
Preuve de concept d’un assistant vocal respectueux de la vie privée des utilisateurs
Rédigé par Jérôme Gorin et Thomas Le Bonniec
-
02 November 2022Dans son Livre blanc « À votre écoute » traitant de l’exploration des enjeux éthiques, techniques et juridiques des assistants, la CNIL recommande un traitement local de l’information de la voix pour les usages qui ne nécessitent pas le partage de données, et ce afin de préserver la vie privée des utilisateurs et de leur entourage. Pourtant, les assistants vocaux notamment intégrés aux enceintes connectées et aux téléphones reposent encore aujourd’hui presque exclusivement sur des traitements déportés sur des serveurs. Afin de prouver qu’un traitement à la main de l’utilisateur et respectueux de la vie privée de ses utilisateurs est possible, le LINC a développé un assistant vocal fonctionnant exclusivement en local, et sans connexion internet. Cette preuve de concept, « Mon Assistant CNIL », est disponible et testable sur les magasins d’applications Android et iOS.

Rappel sur le fonctionnement des assistants vocaux et ses risques
Les assistants vocaux désignent des systèmes qui dialoguent avec l’utilisateur, via des « commandes », activées par des mots-clés. On les retrouve dans toute sorte d’équipement et d’applications, des enceintes aux voitures connectées, en passant par les smartphones. Pour les grandes entreprises du numérique, ces assistants constituent souvent un moyen de faciliter l’accès à leurs propres services, et à les promouvoir : Cortana pour Microsoft, Siri pour Apple, Alexa pour Amazon, et Google Assistant pour Google.
Ces enceintes connectées présentent deux caractéristiques : être placées au centre du foyer et offrir la voix pour principale – voire unique – interface. La voix, la matière première qu’ils captent, est très fortement ancrée dans notre intimité. Nous écrivions à ce propos dans le Livre Blanc « À votre écoute » :
« Véhicule privilégié de nos interactions sociales, l’analyse que nous réalisons de la voix peut permettre la compréhension du message transmis, l’identification de son émetteur, mais également la catégorisation de celui-ci selon différentes modalités. Il s’agit donc d’une donnée personnelle qui, en fonction de l’utilisation qui en est faite, est à géométrie variable. Il convient de s’assurer que les principes cardinaux de la protection des données – qui concernent notamment la pertinence du traitement de données, sa transparence, le respect du droit des personnes, la maîtrise des données ou encore la gestion des risques de sécurité – sont bien respectés. »
À VOTRE ÉCOUTE, Exploration des enjeux éthiques, techniques et juridiques des assistants vocaux COLLECTION LIVRE BLANC - N°1, CNIL, 2020, p.8
Le traitement des données par les assistants vocaux présente en effet un certain nombre de risques pour l’utilisateur, mais aussi pour son entourage. A ce titre, le Livre blanc recense cinq risques majeurs :
- la collecte de « données intimes potentiellement sensibles »,
- des « dispositifs enregistreurs de plus en plus présents dans les espaces partagés »,
- et « qui font intervenir de nombreux acteurs » (c’est-à-dire des intermédiaires et des applications tierces),
- des « écoutes par des humains » (qui écoutent et corrigent la transposition de la voix vers l’écrit),
- enfin, les « faux positifs» (c’est-à-dire des déclenchements intempestifs des enregistrements) et la venue de personnes extérieures (n’ayant pas conscience de la présence d’assistants vocaux) peuvent conduire à l’enregistrement de personnes non informées.
La sécurisation inhérente aux données captées par les assistants vocaux est enfin cruciale : plusieurs types d’attaques ont mis en évidence des vulnérabilités de cette interface. Nous écrivions par exemple dans l’article « Quand les assistants vocaux entendent des voix » :
« Les équipes de chercheurs de l’université de Berkeley ont ainsi pu cacher des messages de commande dans des bruits blancs qu’ils jouaient par-dessus le son de vidéo YouTube, pour faire appeler des numéros de téléphone ou ouvrir des pages web. Ils auraient pu tout aussi bien activer des fonctions plus gênantes, déjà disponibles via la commande à distance, comme ouvrir des portes ou transférer de l’argent. […] Une équipe chinoise a mis au point le système dit DolphinAttack, qui envoie de faux messages, dans un apparent silence, et désactive les réponses de l’assistant vocal. Il devient alors possible de le contrôler sans risque de se faire repérer par son propriétaire. Si les fabricants d’assistants connectés, Google, Amazon et Apple annoncent tous mettre en place des mesures de sécurité pour prévenir de telles pratiques, les outils de reconnaissance vocale peuvent comporter des vulnérabilités »
Le Livre blanc rappelle enfin que pour « les grands acteurs du numérique comme Google et Amazon dont l’activité repose sur l’exploitation des données à caractère personnel de leurs utilisateurs, il ne s’agit là que d’un nouveau vecteur de collecte ». Les assistants vocaux agrègent les données collectées avec d'autres services délivrés à l’utilisateur, dont les multiples finalités peuvent être masquées par des objectifs d’« amélioration de services » ou de « publicités ciblées ». Ainsi, une équipe de chercheurs, a pu mettre en évidence un lien entre les données collectées par une enceinte connectée Alexa d’Amazon et des publicités ciblées.
