
GeoTrouveTous - projet de réidentification par géolocalisation
Rédigé par Romain Pialat
-
14 June 2023Dans cet article, nous revenons sur le projet de réidentification par géolocalisation, commencé au LINC en 2022 et terminé en 2023, prouvant qu'une réidentification quasi-automatique d'individus peut être réalisée à partir de données récupérées chez des courtiers en données (data-brokers), sans aucune contrainte ou vérification.
Cet article fait suite de l’étude faite par Cyril Miras lors de l’été 2022, qui a développé une partie des algorithmes utilisés ici.
Un peu de contexte
Où étiez-vous le 10 octobre 2021 ? Cette question peut sembler peu intéressante. Mais si je vous disais que je sais exactement où vous étiez le 10 octobre 2021, où vous avez mangé, chez qui vous êtes allé, l’heure à laquelle vous vous êtes levé et quand est-ce que vous êtes rentré, tout de suite le malaise s'installe. Bienvenue dans le monde merveilleux de la géolocalisation, des courtiers en données, des algorithmes de partitionnement de données (data clustering) et de la recherche en sources ouvertes.
Depuis maintenant quelques temps, on entend l'expression de nouvel or noir pour qualifier les données numériques. À l'ère des « données massives » (Big Data), notre système repose essentiellement sur ces collectes massives de données personnelles pour alimenter des algorithmes, permettant une aide à la décision toujours plus précise. Que ce soit pour un modèle d'apprentissage machine dans le domaine de la santé, ou pour un algorithme de ciblage publicitaire, plus il y a de données, mieux c'est !
Nos données, collectées un peu partout grâce aux cookies ou aux autorisations que l'on donne à des applications mobiles sans nécessairement prendre le temps de les lire, font des heureux... Leur revente est un vrai marché, où des courtiers en données permettent – parfois à n'importe qui – de se procurer vos informations pour des usages non-anticipés.
En constatant que des journalistes avaient réussi à trouver les données de géolocalisation d'un prêtre et à prouver qu’il fréquentait des bars gay [lien], le LINC s'est demandé [lien] comment de telles données, qui paraissent sensibles, avaient pu se retrouver en « liberté ». Serait-il possible de récupérer un échantillon de données de géolocalisation basées en France ? De reproduire l'expérience de réidentification ? À quel coût et sur quelle base légale ?
En retraçant le fil des évènements, nous verrons qu’il est possible de réidentifier de manière massive des personnes et ainsi de pénétrer dans leur intimité sans qu’elles en aient conscience.
« Every move you make, Every bond you break, Every step you take, I'll be watching you. »
– The Police
Récupération des données
En cherchant comment récupérer des données de géolocalisation, il s'est avéré assez rapidement que le plus prometteur était de se tourner vers les courtiers en données.
En faisant des recherches en ligne sur une plateforme permettant à différents data brokers de mettre en vente leurs jeux de données, une base nous est apparue plus fournie que les autres, en particulier pour les données de personnes localisées en France. On pouvait lire dans la description qu'il s'agissait de données anonymisées de géolocalisation et qu'il était possible d’avoir un échantillon gratuit. Il faut compter environ quelques milliers d'euros par mois ou plus d’une centaine de milliers d’euros par an en fonction des utilisations et des zones géographiques visées, un prix parfois dérisoire comparé aux bénéfices qui peuvent être engrangés grâce à ces données.
|
Le MAID est un identifiant unique de votre appareil mobile, permettant aux publicitaires de savoir quel profil vous associer, et ainsi vous proposer du contenu ciblé. Il est possible de réinitialiser son MAID en un nouvel identifiant unique, et ainsi éviter le traçage de votre appareil en ligne. |
Outre ces données, qui vont principalement nous intéresser dans cet article, on retrouve pour chaque ligne des adresses IP, un indicateur du pays et de la ville dans lesquels se trouvent le point de géolocalisation, une mesure de la précision sur la localisation de l'appareil au moment du relevé de la position, et d'autres données moins importantes.
