[itw] Joana Revis: "Notre voix porte en elle toutes les intentions qui sont les nôtres"
Rédigé par Félicien Vallet
-
28 March 2018Dans le cadre de notre série consacrée au développement du marché des assistants vocaux, nous nous intéressons à ce qui fait la spécificité de notre voix, aux informations qu’elle véhicule et aux rapports que nous avons avec elle.
Entretien avec Joana Revis, orthophoniste-vocologiste et maître de conférences associé à la faculté de médecine Aix Marseille Université.
LINC : Tout au long de notre vie, notre voix nous accompagne. Quelle(s) relation(s) entretenons-nous avec elle ?
Joana Revis: Notre voix fait tellement partie de nous que c’est la toute première chose que nous faisons à la naissance : pousser un cri ! Elle nous accompagne effectivement tout au long de notre vie, elle change au fil du temps, elle évolue, elle est là, tout le temps sans que nous y pensions et la plupart d’entre nous entretenons finalement une relation assez ingrate avec elle : elle est là et c’est la moindre des choses, et nous n’en prenons pas vraiment soin. Il n’y a finalement que deux situations dans lesquelles nous en prenons conscience : lorsque nous entretenons un rapport passionnel avec elle (c’est le cas des chanteurs par exemple ou des comédiens), ou lorsque nous la perdons (au cours d’une simple laryngite ou dans le cas de lésions chroniques des cordes vocales). Là, tout d’un coup, nous nous rendons compte de son importance
Et en pratique, cette voix, d’où vient-elle ?
La voix est produite par la vibration de nos deux cordes vocales qui sont situées dans notre larynx à l’intérieur de notre cou. Précisément, le larynx est situé au niveau de la « pomme d’Adam » qui est un cartilage (le cartilage thyroïde) et qui constitue un bouclier pour protéger le passage de l’air pendant la respiration. Le larynx est la partie supérieure de l’appareil respiratoire tout en haut de la trachée qui descend vers les poumons. Pour respirer les cordes vocales s’ouvrent et laissent entrer l’air dans les poumons, pour avaler elles se ferment pour empêcher les aliments de tomber dans les poumons. Le larynx constitue donc le carrefour entre le système respiratoire (trachée, bronches, poumons) et le système digestif (l’œsophage est situé en arrière du larynx et conduit les aliments vers l’estomac). Pour émettre la voix, les cordes vocales se rapprochent et viennent s’accoler l’une à l’autre : elles se mettent alors à vibrer au passage de l’air qui vient des poumons. Schématiquement, plus les cordes vocales sont serrées l’une contre l’autre plus le sont sera fort, et plus les cordes vocales sont tendues plus le son sera aigu. C’est comme ça que nous pouvons moduler notre voix pour parler ou pour chanter. Donc en pratique pour produire un son, nous avons besoin des cordes vocales et de l’air expiratoire. Pour que ce son devienne de la parole, des mots, nous avons aussi besoin des organes résonateurs qui sont situés au-dessus du larynx : la langue, le pharynx, le voile du palais et les lèvres. Quand on vous dit : « articule ! », vous pouvez vous rendre compte que vous prenez davantage de soin dans les mouvements de vos lèvres ou de votre langue pour que les syllabes soient plus nettes. Donc la voix, elle a besoin d’air (poumons), de son (cordes vocales) et d’articulation (résonateurs).
La voix est le véhicule privilégié de nos interactions mais que révèle-t-elle sur nous ?
Tout ! Absolument tout ! La situation dans laquelle nous nous en rendons le mieux compte, c’est au téléphone, puisque nous sommes privés d’indices visuels. Lorsqu’un inconnu nous appelle, nous savons immédiatement si c’est un homme ou une femme, et nous avons une idée assez précise de son âge – enfin la plupart du temps puisqu’à toute règle, il y a toujours des exceptions. Ces caractéristiques sont décryptées de manière incroyablement performante mais, vous allez me dire, ce sont des caractéristiques assez grossières et l’exercice est un peu facile. Alors allons plus loin.