Les assistants vocaux sont souvent placés au centre des foyers. Leur interface simple et « conviviale » peut donc être utilisée par les plus jeunes et les exposer à certains risques en leur proposant des contenus non-adaptés voire explicitement dangereux.
« Le jeune public se voit également offrir des contenus spécifiquement produits pour lui : applications de blagues, de jeux, d’histoires lues, etc., dont de nombreuses cachent en vérité une finalité commerciale puisque développées par telle ou telle marque. Qui plus est par la manipulation de cette interface et grammaire d’usage, se façonne également « l’éducation » de futurs consommateurs. »
À VOTRE ÉCOUTE, Exploration des enjeux éthiques, techniques et juridiques des assistants vocaux COLLECTION LIVRE BLANC - N°1, CNIL, 2020
Rappelons enfin que la voix peut être utilisée par les assistants vocaux comme facteur d’authentification pour permettre de reconnaître un utilisateur : elle peut donc à elle seule être considérée comme une donnée biométrique, au sens de l’article 9 du RGPD. Cette spécificité signale le potentiel pour faire de la reconnaissance vocale un moyen d’isoler et identifier des individus à distance (voir encadré).
Les potentielles dérives de la reconnaissance vocale
En 2012, IflyTek, une entreprise chinoise qui développe, entre autres, un assistant vocal nommé Input, signe un contrat avec le gouvernement central de Chine. Le projet, lancé dans la province de l’Anhui, consiste à développer des bases de données avec les empreintes vocales des utilisateurs d’une station de travail nommée « Forensic Intelligent Audio studio », l’objectif étant de pouvoir effectuer un travail d’identification biométrique à distance. D’après l’ONG Human Rights Watch, d’autres projets impliquent la reconnaissance vocale développée par IflyTek au Tibet et au Xinjiang, et sont utilisés à des fins de répression politique.
Cet exemple nous rappelle que l’identification du locuteur peut être utilisée à des fins de pistage et de fichage. Cette identification est potentiellement très intrusive : elle permet d’isoler des individus à distance, de récupérer des informations sensibles les concernant, et de savoir où ils se trouvent en captant leur voix en temps réel.
Décomposition du fonctionnement d’un assistant vocal
Le fonctionnement d’un assistant vocal suit les trois étapes suivantes :
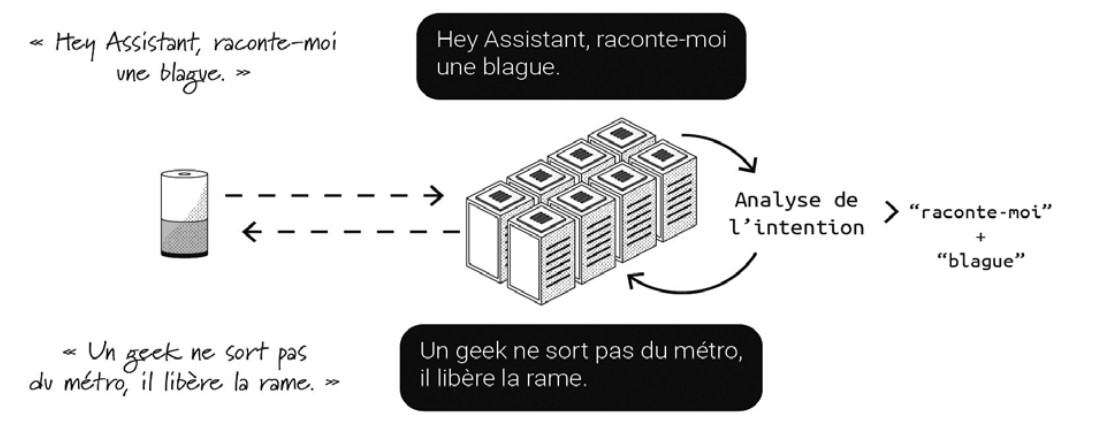
- La première identifie le moment d’activation souhaité par l’utilisateur : par la reconnaissance d’un mot-clé, l’appui sur un bouton ou, plus récemment, par un simple regard vers le dispositif. Ce moment d’activation ouvre un canal d’enregistrement des sons captés par le micro qui sera transmis intégralement vers un service d’assistant vocal hébergé sur un serveur tiers.
