered part of the LIDAR family. The distinction is made primarily based on the intended use cases for each type of sensor.
Time-of-flight (TOF) devices have been used for civilian applications since the 2000s. They are notably employed in smartphone cameras to enhance image quality (particularly in « portrait » modes) and also in the field of robotics. These sensors are lightweight, efficient, and enable embedded systems to quickly and reliably generate visual representations such as spatial maps for obstacle detection in devices like robotic vacuum cleaners.
Beyond these applications, it is worth noting that TOF sensors are already being considered in research for intelligent video use cases, including :
- detection and estimation of people flow based on TOF capture;
- object detection and classification
Advantages of minimization at the source
General advantages
For all the sensors presented so far, we have observed that:
- Scientific literature describes situations where these sensors are used to detect events such as the presence of abandoned objects, human presence, or to measure crowd density, with performance levels that can initially be considered "satisfactory";
- These sensors produce visual representations that differ from those produced by a conventional camera. They can be considered "reduced" in the sense that they contain less visual information directly usable (even though LIDAR and thermal sensors, for example, provide additional information such as temperature or distance), particularly for a human observer;
- These sensors reduce the data collected without relying on algorithmic processing, meaning there is no "clear" version of the undegraded feed since it is never captured in the first place. These sensors therefore avoid collecting unnecessary information when the intended purpose does not require "conventional" representations.
But also sensor-specific benefits
Beyond these general advantages, it should be noted that:
- For LIDAR:
- The computing power required to process a 3D point cloud is lower than that needed for a conventional video feed;
- The ability to obtain depth information can help overcome certain limitations of detection in conventional images. Depth data also makes it possible to set detection thresholds (for example, by excluding distances that are too short or too long);
- For event-based cameras:
- These devices inherently consume and store less data (since the absence of events means there is nothing to record),

Fig 16: Example of an Incorrect Detection by an Algorithm on a Conventional Image (The advertisement is identified as a pedestrian)
- they perform better in scenarios that are sometimes less well supported by conventional sensors (such as crowd movements ; indeed, neuromorphic cameras are less susceptible to blur since they have a much higher temporal resolution than a conventional camera).
But these solutions are not without risks either
These relative gains must nevertheless be put into perspective with their risks or limitations.
- The previously mentioned attacks can also be implemented against other sensors :
- Use of reflective objects for adversarial attacks on a LIDAR sensor, disrupting object detection ;
- Use of a spoofing device (light emitter) to falsify LIDAR detections ;
- Disruption of the collected event stream to mislead the detector ;
- « Bypassing » reduction : for example, reconstructing an image based on an event stream.
These attacks, although comparable (adversarial presentations) to those used against conventional sensors, differ in that uncertainty resolution by a human operator is not as straightforward as with a conventional image. For example, it is difficult in a 3D point cloud or in pixel motion data to determine whether the displayed information has been altered by an attacker or is revealing an unknown type of event…
These sensors also do not remove the need for the minimization and operational/technical security considerations already presented above, since they do not always produce intrinsically anonymous data (the assessment of anonymity must be made on a case-by-case basis and depending on the specific use cases).
And a more difficult generalization to consider
Beyond the issues of exposure to attacks, it should be noted that "reduced" sensors, as presented, impose operational constraints that may slow down their adoption.
Indeed, the dominance of conventional cameras suggests a difficult transition toward new sensors, especially considering that these :
- Do not benefit from research investment as significant as that for conventional cameras (particularly in terms of algorithms, since those enabling detection, for example, are specific to the nature of the data and thus cannot be trivially transferred from one sensor to another. The same applies to datasets and research communities);
- Do not guarantee the absence of personal data collection (even if they do, compared to cameras, effectively minimize the data collected);
- And finally, most of these sensors remain, at present, more expensive per unit than cameras.
Lastly, why a camera?
Considering the developments in artificial intelligence and its capabilities, it is important to ask whether the issue of data minimization with video sensors stems from an overly anthropomorphic view of computer vision. Indeed, while it makes sense to design an interface as human-like as possible when it is meant for direct communication with a person, one should question whether a computer truly needs to « see » like we do in order to detect what we want it to detect. Just as a motor vehicle has little in common technically and organically with a marathon runner, why should a sensor intended solely for automated detection imitate the human eye ? Some autonomous vehicles have already abandoned cameras altogether in favor of LIDAR, and robots or embedded sensors in our homes are increasingly equipped with a more reduced form of vision.
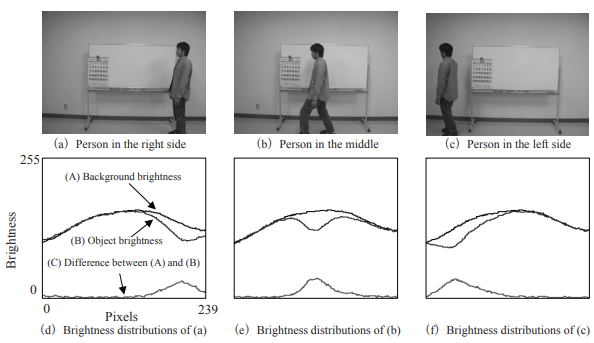
Fig 17: Visualization of the presence or absence of a person and their location in the image through the simple changes in the brightness distribution. (Source)

Image 18: Comparison between the view of a « conventional » camera and that which can be used by household robots, for example. The degradation is not done algorithmically but directly at the sensor level. (source)
Lewis Mumford, an advocate for more sustainable technology, writes in his book Technics and Civilization that "the most inefficient type of machine is the realistic mechanical imitation of a man or another animal".
However, demanding that technology be as minimalist as possible may exclude the possibility for a human to review what "the machine" has decided or thought it saw. It is necessary to balance the principle of minimization with the need for transparency (and thus explainability), which implies being able to account for automated processes and their results.
In any case, it is important to consider by what means we would accept being detected, observed, and potentially judged. Even if cameras are not always where we think they are, or exactly what we think they are (Liu et al. notably demonstrate the feasibility of reconstructing images from a tablet’s proximity sensor, which is a single-pixel resolution sensor).
The prospects for evolution are numerous and may eventually bring about technology that is more minimalist and less organic.
Illustration (top of page) : Pixabay, revisited.

