
WhereUAt – A Geolocation Re-identification Project
Rédigé par Romain Pialat
-
14 June 2023In this article, we look back at the geolocation re-identification project, launched at LINC in 2022 and completed in 2023, demonstrating that near-automatic re-identification of individuals can be carried out using data obtained from data brokers, without any constraints or verification.
This article follows up on the study conducted by Cyril Miras during the summer of 2022, who developed part of the algorithms used here.
A Bit of Context
Where were you on October 10, 2021? The question may seem uninteresting. But if I told you that I know exactly where you were on October 10, 2021, where you ate, who you visited, what time you woke up, and when you returned home — suddenly it becomes unsettling. Welcome to the world of geolocation, data brokers, data clustering algorithms, and open-source intelligence.
For some time now, digital data has been referred to as the “new oil.” In the era of Big Data, our system relies heavily on massive collections of personal data to feed algorithms that enable increasingly precise decision-making. Whether for a machine learning model in healthcare or an advertising targeting algorithm, the more data there is, the better.
Our data — collected everywhere via cookies or permissions we grant to mobile apps without necessarily reading them — makes many people happy. Its resale is a real market, where data brokers allow — sometimes almost anyone — to acquire your information for unforeseen uses.
After journalists managed to obtain the geolocation data of a priest and prove he frequented gay bars, LINC wondered how such seemingly sensitive data could end up freely circulating. Would it be possible to obtain a sample of geolocation data based in France? To reproduce the re-identification experiment? At what cost and under what legal basis?
By retracing the events, we will see that it is possible to massively re-identify people and thus intrude into their private lives without their awareness.
“Every move you make, Every bond you break, Every step you take, I'll be watching you.”
— The Police
Data Collection
When looking for ways to obtain geolocation data, it quickly became clear that turning to data brokers was the most promising option.
By searching online on a platform allowing various data brokers to sell datasets, one database appeared more comprehensive than the others, especially for individuals located in France. Its description stated that it contained anonymized geolocation data and that a free sample was available. Pricing ranged from several thousand euros per month to over one hundred thousand euros per year depending on usage and geographic coverage — sometimes a trivial amount compared to the potential profits derived from such data.
|
The MAID (Mobile Advertising ID) is a unique identifier assigned to your mobile device, enabling advertisers to associate a profile with you and deliver targeted content. IIt is possible to reset your MAID, generating a new unique identifier and thereby limiting online tracking of your device. |
In addition to this data — which is the main focus of this article — each row also included IP addresses, country and city indicators for the geolocation point, a measure of location precision at the time of recording, and other less relevant data. The database totaled approximately 15 GB and 100 million rows, requiring cleaning and sorting before analysis.
|
Security Note To ensure data security and compliance with personal data protection laws in the event of re-identification, an encrypted computing server was set up to store the dataset. It was accessible only to LINC staff involved in the study.. At the beginning of the project, a public notice was issued to allow individuals to exercise their rights. |
Processing
During data sorting, information was distributed into several columns to isolate what was useful for the project. Using Python, Jupyter Notebooks, and the Pandas module, an initial filtering was conducted to remove data unusable for our re-identification method.
We kept only: - Geolocation points - The timestamp of each point - The identifier linking each row to a mobile device.
A quick check revealed 5 million unique identifiers in the database — potentially 5 million “tracked” phones. Some had many geolocation points, others very few, sometimes only one. After excluding devices with insufficient data, approximately 800,000 identifiers remained usable.
The data was grouped by unique identifier, creating 800,000 distinct datasets, each retracing the movements of a phone. We call such a sequence of points a “trace.”
Reliable Data?