La base de données ainsi composée fait environ 15 Go, pour 100 millions de lignes, base qu'il va donc falloir nettoyer et retrier pour pouvoir la traiter.
|
Parenthèse sécurité Afin d’assurer la sécurité des données et d’assurer, en cas de réidentification, la conformité de nos traitements la législation sur la protection des données personnelles, un serveur de calcul chiffré a été mis en place pour stocker le jeu de données. Ce dernier n’est accessible que par les personnels du LINC en charge de l’étude. Par ailleurs, nous avons communiqué en début du projet pour permettre aux personnes d’exercer leurs droits. |
Traitement
Dans le cadre du tri des données récoltées, une répartition en plusieurs colonnes a été effectuée afin d’isoler les données utiles pour la conduite du projet. En utilisant Python et des Jupyter Notebook avec le module Pandas, nous avons pu procéder à un premier tamisage en retirant ce qui n’allait pas être utilisable pour notre méthode de réidentification.
Nous ne voulions conserver que les points de géolocalisation, le temps auquel le point a été enregistré ainsi que l’identifiant permettant de relier chaque ligne à un téléphone portable.
Une rapide vérification nous a permis de constater qu’il y avait 5 millions d’identifiants uniques dans notre base de données. Donc potentiellement 5 millions de téléphones « tracés », certains avec beaucoup de points différents, d’autres très peu, voir un seul. En éliminant ces derniers de notre base de données de « téléphones exploitables », il restait environ 800 000 identifiants à utiliser.
Nous avons ensuite regroupé les données par identifiant unique et ainsi construit 800 000 ensembles de données distincts, chacun retraçant le parcours d’un téléphone. Nous appelons une telle suite de points une « trace ».