- Ce service tiers transforme l’enregistrement en texte et réalise une analyse sémantique de celui-ci pour générer une réponse. La génération de cette réponse peut nécessiter des ressources supplémentaires, dans les données de l’utilisateur (comme son carnet d’adresses) ou sur le web (pour indiquer un itinéraire par exemple). La réponse est enfin synthétisée et retransmise au dispositif en écoute.
- La dernière étape consiste enfin à diffuser sur le haut-parleur la réponse vocale générée.
Cette architecture « classique » n’est pas sans conséquence sur la vie privée des utilisateurs. Ces dispositifs génèrent un nombre non négligeable de faux positifs, où l’assistant vocal transmet des enregistrements au service tiers sans avoir été réellement sollicité par son utilisateur. Du fait de ces faux positifs, l’usage d’assistants vocaux implique d’accepter que des enregistrements captés hors situation d’activation soient collectés et traités sur des serveurs tiers.
Dans certains cas, une partie de ces enregistrements est par ailleurs reversée dans des bases de données et traitée par des travailleurs humains pour entraîner l’assistant vocal afin d’améliorer la reconnaissance du mot-clé, la transcription de la voix et l’analyse des intentions de l’utilisateur. Ceux-ci font de l’entrainement et de la correction sur des enregistrements réels, comportant potentiellement des conversations privées et des données sensibles. Cette partie du traitement, désactivé par défaut, est activée dès lors que l’utilisateur consent à l’utilisation de ses données audio à des fins d’« amélioration du service ».
Présentation de Mon Assistant CNIL
Apport de l’assistant vocal CNIL comparé aux assistants vocaux « classiques »
L’expérimentation initiée par le LINC consiste à reproduire le fonctionnement d’un assistant vocal sans qu’aucun tiers n’ait accès aux enregistrements, c’est-à-dire dans un mode de fonctionnement intégralement local et hors-ligne. Cette contrainte implique de repenser les différentes étapes de traitement des données pour optimiser la qualité des réponses tout en limitant l’impact sur les ressources de calcul nécessaires au fonctionnement du service.
Le cas d’usage identifié pour cette expérimentation est de répondre aux questions les plus fréquemment posées par les usagers, suivant la base de connaissance « Besoin d’aide » déployée sur le site de la CNIL. Cette base est composée de plus de 400 questions formulées auxquelles sont associées des réponses et un ensemble de mots-clés. Pour les besoins du projet, cette base de connaissance a été extraite dans un format lisible par la machine et distribuée sur Github en licence ouverte.
Les étapes de développement du projet
En synthèse, un assistant vocal repose sur la combinaison des trois fonctions élémentaires pour simuler une conversation en langage naturel :
- La reconnaissance automatique de la parole (Speech to text) qui permet au logiciel de transformer une requête vocale en texte après avoir analysé son contexte. Cette analyse du contexte est indispensable à une bonne retranscription, un mot pouvant avoir de multiples sens suivant le contexte.
- Le traitement automatique du langage naturel (Natural Language Processing) qui permet d’analyser les phrases courantes et d’en extraire une ou plusieurs intentions, c’est-à-dire d’en comprendre le sens. Il s’agit d’analyser la syntaxe et la sémantique des phrases pour comprendre le besoin de l’utilisateur.
- La synthèse vocale (Text To Speech) qui permet de lire instantanément et précisément le texte de réponse d’une voix nette (et naturelle éventuellement). La synthèse vocale nécessite de connaître la langue et le type de voix choisie (femme/homme par exemple) pour générer une réponse suffisamment compréhensible par l’utilisateur, les modèles de synthèse étant dépendant de la langue.
La contrainte majeure qui va guider les choix technologiques réside dans les caractéristiques du terminal visé. Dans le cadre de l’assistant CNIL, nous visions les terminaux mobiles. L’application doit ainsi être en mesure de fonctionner avec des ressources de calcul limitées.
Un entraînement de modèle conforme aux exigences du RGPD
Pour la reconnaissance automatique de la parole, l’ensemble des étapes d’entrainement a été réalisé avec des logiciels en mesure de réaliser des entraînement hors-ligne sur un serveur dédié. Cet entraînement vise à limiter les défauts d’interprétation inhérents à la forme des informations contenues dans la base de connaissance. A ce titre, le vocabulaire utilisé par la base de connaissance « Besoin d’aide » est spécialisé, car il contient un lexique spécifique à la protection des données.