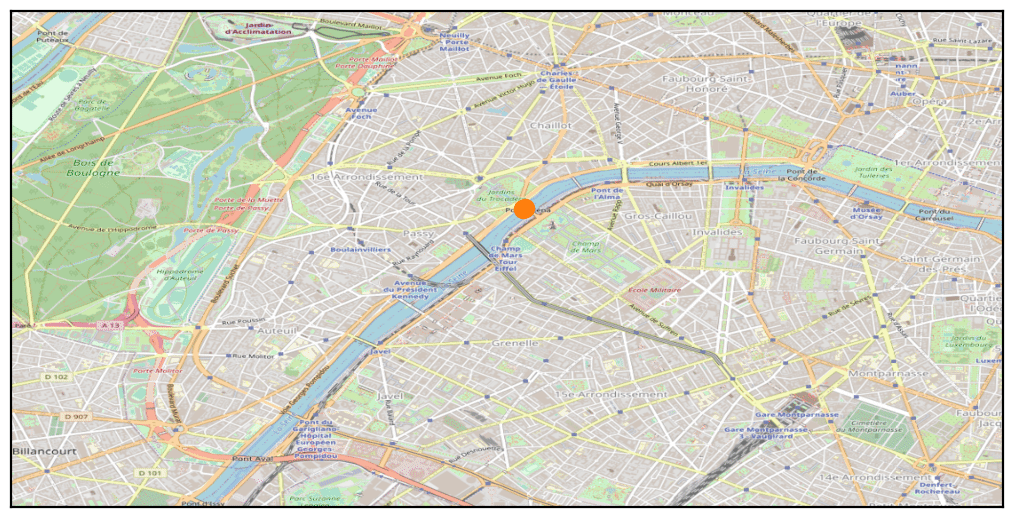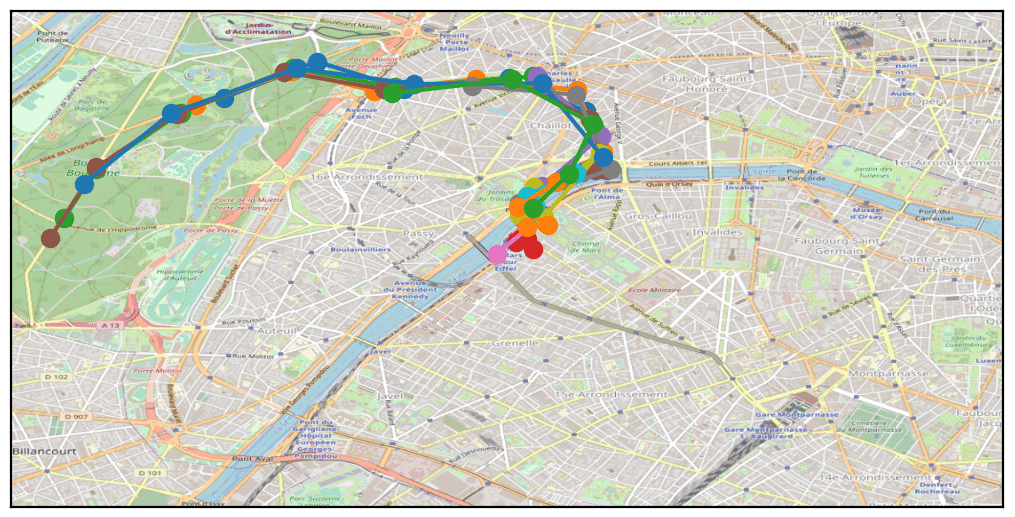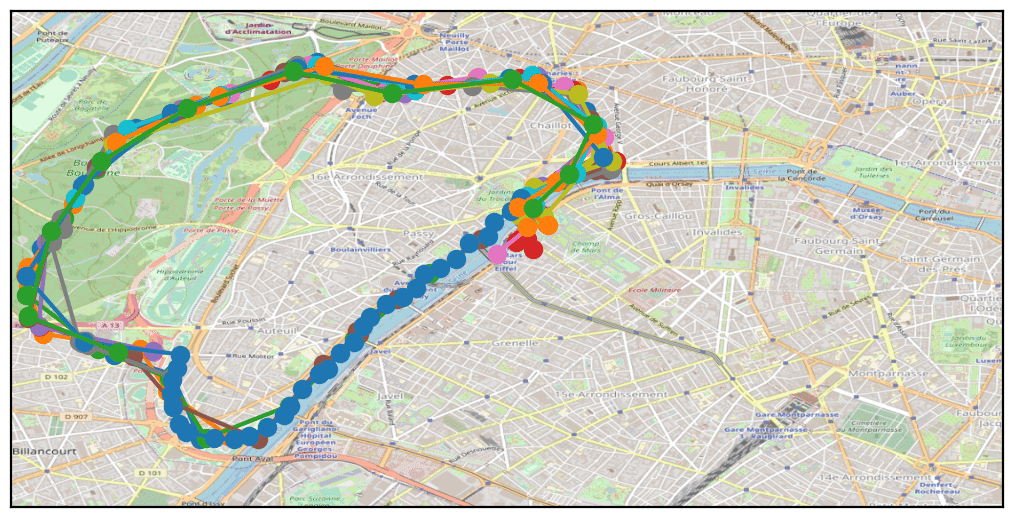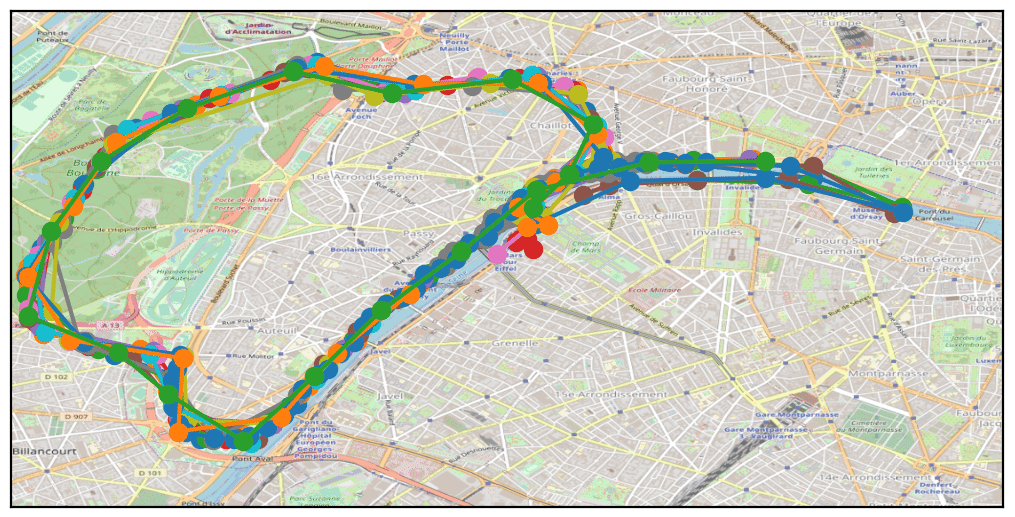
Looking at the distribution of points and the total number of traces, the first question was whether these were genuine geolocation points or randomly generated ones.
By examining public events held between October 8 and 15, 2021, we quickly found the “20km de Paris” race, which took place on Sunday, October 10. Clear correspondences were observed between the race route and certain phone traces in our dataset, confirming the likely reliability of the sample data.
Data Clustering
At this stage, we focused on points of interest — sensitive locations that could enable re-identification.