Vous vous êtes sans doute rendu compte que lorsque vous appelez un de vos proches au téléphone, à l’instant où il vous dit « allô », vous savez comment il va. Pour comprendre ça, il faut considérer que les émotions ne sont pas qu’une dimension psychique. Elles ont un point de départ physique, biochimique, tout à fait concret dans le corps. Quand on a peur par exemple, il y a une décharge d’adrénaline qui fait que notre cœur bat plus vite, notre respiration s’accélère et tous les muscles de notre corps se tendent pour faire face à la situation. Comme notre voix utilise à la fois l’air des poumons et les muscles des cordes vocales, alors ça s’entend dans la voix. Toutes les émotions sont définies par deux dimensions : la valence (caractère agréable ou désagréable) et l’arousal (caractère excitant ou lénifiant). La voix est particulièrement sensible à l’arousal, c’est à dire au degré d’activation psychologique mais aussi musculaire qui accompagne l’émotion. Ainsi dans la joie on a beaucoup d’énergie. La voix est plus forte, plus aigüe, plus tonique. Alors que dans la tristesse nous nous sentons faibles et la voix est plus grave, plus fragile, plus monotone. Ça fonctionne un peu de la même manière avec notre tempérament : un individu extraverti aura une voix « tonitruante » alors qu’une personne timide aura une voix plus douce, cherchant à se faire un peu oublier…
Enfin, en plus de révéler nos caractéristiques de genre et d’âge, notre tempérament ou nos émotions, notre voix porte en elle, au-delà des mots que nous prononçons, toutes les intentions qui sont les nôtres. C’est la magie de la prosodie qu’on appelle aussi l’intonation. A mots égaux, c’est la mélodie de notre voix qui va permettre de donner un sens différent à notre message. Par exemple, à la question « que fait-on maintenant ? » si je vous réponds : « On mange les enfants. » je deviens aussitôt un monstre cannibale infanticide. Alors que si je vous réponds : « On mange, les enfants ! » j’invite simplement ma progéniture à passer à table ! C’est ce qu’on appelle la fonction pragmatique de la prosodie, et la prosodie, comme elle est dépendante de la mélodie de la phrase, elle dépend essentiellement de notre voix.
Quelles sont les différences entre parler à un de nos semblables et parler à un être inanimé comme une enceinte, un véhicule ou une machine à café ?
Dans nos échanges avec les autres, il y a un phénomène qui est très étudié en linguistique et qui est absolument fascinant, c’est la convergence interactionnelle. Lorsque deux personnes parlent ensemble, chacune prend un peu des habitudes discursives de l’autre, un peu comme pour créer un espace commun qui va favoriser la compréhension mutuelle. En fait, elles s’imitent ! Par exemple, si l’un des deux se met à chuchoter, l’autre va progressivement réduire son intensité. Si vous renseignez dans la rue un touriste qui parle mal votre langue, vous allez appauvrir votre langage avec des mots plus simples, des phrases courtes, une syntaxe réduite au maximum. En fait, pour vous mettre à sa portée, vous imitez sa propre manière de parler. Dans n’importe quelle situation de la vie quotidienne, ça implique des modifications vocales, que ce soit dans la hauteur, dans l’intensité ou dans la prosodie. Vous prenez une pointe d’accent, ou un ton plus sérieux, ou un débit plus lent. Tout cela se fait indépendamment de votre volonté et vient imprimer votre voix. Il y a des travaux très amusants qui ont montré que par ailleurs, lorsque nous nous plaçons dans un système hiérarchique, les individus les plus « faibles » convergent davantage que les individus les plus « forts ». Par exemple, les hôpitaux universitaires sont remplis d’internes qui imitent le langage, la parole, la voix des chefs de service. Parmi ces internes, ceux qui seront devenus des années plus tard professeurs de médecine, cesseront de converger pour devenir la cible de l’imitation des plus jeunes !
Evidemment dans l’interaction homme-machine, les règles de ce jeu sont truquées puisque ni l’enceinte connectée ni la machine à café ne vont converger avec nous. Bien que nous plaçant probablement au-dessus de l’objet connecté d’un point de vue hiérarchique, nous allons compenser cette situation en modifiant notre communication pour nous mettre à la portée de la machine. D’une certaine manière nous nous mettons à converger puisque nous nous efforçons de nous adapter à l’idée que nous nous faisons de ses capacités de compréhension (que nous estimons mauvaises). Lorsqu’une plateforme d’appel nous invite à prononcer un mot pour faire un choix, nous sommes donc souvent remplis de panique ! Pourquoi ? Parce que nous avons des anticipations négatives, nous craignons de n’être pas compris. Plus exactement, nous sommes convaincus que nous n’allons pas être compris, mais nous n’avons pas le choix donc nous nous prêtons au jeu. Nous allons donc parler plus fort, plus lentement et exagérer notre articulation. « Si vous souhaitez être mis en relation avec un conseiller, dites ‘conseiller’ » « CON-SE-ILLER ». Ça vous rappelle quelque chose ? Cette stratégie est souvent contreproductive parce qu’en sur-articulant nous modifions les caractéristiques sonores « normales » des mots que nous prononçons. Or c’est précisément sur ces caractéristiques que les logiciels de reconnaissance automatique de la parole se basent.