Afin que chaque question posée par l’utilisateur puisse être retranscrite, huit agents volontaires de la CNIL ont été impliqués dans la phase d’apprentissage.
Nous leur avons demandé de lire des questions à voix haute pour les associer aux phrases écrites correspondantes, ainsi que des expressions spécifiques, par exemple les termes anglais (cookies, Privacy Shield, blockchain, etc.), les noms de marques (Facebook, Baidu, Google, etc.) ou encore les acronymes (FNAEG, HTTPS, CNIL, etc.). Ces termes assez spécifiques ont nécessité un entraînement particulier pour être correctement reconnus.
La voix étant une donnée personnelle, il a été nécessaire d’assurer que les volontaires étaient à tout moment en mesure d’exercer leurs droits, notamment d’accès et de retrait du consentement. Ainsi, si l’un d’eux vient à retirer son consentement, alors cela implique le retrait de ses données de la base d’entraînement et donc le déploiement d’une mise à jour de l’application.
Pour permettre cet exercice des droits, chaque volontaire s’est vu attribuer un pseudonyme spécifique à ses enregistrements. Le lien entre pseudonyme et identité réelle de la personne est conservé dans une table de correspondance unique, accessible par un nombre restreint de membres de l’équipe projet et ce pendant dans la durée de vie de l’application (ce qui correspond à la durée de la mise à disposition sur les magasins d’applications). A l’issue du projet, les enregistrements et la table de correspondance seront supprimés.
Le traitement automatique du langage naturel ainsi que la synthèse vocale n’ont pas nécessité de collecte ou de traitement de nouvelles données personnelles :
- Le traitement automatique du langage naturel a reposé sur la pondération de mots, la mesure de similarité, le filtrage et la racinisation des mots présents dans les questions de la base de connaissance.
- La synthèse vocale est réalisée hors-ligne en associant un ensemble de fichiers audio pré-générés aux réponses textuelles afin de limiter les dépendances sur l’application et les ressources de calcul nécessaires.
Bilan de l’expérimentation
Méthode et réalisation du concept
Un ensemble de 477 questions rédigées en français par des agents de la CNIL a été utilisé pour évaluer l’efficacité du système de reconnaissance de questions, chaque question étant associée à une réponse attendue. Cet ensemble s’ajoute à la base des questions connues, pour lesquelles une réponse est déjà prête. Le taux de résultat positif, c’est-à-dire avec une réponse correspondant à la question posée, est de 97%.
Ce projet, en ligne avec les recommandations de notre Livre Blanc « À votre écoute », prouve qu’il est possible de concevoir des assistants vocaux plus protecteurs des données des utilisateurs. Il démontre que des moyens techniques existent pour réaliser des traitements de qualité des enregistrements audio et capables de fonctionner sur des dispositifs dotés de ressources limitées.
Une solution semi-ouverte
Bien que l’utilisation de technologies ouvertes et sous licence libre ait été favorisée lors du développement, tel que le projet Mozilla DeepSpeech pour la reconnaissance automatique de la parole, certaines briques logicielles utilisées sont propriétaires : la solution eNova de la société Harman pour le traitement automatique du langage naturel ainsi que le logiciel Readspeaker pour réaliser la synthèse vocale. Le code source de l’application est lui disponible sur Github sous licence ouverte. La liste complète des technologies utilisées et des licences associées est également disponible ici. Le LINC est à la disposition de tout développeur, chercheur ou fournisseur de solutions proposant des alternatives en logiciel libre à ces briques.
Les principes et partis pris de l’assistant vocal de la CNIL
La réalisation de « Mon assistant CNIL » répond également à un parti pris. D’une part, celui de développer un assistant vocal spécialisé et non généraliste, capable de chercher des ressources dans une base limitée, et non d’imiter une conversation qui aurait du sens pour un humain. D’autre part, le choix intégré dans le processus de conception et d’entraînement de l’assistant vocal : tenir compte des impératifs de respect des droits des contributeurs qui donnent leur voix pour entraîner l’assistant.
Ces choix effectués à la conception déterminent la forme et les capacités de l’outil à partir des usages que l’on souhaite donner à un assistant vocal : celui de la CNIL met au premier plan les impératifs de la protection des données.
S’il n’a bien sûr pas les capacités d’un assistant grand public, cette expérimentation rappelle qu’un assistant vocal peut prendre des formes différentes en fonction du rôle qu’on veut lui prêter. Réduit à un usage spécialisé, il permet à la fois de minimiser les risques et les données utilisées et de respecter un principe de proportionnalité entre la quantité de données personnelles nécessaires à son développement et son utilité finale.
Illustration - CNIL (CC BY-ND-NC 3.0 FR)