Using a clustering algorithm that grouped points by time and day, we could quickly estimate where individuals spent weekends and nights, and where they were during weekdays.
Thus, for each trace, we could determine the likely home and workplace locations. Using OpenStreetMap functionality to convert geolocation into postal addresses, we identified addresses for each of the 800,000 mobile phones.
Of course, errors occurred — due to remote work during COVID-19 in October 2021 or location precision issues.
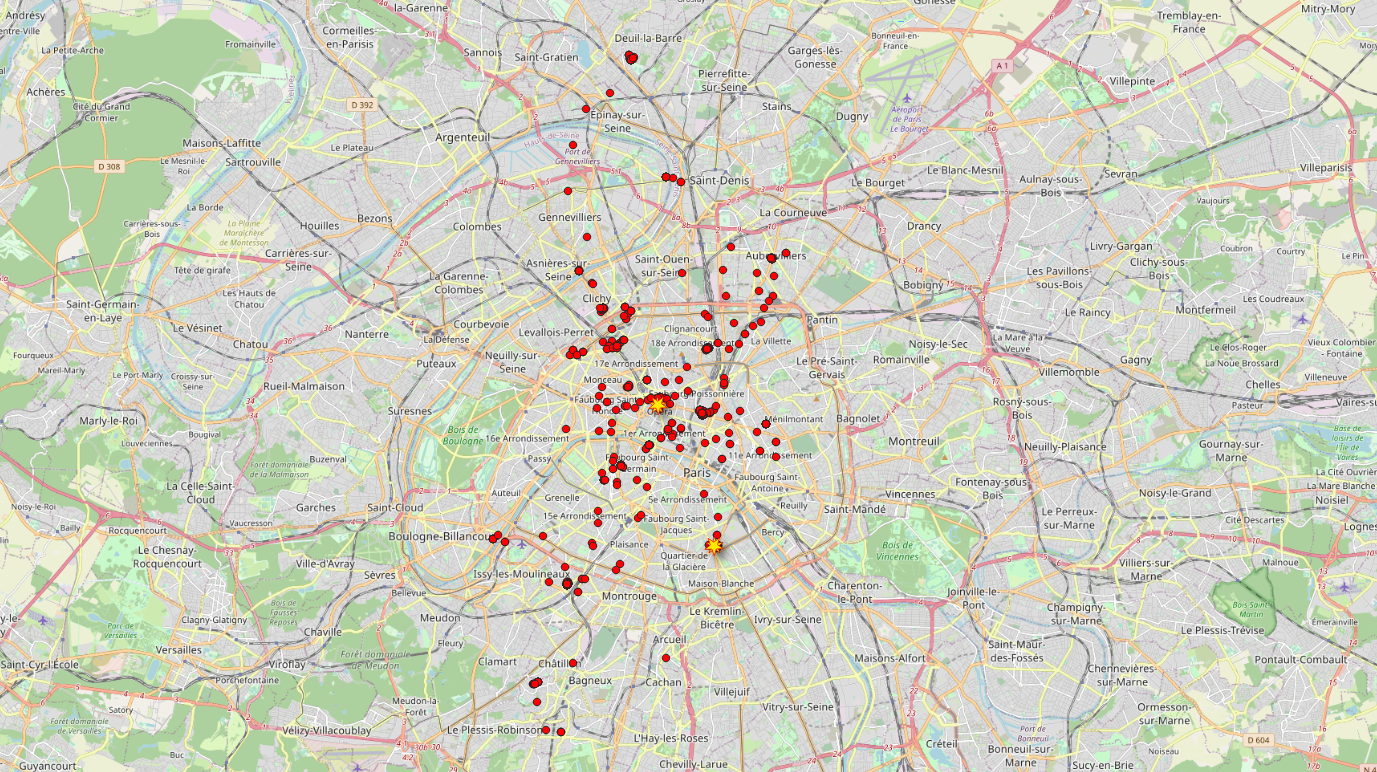
Open-Source Intelligence (OSINT)
The next stage involved open-source research. Techniques commonly used by journalists and investigators were applied to retrieve theoretically confidential information using only publicly available sources.