Des données fiables ?
En regardant la répartition des points et le nombre total de traces, la première question qui vient est celle de savoir si ce sont de vrais points de géolocalisation ou s’ils ont été générés aléatoirement plus ou moins sur la même zone géographique. En recherchant des évènements publics ayant eu lieu sur la semaine du 8 au 15 octobre 2021, on trouve rapidement le 20km de Paris, qui s’est déroulé le dimanche 10. On constate bien des concordances entres le tracé de la course et certaines traces de téléphones dans notre jeu de données, ce qui a permis de confirmer la probable fiabilité des données de l’échantillon.
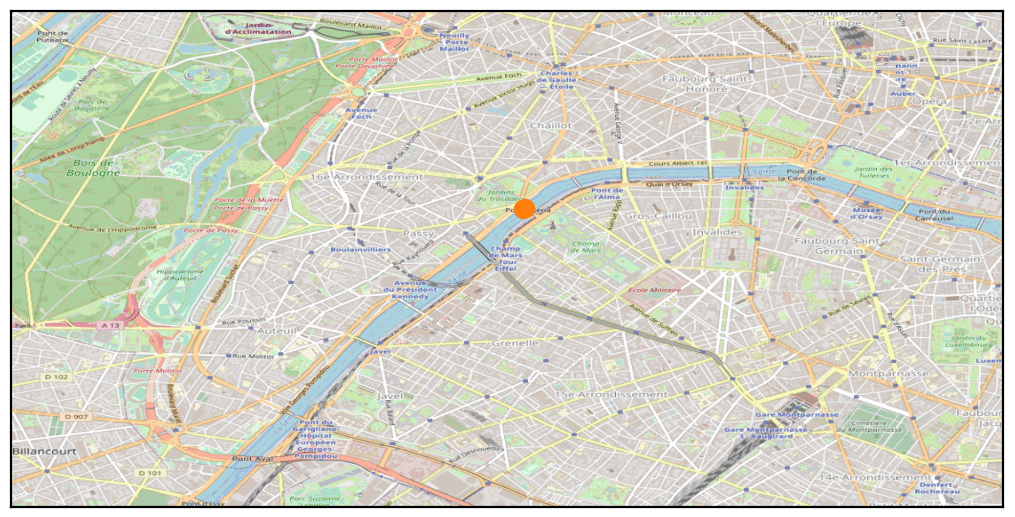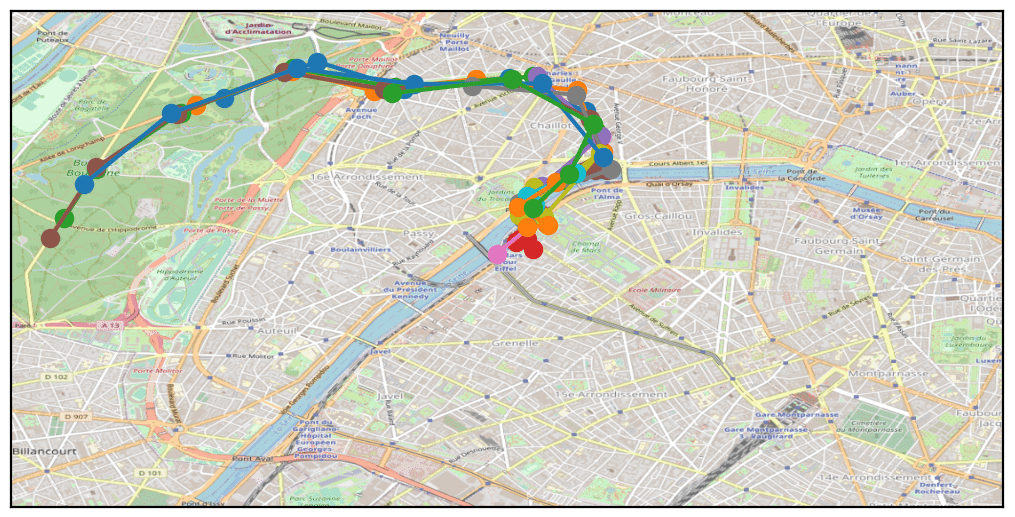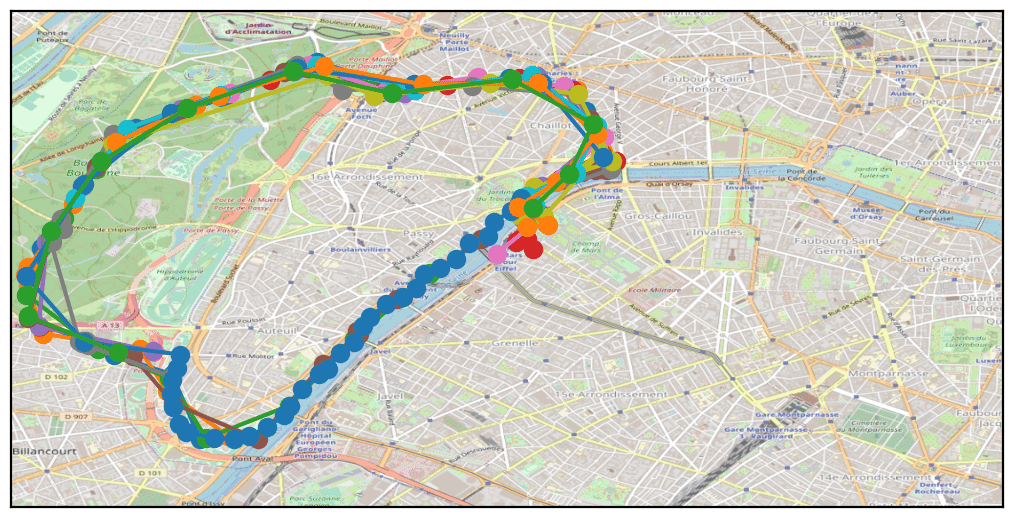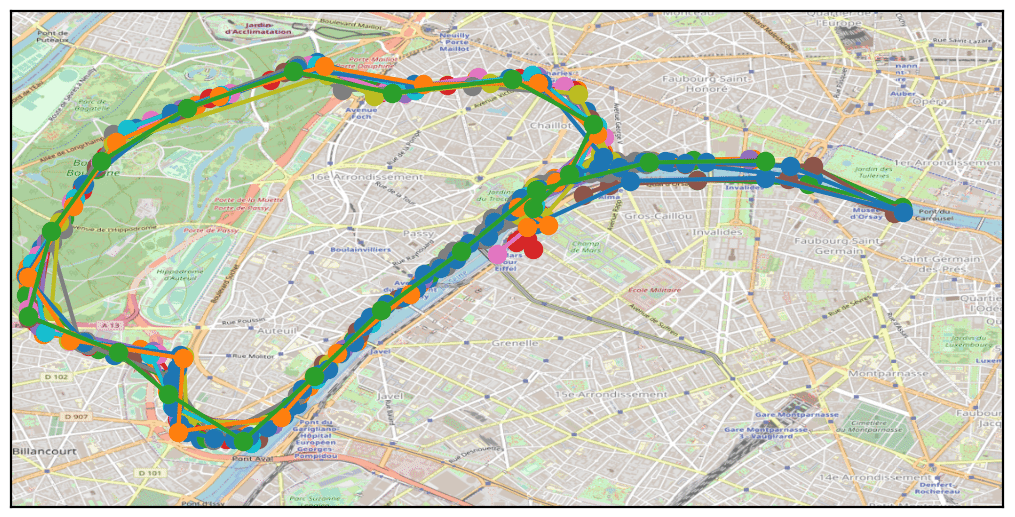
Le partitionnement de données (clusterisation)
A ce stade, notre démarche a été de nous concentrer sur les points d’intérêts, les endroits sensibles permettant de réidentifier les individus. Avec un algorithme faisant des regroupements de points (« clusters »), en triant sur les horaires et les jours, on peut très rapidement avoir une bonne estimation de l’endroit où vous passez du temps les weekends et la nuit, et de l’endroit où vous êtes la journée en semaine.
Ainsi, pour chaque trace nous pouvons avoir la géolocalisation du domicile et du lieu de travail. En utilisant par la suite une fonctionnalité du site OpenStreetMap qui permet de récupérer une adresse postale à partir d’une géolocalisation, nous avons pu identifier les différentes adresses pour chacun des 800 000 téléphones portables.
