
Open source AI project - Genealogy of models and database on the Hugging Face platform
Rédigé par Nicolas Berkouk, Expert Scientifique IA et Anna Charles, Stagiaire IA
-
30 June 2025The artificial intelligence ecosystem is strongly structured around open source resources : models, datasets and librairies. This allows anyone to use these resources – sometimes with restrictions – to adapt them to new needs (for example, by fine-tuning models on specific datasets) and often to make them available to the community once again. This mode of collaboration is undoubtedly at the root of some of AI’s greatest successes. Nevertheless, this proliferation of freely exchanged models and datasets raises questions about the protection of personal data, and their traceability is becoming a major issue. For example, if an individual’s personnal data is present in a training dataset with errors, how can we identify the models in which the data might be contained ?

What is the goal of this project ?
In order to study the development of the open source AI community, and to prepare for the possibility for citizens to exercice their rights, the project aims to study the datasets and models present on the Hugging Face platform. This database enables us to establish a family tree of models.
Figure 1 shows an example of the trickle-down effect of a model’s training data into the models it generates. If a first user publishes on the platform a model 1 trained on dataset 1 that contains personnal data, a model 2 generated by model 1 (and published on the platform) is likely to contain this personal data. And so on, the model 3 generated by model 2 will also be likely to contain this data.
To enable the exercise of rights and the study of the open source ecosystem, it is therefore necessary to have a visualization of the genealogy of the models present on the Hugging Face platform.
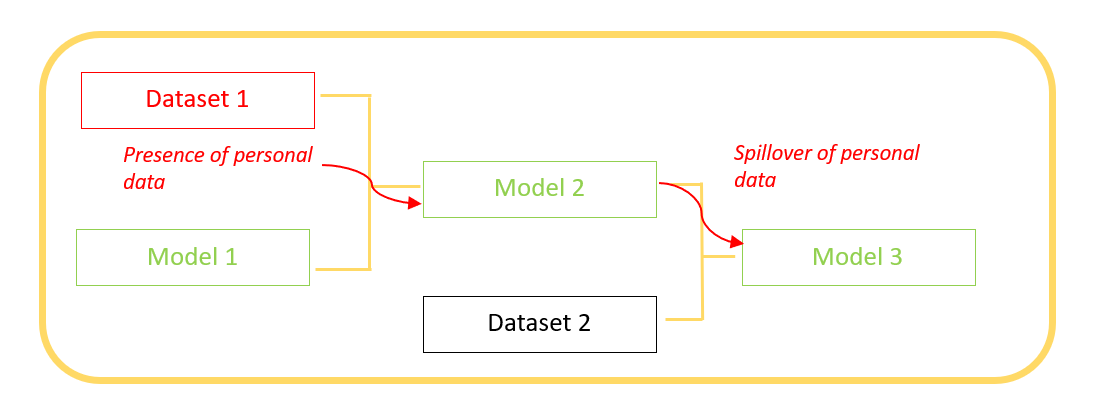
Figure 1 : The genealogy of models
What data for what uses ?
In order to carry out this project, we need to download the open-acess database on the Hugging Face platform. This is a tabular database listing all the models and datasets published on the platform. Each line refers to a Hugging Face user (an individual). It includes the pseudonym of the author of the model/dataset, the author’s name and various information inherent to a model/dataset, such as the publication date, the licence used, the number of downloads, and so on.
Each line in the database corresponding to a publication by an individual is therefore a personal data, even if we delete the pseudonym data (it is possible to re-identify by consulting the online database, which is publicly accessible). This is necessary to establish a model genealogy.
How are people’s rights respected ?
The data used is clearly made public, and is neither sensitive nor highly personal, so at this stage the research project does not involve any identified risk for the people concerned.
You have the right to access and obtain a copy of your data, to object to its processing, and to have it corrected or deleted. You also have the right to restrict the processing of your data.
You can execise your rights or ask questions about this project by contacting the CNIL’s IA department : [email protected].
If, after having contacted us, you feel that your « Informatique et Libertés » rights have not been respected you can contact the CNIL’s DPO or lodge a complaint with your data protection authority.
How is this project managed ?
This project falls within the scope of the public interest mission entrusted to the CNIL under the General Data Protection Regulation and the amended Data Protection Act, as well as its missions to monitor developments in information technology, as defined in article 8.I.4.
Only members of the Artifical Intelligence Department (SIA), in charge of this study, will have access to the personnal data collected and processed as part of the experiment, as well as a post-doctoral researcher at Sciences Po’s Medialab, who has signed a collaboration agreement with the CNIL.
How long will this project last ?
This project will last until October 2025, unless it becomes necessary to continue the experiment after the public has been informed. At the end of the project, the processed data will be deleted.
Illustration : unsplash