|
For example, at the start of the war in Ukraine, a video allegedly showing Ukrainian missiles targeting Russian soldiers circulated widely before being debunked. A journalist found that its soundtrack came from a YouTube video and that its footage dated back to 2014. Closer to our case, the magazine Le Tigre highlighted in a series of articles the digital traces individuals leave online. |
In our case, research mainly involved consulting phone directories (for residences) and LinkedIn (for workplaces).
Re-identification
To estimate how many people could be re-identified, we randomly selected 20 identifiers without filtering by location or trace length.
By searching corresponding addresses in directories, we quickly found several names, albeit with varying precision. Sometimes searching for one address returned the name of someone living next door. In other cases, multiple names appeared, indicating apartment buildings.
It is also important to remember that the displayed name may be that of the property owner, not the occupant. In France in 2021, one quarter of households owned 68% of private housing.
Workplaces were sometimes directly identifiable from the address. In other cases, mapping services were used. Once identified, searches combining the workplace name and the individual’s surname on social networks or company websites confirmed employment.
Within about one day, we identified 7 people (out of 20 sampled identifiers) whose home and workplace matched the dataset. Based on this sample, roughly one-third appeared re-identifiable from a random dataset. Anonymous, we said?
For these individuals, it was possible to reconstruct hour by hour what they did during the week of October 8–15, 2021: where they slept, when they shopped, which routes they took to work, when they dropped their children at school, and so on.
If political meetings had occurred that week, it would likely have been possible to infer certain political opinions from attendance patterns.
Remember: we only had access to a small sample. By paying the prices mentioned earlier, we could have obtained a dataset covering an entire year or a specific region.
Estimating Re-identification Risk by CityThe developed algorithm also allowed cross-referencing geolocation points with INSEE data to generate a “re-identifiability score” for each identifier. The INSEE Filosofi database divides territory into 200-meter squares, listing the number of residents by age group and housing type (individual homes vs. apartment buildings). By balancing population density (but not too dense), individual housing, and filtering for working-age individuals, identifiers could be ranked from easiest to hardest to re-identify. |
Is Geolocation a Problem?
We are far from the first to study geolocation-based re-identification. Identifying individuals within location traces has been possible for years. However, the ease with which such data can now be obtained is more recent.
Since 2018, various reports have highlighted abuses:
- In 2018, more than 20 French intelligence agents were re-identified through Strava usage.
- More recently, a Danish media outlet purchased data from over 60,000 smartphones for €4,800.
Geolocation data is therefore highly sensitive. It can reveal religious practices, visits to sensitive buildings, or even private activities. In a previous LINC study using New York taxi data, it was possible to determine who visited which strip clubs.
Even with obfuscation mechanisms, everyday apps remain vulnerable (“A Run a Day Won’t Keep the Hacker Away”), and once data brokers enter the equation, privacy becomes extremely fragile. No real justification was required to obtain the data, and re-identification took very little time. The apps enabling this data aggregation remain unknown.
|
What Is CNIL Doing? Am I Concerned? All findings from this experiment were shared with services responsible for defining inspection priorities. Data brokers are now among CNIL’s enforcement priorities. At this stage, no details can be shared regarding the specific broker used. In 2023, CNIL is developing recommendations for the mobile ecosystem, one of the three main themes of its 2022–2024 strategic plan. For more information or to exercise your rights, you can contact ip[at]cnil.fr or write to CNIL, attention LINC service. |
Illustrations: Pixabay & LINC