Bien sûr, dans certains cas il y a des erreurs, notamment dû au fait qu’en octobre 2021 la forte circulation du Covid-19 nous incitait à télétravailler, ou d’autres fois simplement des erreurs de précision dans notre algorithme.
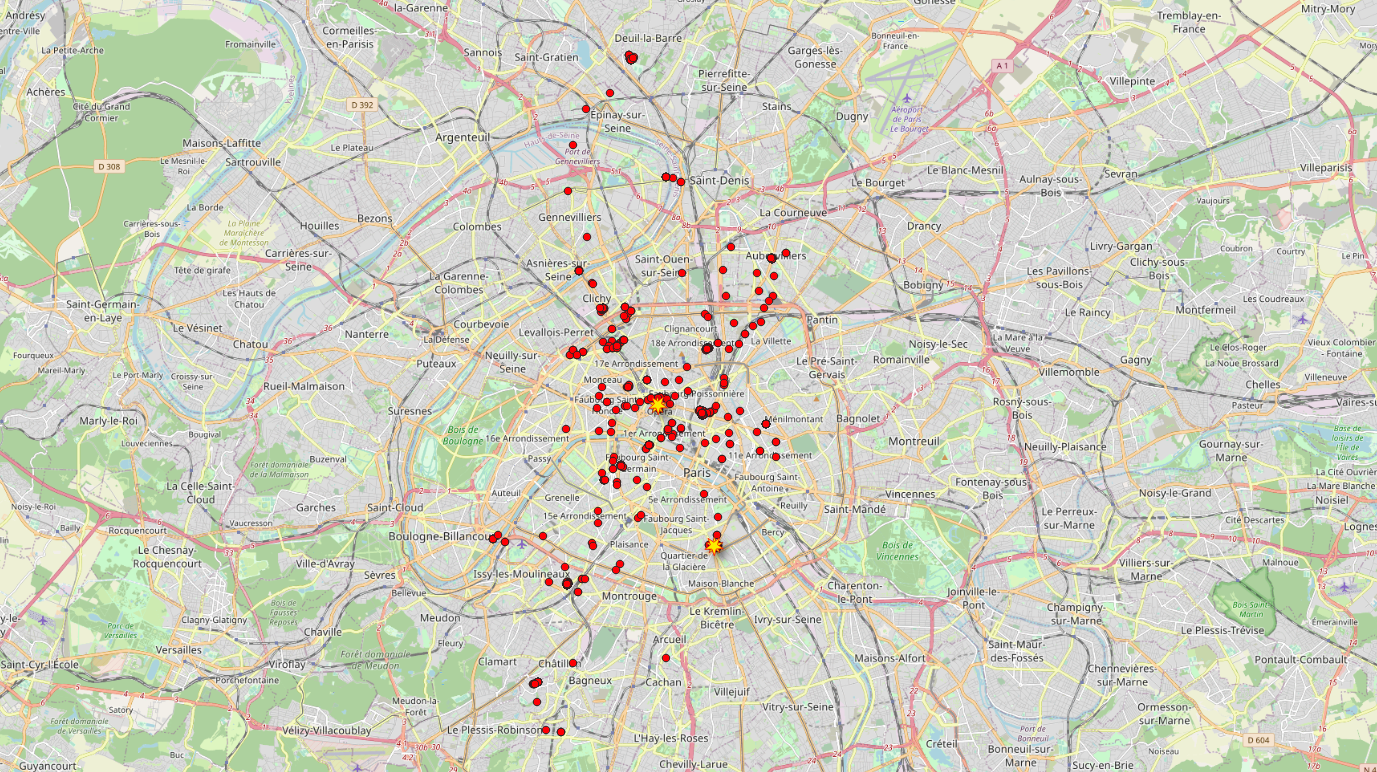
Recherche en sources ouvertes
L’étape suivante de nos travaux a reposé sur des recherches en sources ouvertes. Nous avons mobilisé différentes techniques – notamment pratiquées par des journalistes, mais aussi des enquêteurs publics ou privés – permettant de retrouver des informations théoriquement confidentielles en utilisant uniquement des données disponibles sur internet ou en libre accès en général.
|
Par exemple, au début de la guerre en Ukraine, une vidéo de missiles supposément envoyé par des Ukrainiens sur des soldats russes avait fait le tour des réseaux avant d’être « débunkée », c’est-à-dire révélée comme étant fausse, par un journaliste qui avait retrouvé dans le code source de la vidéo un fichier mp3 utilisé pour le fond sonore tiré d’une vidéo YouTube, et retrouvé ensuite les images de la vidéo dans des reportages sur des affrontements en 2014. Plus proche de notre cas de réidentification, le magazine Le Tigre met en lumière dans une série d’article les traces que peuvent laisser les individus en ligne.
|
Ici ce travail de recherche est assez limité, il a principalement reposé sur la consultation des pages blanches (pour les domiciles) et LinkedIn (pour les lieux de travail).
Réidentification
Pour estimer le nombre de personnes que nous pourrions réidentifier dans ce jeu de données, nous avons tiré au hasard 20 identifiants, sans discrimination de lieu ou de nombre de points présents dans la trace.