Comment voyez-vous l’évolution des technologies de traitement de la parole utilisées par les assistants vocaux ?
La qualité des programmes de synthèse vocale est aujourd’hui si performante que Jean-Julien Aucouturier de l’IRCAM modifie votre voix en temps réel pour la rendre plus triste ou plus gaie et il parvient de cette manière à influencer notre humeur en retour ! L’équipe de Pascal Belin à l’Institut de Neurosciences de la Timone propose un maquillage vocal en temps réel qui permet déjà, en conditions de laboratoire, de transformer votre voix pour qu’elle sonne « plus sérieux » ou « plus autoritaire » ou « plus séduisante » ! En 2014, Spike Jones avait présenté son film « Her » dans lequel Joaquin Phoenix tombait amoureux de la voix de son ordinateur. L’ordinateur était incarné par Scarlett Johansson. Nul doute qu’il est aujourd’hui possible qu’un ordinateur puisse à son tour incarner la voix de Scarlett Johansson puisque Nicolas Obin de l’IRCAM est capable de faire dire à la voix d’André Dussolier un texte que l’acteur n’a jamais prononcé ou de refaire parler le maréchal Pétain lors de son procès. Au-delà de produire de la parole, les ordinateurs sont donc capable d’incarner un individu.
En parallèle, les technologies de reconnaissance et de synthèse vocale avancent à une vitesse hallucinante. Parce qu’elles sont de plus en plus aptes à prendre en compte les variations individuelles et contextuelles, les imprécisions et même les erreurs de la parole humaine, les machines comprennent de mieux en mieux ce que nous disons. Ce qui nous semblait hier encore relever de la science-fiction devient aujourd’hui non seulement possible mais même tout à fait banal. Tous les soirs je demande oralement à mon téléphone de régler mon réveil pour demain. Non seulement il le fait sans jamais se tromper, mais en plus il me confirme oralement que tout est bien programmé. Il reçoit le message, il le comprend, il effectue la tâche et il apporte une réponse adaptée. Et on trouve ça normal !

Joana Revis
Joana Revis est orthophoniste-vocologiste et maître de conférences associé à la faculté de médecine Aix Marseille Université.
Pour aller plus loin
- [Joana Revis] “La voix et soi : Ce que notre voix dit de nous”, Éditions DeBoeck, Octobre 2013.
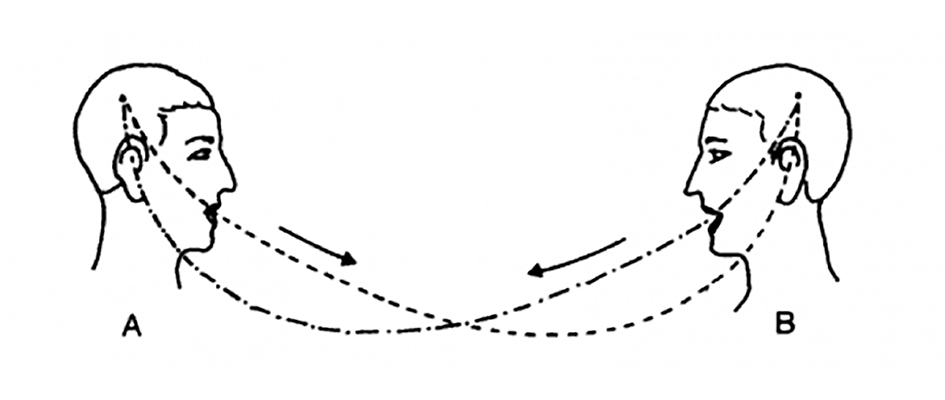
Illustration : tirée de l’ouvrage Cours de linguistique générale, Ferdinand de Saussure, (1916)