En cherchant simplement les adresses correspondantes dans des annuaires, nous avons pu assez rapidement avoir un certain nombre de noms qui ressortaient, avec une précision toute relative. On pouvait en demandant une adresse sur Les Pages Blanches, se retrouver avec le nom de la personne vivant dans la maison d’à côté par exemple. D'autres fois, plusieurs noms différents ressortent, indiquant que l'adresse demandée est en fait celle d'un immeuble.
Il faut aussi garder à l’esprit que le nom affiché peut être celui du propriétaire du logement, et non de celui qui y habite. Rappelons qu’en France, en 2021, un quart des ménages détenaient 68% des logements particuliers.
Concernant le lieu de travail, il est parfois directement renseigné dans l’adresse, comme pour les grandes enseignes par exemple. Parfois, il faut aller regarder sur des services de cartographie pour trouver l’information. Une fois le lieu établi, une recherche avec les mots clés « noms du lieu de travail » et « nom de famille de la personne » sur des réseaux sociaux ou directement le site internet de l’entreprise ont permis de confirmer qu’une personne portant ce nom travaille dans l’endroit identifié.
Ainsi, il nous aura fallu très peu de temps (environ une journée) pour trouver 7 personnes (sur les 20 identifiants du début) dont les lieux de vie et de travail semblaient correspondre aux données que nous avions dans la base. Sur la base de cet échantillon, un tiers des gens apparaissaient ainsi réidentifiables sur un jeu de données tiré au hasard. Anonymes nous disions donc…
Ces personnes réidentifiées, il nous était possible de savoir, heure par heure, ce qu’elles avaient fait durant cette semaine du 8 au 15 octobre 2021. Où elles avaient dormi, quand elles avaient fait leurs courses, quelles routes elles avaient prises pour aller au travail, quand elles avaient déposé leurs enfants à l’école, etc.
Si des meetings politiques avaient eu lieu cette semaine-là, il est fort probable que nombre de propriétaires des téléphones présents dans notre base de données y auraient participés. Nous permettant ainsi d’en dégager certaines opinions politiques.
Pour rappel, dans le cadre de cette étude, nous n’avons eu accès qu’à un seul (petit) échantillon ! En payant les prix énoncés au début de cet article, nous aurions eu un jeu de données couvrant une année entière, ou une zone en particulier…
|
Estimer le risque de réidentification en fonction de la ville ? Pour aller un peu plus loin, l’algorithme finalement développé permet, en croisant les points géographiques avec les données de l’INSEE, de donner pour chaque identifiant un score de « réidentificabilité ». En effet, la base Filosofi de l’INSEE propose des carrés de 200m de côté qui répertorient le nombre d’habitants par tranche d’âge, ainsi que le type de logement (communs ou individuels). Ainsi, en cherchant un équilibre entre zone peuplée (mais pas trop), habitats individuels (plutôt que des immeubles), et en filtrant sur l’âge pour conserver en majorité les personnes actives professionnellement, il est possible trier les identifiants de la base de données, du plus facile à réidentifier au plus complexe. |
Un problème avec la géolocalisation ?
Nous sommes loin d’être les premiers à nous être intéresser à la réidentification par géolocalisation : pouvoir retrouver un individu dans un nuage de traces est faisable depuis déjà quelques années. En revanche, le fait de pouvoir réidentifier autant d’individus grâce à des données récupérées aussi facilement est un problème plutôt récent. On le voit avec les différents articles parus entre 2018 et aujourd’hui, parlant des dérives de certaines applications utilisant ce genre de données, que ça soit en 2018 où plus d’une vingtaine d’agents de la DGSE ont été réidentifiés parce qu’ils utilisaient l’application sportive Strava, ou plus récemment où un media Danois révelait avoir acheté les données de plus de 60 000 smartphone pour 4800€.
Ces données de géolocalisation sont donc des données sensibles, et cela se voit encore plus lorsque l’on s’intéresse à ce qu’elles nous disent sur les habitudes des gens. Il serait par exemple possible de se renseigner sur les lieux de culte fréquentés, surveiller certains bâtiments sensibles en observant qui s’y rend régulièrement. Dans une étude précédente du LINC, avec des données récupérées sur des taxis à New York, il nous a été possible de savoir qui allait dans quels des clubs de strip-tease.
Même en utilisant des mécanismes pour obfusquer ce genre d’informations, les applications que nous utilisons au quotidien restent vulnérables (A Run a Day Won't Keep the Hacker Away), et quand les courtiers en données rentrent dans l’équation, il n’y a plus vraiment de secrets pour personne. Aucune vraie justification concernant l’utilisation que nous allions faire des données récupérées n’a été fournie, et il nous a fallu que peu de temps pour arriver à réidentifier des gens. Les applications qui ont permis à ce data broker d’agréger ces informations ne sont – pour l’heure – pas connues.
|
Que fait la CNIL ? Suis-je concerné ? L’ensemble des éléments découverts dans cette expérimentation ont été partagés avec les services en charge de définir les priorités de contrôles et la question des courtiers de données fait partie des axes prioritaires pour l’activité répressive de la CNIL. Il n’est pas possible à ce stade de communiquer sur le cas particulier expérimenté par le LINC. Par ailleurs, la CNIL travaille en 2023 à l’élaboration de recommandations à destination de l’écosystème mobile qui est un des trois sujets principaux de son plan stratégique 2022-2024 . Si vous souhaitez plus d’informations sur ce traitement ou si vous souhaitez exercer vos droits, vous pouvez contacter ip[at]cnil.fr ou adresser un courrier à la CNIL à l’attention du service LINC.
|
Illustrations : Pixabay & LINC


